| - MDN Web Docs <https://developer.mozilla.org/ko/docs/Web/Performance/How_browsers_work> 이 글은 MDN contributors 에 의해 작성된 포스트를 재사용한 것으로 Creative Commons Attribution-ShareAlike 4.0 International License 를 근거로 MDN 문서를 재가공한 것입니다. 정확한 내용은 공식문서를 참고하세요.- |
이 포스트는..
이번에 AWS EC2 를 사용하여 사이트 배포를 진행해보면서 브라우저의 동작원리에 대해서 많은 궁금증이 생겼는데, 이에 대한 문서가 MDN 에 있어서 이를 정리해 보았습니다.
웹페이지를 표시한다는 것: 브라우저는 어떻게 동작하는가
사용자는 로드가 빠르고 상호작용이 원활한 컨텐츠로 이루어진 웹 경험을 원합니다. 따라서 개발자는 이 두 가지 목표를 달성하기 위해서 부단히 노력해야합니다. 실제 성능 및 체감되는 성능을 향상시키는 방법을 이해하기 위해서 브라우저가 어떻게 동작하는지 이해하는 것이 도움이 됩니다.
개요
빠른 사이트는 더 좋은 사용자 경험을 제공합니다. 사용자는 로드가 빠르고 상호작용이 원활한 컨텐츠로 이루어진 웹 경험을 원합니다. 웹 성능에 있어서 두 가지 주요한 문제는 지연시간과 브라우저가 대부분 싱글 쓰레드로 동작한다는 점입니다.
빠른 로딩을 하는데 있어서 지연시간은 이겨내야할 중요한 문제입니다. 빠른 로딩을 위해 신경써야할 것에는 최대한 빠르게 요청하는 것(적어도 체감 상 매우 빠른 수준으로 보내기)도 포함됩니다.
네트워크 지연시간은 네트워크를 통해 컴퓨터로 바이트를 전송하는데 걸리는 시간을 의미합니다. 웹 최적화는 페이지 로드가 최대한 빠르게 이루어 질 수 있도록 하는 것입니다.
대부분 브라우저는 싱글 쓰레드입니다. 원활한 상호작용을 위한 개발자의 목표는 부드러운 스크롤부터 매우 기민하게 반응하는 터치에 이르기까지 성능이 뛰어난 상호 작용을 보장하는 것입니다. 메인 쓰레드가 요청된 모든 작업을 수행하면서도 유저와의 상호작용에 반응 할 수 있도록 보장하기 위해서는 렌더링 시간이 가장 중요합니다. 브라우저가 싱글 쓰레드로 동작한다는 점을 이해하고 가능한 메인 쓰레드의 책임을 줄여주는 방식으로 웹 성능 향상을 이룰 수 있습니다. 이렇게 하면 렌더링은 부드럽고 상호작용에 대한 응답은 즉각적일 것입니다.
탐색(Navigation)
탐색(Navigation)은 웹페이지를 로딩하는 첫 단계입니다. 사용자가 주소창에 URL을 입력하거나, 링크를 클릭하고, 폼(form)을 제출하는 등의 동작을 통해 요청을 보낼 때마다 발생합니다.
웹 최적화의 목표 중 하나는 탐색이 완료될 때까지의 시간을 최소화 하는 것입니다. 이상적인 조건에서 그다지 오래 걸리는 작업이 아니지만 지연시간과 대역폭은 지연을 일으키는 적입니다.
1) DNS 조회(DNS Lookup)
웹 페이지를 탐색하는 첫 단계는 해당 페이지의 자원이 어디에 위치하는지 찾는 것입니다.
- 만약 https://example.com를 탐색한다면 HTML 페이지는 IP 주소가 93.184.216.34인 서버에 위치 합니다. 해당 사이트를 한 번도 방문한 적이 없다면 DNS 조회가 필요 합니다.
- 브라우저는 DNS 조회를 요청합니다. 이는 최종적으로 도메인 서버에 의해서 처리되고, IP 주소로 응답합니다.
- 최초의 DNS 요청 이후 브라우저는 DNS를 일정 기간 캐시 합니다. 즉, 도메인 서버에 재요청하는 대신 캐시 된 IP 주소를 검색해서 이후 반복 요청에 대한 속도를 높입니다.
- DNS 조회는 보통 호스트 도메인 하나당 한 번만 수행됩니다. 하지만 DNS 조회는 요청된 페이지에서 참조하는 다른 호스트 도메인에 대해서는 별도로 각각 수행해야 합니다.
| info |
| 예를 들어, 글꼴, 이미지, 스크립트, 광고 등이 서로 다른 호스트 도메인을 가지고 있다면, DNS 조회는 각각에 대해 모두 수행합니다. |
이는 특히 모바일 네트워크 환경에서 성능에 문제가 될 수 있습니다. 사용자가 모바일 환경에 있을 때, 각각의 DNS 조회는 휴대폰에서 셀 타워에 가야하고, 셀 타워에서 권위 있는 DNS 서버에 도달해야합니다. 휴대폰과 셀 타워, 그리고 도메인 서버의 거리에 따라서 상당한 지연시간이 생길 수도 있습니다.
Q. 도메인이란 무엇인가요?
도메인은 인터넷 주소를 의미합니다. 예를 들어, "naver.com"은 네이버 웹사이트의 도메인입니다. 도메인은 인터넷을 사용하는 사람이 웹사이트를 쉽게 기억하고 입력할 수 있도록 하기 위해 사용됩니다.
도메인은 크게 2가지로 나눌 수 있습니다.
- 최상위 도메인(TLD): 도메인의 가장 마지막 부분을 의미합니다. 예를 들어, "com", "net", "org", "kr" 등이 최상위 도메인입니다.
- 제2 도메인(SLD): 도메인의 두 번째 부분을 의미합니다. 예를 들어, "naver"는 "naver.com"의 제2 도메인입니다.
도메인은 인터넷 사업자가 등록하고 관리합니다. 인터넷 사업자가 도메인을 등록하면, 해당 도메인을 사용하는 웹사이트는 인터넷에서 접근할 수 있습니다.
도메인은 웹사이트의 중요한 요소 중 하나입니다. 도메인이 잘 지정되어 있으면, 사용자는 웹사이트를 쉽게 기억하고 입력할 수 있습니다. 또한, 도메인은 웹사이트의 브랜드 이미지를 형성하는 데에도 중요한 역할을 합니다.
도메인을 등록할 때는 다음과 같은 사항을 고려하는 것이 좋습니다.
- 기억하기 쉬운 도메인을 선택하세요.
- 웹사이트의 브랜드 이미지와 어울리는 도메인을 선택하세요.
- 유사한 도메인이 등록되어 있지 않은지 확인하세요.
도메인은 웹사이트를 운영하는 데 필수적인 요소입니다. 따라서 웹사이트를 운영하려는 경우, 도메인을 등록하는 것이 중요합니다.
2) TCP 핸드셰이크(TCP Handshake)
IP 주소를 알고난 후에는, 브라우저는 서버와 TCP 3-way 핸드셰이크를 통해 연결을 설정합니다. 이 방식은 데이터를 전송하기 전에 (주로HTTPS를 통해서) 통신하려는 두 주체(이 경우에는 브라우저와 웹 서버)가 TCP 소켓 연결을 위한 매개변수를 주고 받을 수 있도록 만들어졌습니다.
TCP의 3방향 핸드셰이크 기술은 "SYN-SYN-ACK" (더 정확히는 SYN, SYN-ACK, ACK)로 불리기도 합니다. 두 컴퓨터 간 TCP 세션을 협상하고 시작하기 위해서 TCP가 3개의 메세지를 전달하기 때문입니다. 이는 요청이 보내지기 전에 3개의 추가적인 메세지가 컴퓨터 사이에 주고받아진다는 의미입니다.
3) TLS 협상(TLS Negotiation)
HTTPS를 이용한 보안성있는 연결을 위해서는 또 다른 "핸드셰이크"가 필요합니다. (TLS협상이라고 할 수 있는) 이 핸드셰이크는 통신 암호화에 쓰일 암호를 결정하고, 서버를 확인하고, 실제 데이터 전송 전에 안전한 연결이 이루어지도록 합니다. 이를 위해서 자원에 대한 실제 요청 전에 클라이언트에서 서버로 3번 더 왕복해야합니다.
연결에 보안성을 더하는 것은 페이지 로딩을 더디게 합니다. 하지만 보안성있는 연결은 지연시간이라는 비용을 낼만큼 충분히 가치가 있습니다. 브라우저와 웹서버 사이에 전송되는 데이터가 제 3자에 의해서 해독될 수 없게 되기 때문입니다. 8번의 왕복이 있은 후에, 브라우저는 마침내 요청을 할 수 있습니다.
응답(Response)
웹서버로 한 번 연결이 성립되고 나면, 브라우저는 유저 대신에 초기 HTTP GET request를 보냅니다. 웹사이트는 대게 HTML 파일을 요청합니다. 서버가 요청을 받으면, 관련 응답 헤더와 함께 HTML의 내용을 응답하게 됩니다.
<!doctype html>
<html>
<head>
<meta charset="UTF-8"/>
<title>My simple page</title>
<link rel="stylesheet"src="styles.css"/>
<script src="myscript.js"></script>
</head>
<body>
<h1 class="heading">My Page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="myimage.jpg"alt="image description"/>
</div>
<script src="anotherscript.js"></script>
</body>
</html>
이 초기 요청에 대한 응답은 수신된 첫 바이트 데이터를 포함하고 있습니다.Time to First Byte(TTFB)는 사용자가 (링크를 클릭하는 등의 방식으로) 요청을 보내고 HTML의 첫 패킷을 받는데 걸린 시간입니다.
| 첫 번째 컨텐츠 청크는 일반적으로 14kb 크기의 데이터입니다. |
참고) TTFB (Time to First Byte): 사용자가 요청을 보내고 HTML 의 첫 패킷을 받는데 걸린 시간
위 예제에서, 요청은 확실히 14kb보다 작습니다. 하지만 아래에서 설명하는 것처럼 구문 분석되는 중에 브라우저가 링크를 만날 때까지 링크가 걸린 자원들은 요청되지 않습니다.
1) TCP 슬로우 스타트 (TCP Slow Start) / 첫 응답 패킷 14KB 규칙
[] 슬로우 스타트 | 첫 응답 패킷을 14kb 로 지정하여 최대 대역폭 알기 까지 매 응답 마다 그 두 배로 전송
첫 응답 패킷은 14kb입니다. 이는 네트워크 통신의 속도를 조절하는 알고리즘인 TCP 슬로우 스타트에 의해 정해진 것입니다. 슬로우 스타트는 네트워크의 최대 대역폭을 파악할 수 있을 때까지 점진적으로 데이터의 전송량을 증가시킵니다.
TCP 슬로우 스타트방식에 따라, 첫 패킷(14kb)을 받고난 이후에 서버는 다음 패킷의 사이즈를 두 배인 28kb로 늘립니다. 뒤 이은 패킷의 크기도 미리 정의한 임계치에 다다르거나, 혼잡의 징후가 나타나기 전까지 2배씩 커집니다.
첫 페이지의 로딩에 관련해서 14kb 법칙을 들어본적이 있나요? 초기 응답의 크기가 14kb인 이유는 TCP 슬로우 스타트 때문입니다. 그리고 웹 최적화를 할 때 초기 14kb 응답을 염두해야하는 것도 이 때문입니다. TCP 슬로우 스타트는 혼잡을 피하기 위해서 네트워크의 용량에 적당한 전송 속도를 찾고자 점진적으로 속도를 높여나갑니다.
2) 혼잡 제어(Congestion control)
서버가 TCP 패킷으로 데이터를 보내면, 사용자의 클라이언트는 확인 응답(acknowledgements, ACKs)을 보내면서 데이터의 수신을 확인해줍니다. 연결은 하드웨어나 네트워크 상태에 따라서 제한된 용량만을 가지고 있습니다.
만약 서버가 패킷을 너무 빠르게 보내게 되면, 그 패킷들은 무시될 것입니다. 즉 확인 응답이 없을 것입니다. 서버는 이를 누락된 확인 응답으로 파악합니다.
혼잡 제어 알고리즘은 보내진 패킷의 흐름과 확인 응답을 바탕으로 전송 속도를 결정합니다.
구문 분석(Parsing) | 네트워크를 통해 받은 데이터를 DOM, CCSOM으로 바꾸는 단계
브라우저가 첫 번째 데이터의 청크를 받으면, 수신된 정보를 구문 분석하기 시작합니다.구문 분석은 브라우저가 네트워크를 통해 받은 데이터를 DOM 이나 CSSOM 으로 바꾸는 단계입니다. 이는 렌더러가 화면에 페이지를 그리는데 사용됩니다.
| ! 정리 |
| 구분 분석 : 네트워크를 통해 받은 데이터를 DOM 이나 CSSOM 으로 바꾸는 단계 |
브라우저는 마크업을 내부적으로 DOM으로 표현합니다. DOM은 공개되어있고 Javascript의 다양한 API를 통해 조작할 수 있습니다.
요청된 HTML 페이지의 크기가 초기 패킷의 크기인 14kb 보다 크더라도, 브라우저는 구문 분석을 시작하고 가지고 있는 데이터 수준에서 렌더링을 시도합니다.
이것이 웹 성능 최적화에서 브라우저가 페이지를 렌더링 하는데 필요한 모든 것, 아니면 적어도 페이지의 템플릿(첫 렌더링에 필요한 HTML이나 CSS)만이라도 첫 14kb에 포함해야하는 이유입니다. 하지만 화면에 렌더링하기 전에 HTML, CSS, Javascript를 구문 분석해야 합니다.
중요한 렌더링 경로를 다섯 가지 단계로 설명합니다.
1) DOM 트리 구축(Building the DOM tree)
첫 단계는 HTML을 처리하여 DOM 트리를 만드는 것입니다. HTML 구문 분석은 토큰화와 트리 생성을 포함합니다. HTML 토큰은 시작 및 종료 태그 그리고 속성 이름 및 값을 포함합니다. 만약 문서가 잘 구성되어 있다면 구문 분석은 명확하고 빠르게 이루어집니다. 구문 분석기는 토큰화된 입력을 분석하여 DOM 트리를 만듭니다.
DOM 트리는 문서의 내용을 설명합니다. html요소는 시작하는 태그이고 DOM 트리의 루트 노드입니다. 트리는 다른 태그간의 관계와 계층을 반영합니다. 다른 태그에 감싸져 있는 태그는 자식 노드입니다. DOM 노드의 개수가 많아질수록, DOM 트리를 만드는데 더 오랜 시간이 걸립니다.
| ! 정리 |
| DOM 노드 개수가 많아질수록 DOM 트리 생성이 오래 걸림(불필요한 HTML 요소를 중첩하거나 포함시키지 말아야 하는 이유) |
구문 분석기가 이미지와 같은 논 블로킹 자원을 발견하면, 브라우저는 해당 자원을 요청하고 분석을 계속합니다. 구문 분석은 CSS 파일을 만났을 때도 지속될 수 있습니다. 하지만 async 나 defer같은 설정이 되어있지 않은<script>태그는 렌더링을 막고, HTML의 분석을 중지시킵니다. 브라우저의 프리로드 스캐너가 이 작업을 가속화하지만, 과도한 스크립트는 여전히 주요한 병목구간이 될 수 있습니다.
| ! 정리 |
| 구문 분석은 이미지와 같은 논 블로킹 자원이나 CSS 파일을 만나더라도 지속될 수 있으나, async 나 defer 속성이 없는 스크립트를 만나면 HTML 분석을 중지시킨다. 이를 완화하는 기능이 프리로드 스캐너 이지만, 과도한 스크립트의 사용으로 인한 병목구간 문제는 여전히 주요 문제가 된다. |
2) 프리로드 스캐너(Preload scanner) | 외부 자원을 미리 요청하여 받아옴
브라우저가 DOM 트리를 만드는 프로세스는 메인 쓰레드를 차지합니다. 그렇기 때문에, 프리로드(preload) 스캐너는 사용 가능한 컨텐츠를 분석하고 CSS나 Javscript, 웹 폰트 같이 우선순위가 높은 자원을 요청합니다. 프리로드 스캐너 덕에 구문 분석기가 외부 자원에 대한 참조를 찾아 요청하기까지 기다리지 않아도 됩니다. 프리로드 스캐너가 자원을 뒤에서 미리 요청합니다. 그래서 구문 분석기가 요청되는 자원에 다다를 때 쯤이면 이미 그 자원들을 전송받고 있거나 이미 전송받은 후일 것입니다. 프리로드 스캐너가 제공하는 최적화는 블록킹을 줄여줍니다.
<link rel="stylesheet"src="styles.css"/>
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description"/>
<script src="anotherscript.js" async></script>
이 예제에서 메인 쓰레드가 HTML과 CSS를 분석하고 있을 때, 프리로드 스캐너는 스크립트와 이미지를 찾아 다운로드하기 시작할 것입니다. Javascript의 분석과 실행 순서가 중요하지 않고 스크립트가 프로세스를 막지 않도록 하려면 async 속성 이나 defer 속성을 추가하세요.
CSS를 다운로드하는 것은 HTML 분석이나 다운로드를 막지 않습니다. 하지만 Javascript의 실행은 막습니다. Javascript는 종종 요소에 영향을 주는 CSS 속성들을 조작하기 떄문입니다.
3) CSSOM 구축(Building the CSSOM)
중요한 렌더링 경로에서 두 번째 단계는 CSS를 처리하고 CSSOM 트리를 만드는 것입니다. CSS 객체 모델은 DOM과 비슷합니다. DOM과 CSSOM은 둘 다 트리구조입니다. 둘은 각각의 독립적인 자료구조 입니다. 브라우저는 CSS 규칙을 이해할 수 있고 작업을 진행할 수 있도록 스타일 맵으로 변환합니다. 브라우저는 CSS에 있는 각각의 규칙을 읽고, 트리 노드를 만듭니다. CSS 선택기에 기반해서 부모 노드, 자식 노드, 형제 관계의 노드를 만들어집니다.
HTML이 그러한 것처럼, 브라우저는 전송받은 CSS 규칙을 작업 가능한 상태로 변환해야합니다. 따라서 브라우저는 HTML을 객체로 바꾼 프로세스를 CSS에 대해서 다시 한 번 합니다.
CSSOM 트리는 사용자 에이전트의 스타일 시트를 포함합니다. 브라우저는 노드에 적용 가능한 가장 일반적인 규칙부터 적용합니다. 그리고 재귀적으로 더 구체적으로 적용된 규칙에 따라 계산된 스타일을 수정해갑니다. 다른 말로, 속성 값을 캐스케이드합니다.
| info CSS 에서 C 가 캐스케이드인 이유 |
| - 스타일을 쉽게 재사용할 수 있습니다. 부모 요소의 스타일을 자식 요소에 상속함으로써, 스타일을 일일이 지정하지 않고도 웹 페이지의 일관된 스타일을 유지할 수 있습니다. - 스타일을 보다 유연하게 제어할 수 있습니다. 상속을 통해 스타일을 기본값으로 설정하고, 개별 요소에 대한 스타일을 지정하여 보다 세밀한 스타일을 제어할 수 있습니다. |
CSSOM을 만드는 것은 매우 매우 빠르고 현재 개발자 도구에서 고유한 색으로 표시되지 않습니다. 개발자 도구에서 "스타일 재계산"에는 CSS를 구문 분석하고, CSSOM 트리를 만들고, 계산된 스타일을 재귀적으로 계산하는데 드는 총 시간이 표시됩니다.
CSSOM을 만드는데 드는 시간은 일반적으로 한 번의 DNS 조회를 하는 시간보다 짧기 때문에 웹 성능 최적화의 관점에서 CSSOM는 성능 향상에 큰 기여를 할 수 있는 영역은 아닙니다.
4) 다른 작업들(Other Processes)
[1] Javascript 컴파일(JavaScript Compilation)
CSS가 분석되고 CSSOM이 생성되는 동안, 프리 스캐너 덕에 Javascript 파일 같은 다른 자원도 다운로드 됩니다. Javascript는 해석, 컴파일, 구문 분석 및 실행됩니다. 스크립트는 추상 구문 트리(AST)로 구문 분석됩니다. 일부 브라우저 엔진은 추상 구문 트리를 인터프리터에게 넘깁니다. 그 결과 메인 쓰레드에서 실행되는 바이트코드가 생성됩니다. 이것이 Javascript 컴파일 과정입니다.
참고) 추상구문트리란? 프로그래밍 언어의 소스 코드를 표현하는 트리형의 자료구조(각 노드: 소스코드 구성요소)
추상 구문 트리(AST)는 프로그래밍 언어의 소스 코드를 표현하는 자료 구조입니다. 일반적으로 트리 구조로 표현되며, 각 노드는 소스 코드의 한 구성 요소를 나타냅니다.
추상 구문 트리 예
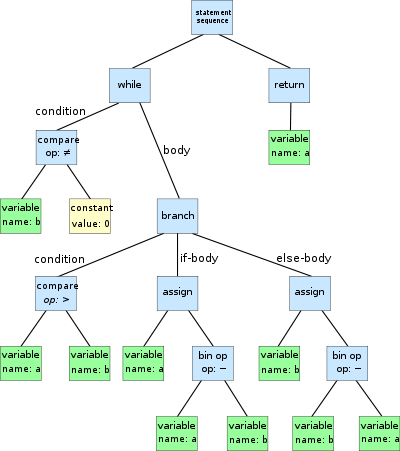
위의 예에서, "main" 함수는 루트 노드로 나타납니다. "main" 함수의 하위 노드는 함수의 인수, 지역 변수 및 코드 블록을 나타냅니다.
AST는 다음과 같은 용도로 사용될 수 있습니다.
- 컴파일러: 컴파일러는 소스 코드를 기계어로 번역하기 전에 AST를 생성합니다. AST는 컴파일러가 소스 코드의 구조를 이해하고, 코드의 의미를 분석하고, 오류를 검사하는 데 도움이 됩니다.
- 디버거: 디버거는 소스 코드를 디버깅할 때 AST를 사용합니다. AST는 디버거가 소스 코드의 구조를 시각적으로 표시하고, 코드의 실행 흐름을 추적하고, 오류의 원인을 식별하는 데 도움이 됩니다.
- 리팩토링 도구: 리팩토링 도구는 소스 코드를 리팩토링할 때 AST를 사용합니다. AST는 리팩토링 도구가 소스 코드의 구조를 변경하고, 코드의 의미를 유지하는 데 도움이 됩니다.
[2] 접근성 트리 구축(Building the Accessibility Tree)
브라우저는 접근성트리를 만듭니다. 보조 장치는 이 트리를 이용해 내용을 분석하고 해석합니다. 접근성 객체 모델(AOM)은 DOM의 의미 버전입니다. 브라우저는 DOM이 업데이트 될 때 접근성 트리도 업데이트 합니다. 접근성 트리는 보조 기술 자체적으로 수정될 수는 없습니다.
AOM이 만들어지기 전까지, 화면 리더기는 컨텐츠에 접근할 수 없습니다.
렌더(Render)
렌더링 과정에는 스타일, 레이아웃, 페인트 그리고 때때로 합성이 포함됩니다. CSSOM과 DOM 트리는 구문 분석되는 과정에서 생성되고 렌더 트리로 합성됩니다.
렌더 트리는 보이는 요소의 레이아웃을 계산을 합니다. 그러고 나서 요소가 화면에 페인트됩니다. 어떤 경우에는 컨텐츠가 자신만의 레이어를 가지도록 조작되고, 나중에 합성됩니다. 화면의 일부분을 CPU 대신 GPU가 그리면서 메인 쓰레드의 부담이 줄고 성능이 향상됩니다.
1) 스타일(Style)
중요한 렌더링 경로에서 세 번째 단계는 DOM과 CSSOM을 합쳐 렌더 트리를 만드는 것입니다. 계산된 스타일 트리(다른 말로 렌더 트리)는 DOM 트리의 루트부터 시작하여 눈에 보이는 노드를 순회하며 만들어집니다.
<head>와 그 자식 요소 혹은 사용자 정의 스타일 시트에 정의된 script { display: none; } 처럼 display: none스타일 속성을 가진 요소와 같이, 화면에 나타나지 않는 태그의 경우 렌더링 결과에 나타나지 않을 것이기 때문에 렌터 트리에 포함되지 않습니다. visibility: hidden속성을 가진 요소는 자리를 차지하기 때문에 렌더 트리에 포함됩니다. 코드 예시에서 사용자 에이전트가 기본으로 설정한 값을 오버라이드하는 정의를 하지 않았기 때문에, script노드는 렌더 트리에 포함되지 않을 것입니다.
참고) 사용자 에이전트? script 노드?
사용자 에이전트는 브라우저를 의미합니다. 브라우저는 웹 페이지를 렌더링하기 위해 렌더 트리를 생성합니다. 렌더 트리는 화면에 표시될 노드들의 집합입니다.
script 노드는 자바스크립트 코드를 포함하는 요소입니다. 일반적으로 script노드는 기본적으로 화면에 표시되지 않습니다. 즉, 렌더 트리에 포함되지 않습니다. 단, 예외는 존재합니다.
만일, 렌더 트리에 포함되기 위해서는, script노드의 display 속성을 "block" 또는 "inline"으로 설정해야 합니다.
예를 들어, 다음과 같은 HTML 코드를 작성했다고 가정해 보겠습니다.
<script display="none">
// 자바스크립트 코드
</script>
이 코드의 경우, script노드의 display 속성은 기본값인 "none"입니다. 따라서, 이 script노드는 렌더 트리에 포함되지 않습니다.
위의 코드에서 다음과 같이 display 속성을 설정하면, script노드가 렌더 트리에 포함됩니다.
<script display="block">
// 자바스크립트 코드
</script>
스크립트 태그에 직접 바인딩하지 않고, 다음과 같이 CSS를 사용하여 display 속성을 오버라이드하면, script노드가 렌더 트리에 포함됩니다.
script {
display: block;
}
각각의 보이는 노드는 그 노드에 적용된 CSSOM 규칙이 있습니다. 렌더 트리가 보이는 모든 노드의 내용과 계산된 스타일을 가지고 있습니다. DOM 트리에서 보이는 모든 노드에 관련된 스타일을 모두 맞춰보고, CSS 캐스케이드 방식에 따라서 각 노드의 계산된 스타일이 무엇일지 결정합니다.
2) 레이아웃(Layout) “처음 노드의 사이즈와 위치가 결정 되는 프로세스“
중요한 렌더링 과정에서 네 번째 단계는 렌더 트리를 기반으로 각 노드의 도형 값을 계산하기 위해 레이아웃을 실행하는 것입니다. 레이아웃은 렌더 트리에 있는 모든 노드의 너비, 높이, 위치를 결정하는 프로세스입니다. 추가로 페이지에서 각 객체의 크기와 위치를 계산합니다.
리플로우는 레이아웃 이후에 있는 페이지의 일부분이나 전체 문서에 대한 크기나 위치에 대한 결정입니다.
렌더 트리가 한 번 만들어지고 나면, 레이아웃이 시작됩니다. 렌더 트리는 (보이지 않더라도) 계산된 스타일과 함께 어떤 노드가 화면에 표시될지 식별합니다.
하지만 렌더 트리는 각 노드의 위치나 좌표를 알지는 못합니다. 각 객체의 정확한 크기와 위치를 결정하기 위해서, 브라우저는 렌더 트리의 루트부터 시작하여 순회합니다.
웹 페이지에서 대부분은 박스 형태입니다. 다른 기기, 다른 데스크탑 설정은 제한 없이 매우 다양한 뷰 포트 크기를 가집니다. 레이아웃 단계에서 뷰 포트의 크기를 고려합니다. 브라우저는 화면에 표시될 모든 다른 상자의 크기를 결정합니다.
뷰 포트의 크기를 기본으로하며, 레이아웃은 일반적으로 본문에서 시작해 모든 후손의 크기를 각 요소의 박스 모델 속성을 통해 계산합니다. 이미지와 같이 크기를 모르는 요소를 위해서 위치 표시 공간을 남겨둡니다.
| 참고) 박스모델 속성은 브라우저 개발자 도구에서 요소를 검사 시 하단에서 확인할 수 있습니다. |
처음 노드의 사이즈와 위치가 결정되는 것을 레이아웃 이라고 부릅니다. 이후에 노드의 크기와 위치를 다시 계산하는 것은 리플로우 라고 부릅니다.
첫 레이아웃이 이미지가 오기 전에 일어난다고 가정을 해봅시다. 이미지의 크기를 선언하지 않았기 때문에, 이미지 크기를 알게 된 이후 리플로우가 한 번 있을 것입니다(→ img 속성에서 width 와 height를 지정해야 하는 이유라고 할 수 있을 듯).
3) 페인트(Paint)
중요한 렌더링 경로에서 마지막 단계는 각 노드를 화면에 페인팅하는 것입니다. 페인팅이 처음 일어나는 것을 첫 번째 의미있는 페인트(FCP)라고 부릅니다. 페인팅 혹은 레지스터화 단계에서, 브라우저는 레이아웃 단계에서 계산된 각 박스를 실제 화면의 픽셀로 변환합니다.
페인팅에서 텍스트, 색깔, 경계, 그림자 및 버튼이나 이미지 같은 대체 요소를 포함하여 모든 요소의 시각적인 부분을 화면에 그리는 작업이 포함됩니다. 브라우저는 이 작업을 매우 빠르게 해야합니다.
부드러운 스크롤이나 애니메이션을 위해서, 스타일 계산, 리플로우, 페인팅과 같이 메인 쓰레드를 점유하는 모든 작업은 브라우저를 16.67ms 미만만 차지해야만 합니다.
2048 X 1536 화면에서 iPad는 화면에 페인트해야 할 3,145,000 픽셀을 가지고 있습니다. 이는 매우 많은 픽셀이며, 이 픽셀은 매우 빠르게 페인팅되어야 합니다. 첫 페인팅보다 다시 페인팅하는 것이 더 빠르게 마무리되기 위해서, 화면에 그리는 작업은 일반적으로 몇 개의 레이어로 구분됩니다. 이것이 일어나면 합성이 필요합니다.
페인팅은 레이아웃 트리의 요소를 레이어로 분리할 수 있습니다. 컨텐츠를 CPU의 메인 쓰레드에서 GPU 레이어로 격상하는 것은 페인트 및 리페인트 성능을 높입니다.
레이어를 가동시키는 구체적인 속성과 요소가 있습니다. 요소에는 <video> 그리고 <canvas> 가 포함되어 있습니다. 구체적인 속성에는 opacity, 3Dtransform,will-change등이 있습니다. 자손 노드가 위의 이유 중 하나(혹은 여러 개)로 자신만의 레이어를 필요로 하는 것이 아니라면, 이 노드는 그들의 레이어에서 그들의 자손과 함께 그려집니다.
레이어는 성능을 향상시킵니다. 하지만 메모리 관리 측면에서 봤을 때는 비싼 작업입니다. 따라서 웹 성능 최적화 전략으로 과도하게 쓰이지는 않아야 합니다.
4) 합성(Compositing)
문서의 각 섹션이 다른 레이어에서 그려질 때, 섹션을 겹쳐놓으면서 그것들이 올바른 순서로 화면에 그려지는 것과 정확한 렌더링을 보장하기 위해 합성이 필요합니다.
페이지가 계속해서 자원을 로드하면, 리플로우가 일어날 수 있습니다(이미지가 늦게 도착하는 것을 떠올려보세요). 리플로우는 리페인트와 재합성을 일으킬 수 있습니다. 이미지의 사이즈를 미리 정해놨다면 리플로우는 필요하지 않을 것입니다. 그리고 리페인트 되야할 레이어만 다시 리페인트 하고 필요하다면 합성할 것입니다.
상호작용(Interactivity)
메인 쓰레드가 페이지를 그리는 것을 완료하면, 모든 것이 준비되었다고 생각할 수도 있습니다. 하지만 꼭 그렇지는 않습니다. 만약 지연된 Javascript를 다운했다면, 그리고 onload이벤트가 발생할 때 코드가 실행된다면, 메인 쓰레드는 여전히 바쁠 것입니다. 그래서 스크롤링, 터치 등 다른 상호작용이 불가능 할 것입니다.
Time to Interactive(TTI) 는 DNS 조회와 SSL 연결이 이루어지는 첫 요청부터 페이지가 상호작용할 준비가 될 때까지 얼마나 걸리는지를 측정하는 단위입니다.
첫 번째 콘텐츠가 포함된 페인트(FCP)이후 페이지가 사용자와의 상호작용에 50ms 이내로 응답할 때를 상호작용 가능한 시점으로 봅니다.
만약 메인 쓰레드가 구문 분석, 컴파일, Javascript 실행에 사용되고 있다면, 메인 쓰레드를 사용할 수 없고 따라서 사용자 상호작용에 50ms 이내로 적절하게 반응하지 못합니다.
예제에서, 이미지는 매우 빠르게 로드됩니다. 하지만 만약 anotherscript.js파일이 2MB였고 사용자의 네트워크 연결이 느렸다면 어땠을까요? 이 경우에는 사용자는 페이지는 매우 빠르게 볼 수 있지만 스크립트가 다운로드되고, 분석되고 실행되기 전까지는 버벅이는 스크롤을 할 수 밖에 없을 것입니다. 이는 좋은 사용자 경험이 아닙니다. WebPageTest 예시에서 볼 수 있듯이, 메인 쓰레드를 점유하는 것을 피하세요.
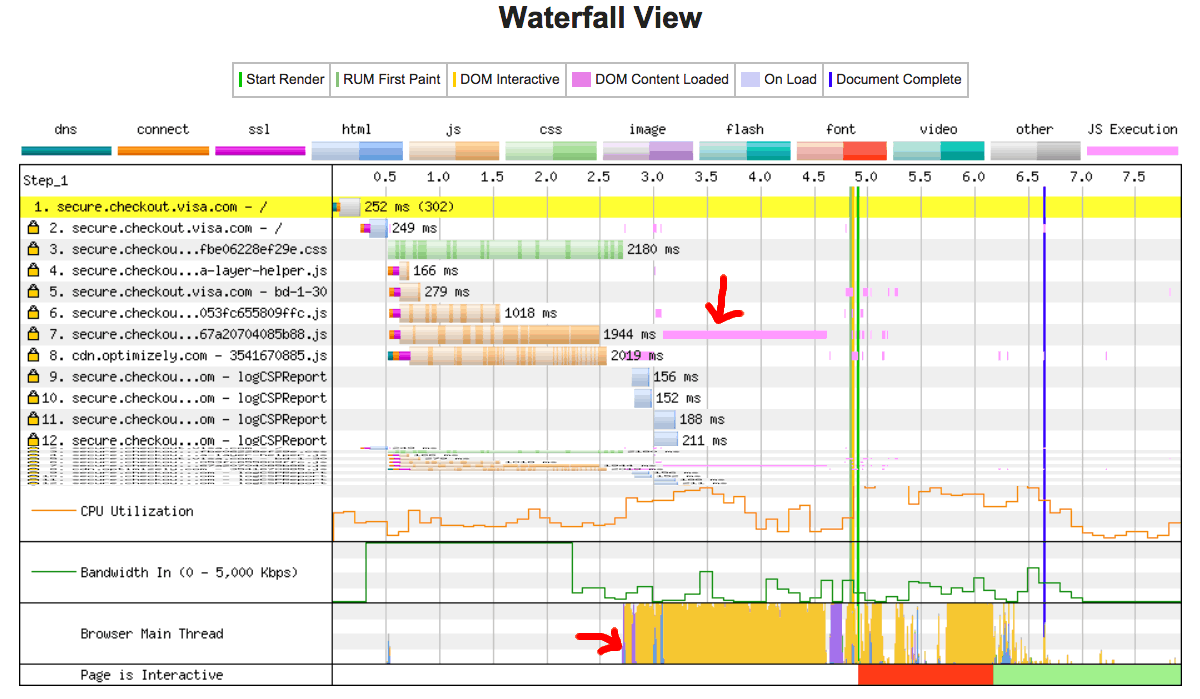
이 예시에서, DOM 컨텐츠를 로드하는 프로세스는 1.5초 이상 걸렸습니다. 그리고 클릭이나 화면 탭에 응답하지 못하는 상태로 메인 쓰레드는 그 전체 시간동안 점유되었습니다.
포스팅 후기
MDN 에 있는 글을 가져온 것이므로 포스팅이라고 하기에는 뭐 하지만, 브라우저 렌더링 과정에서 메인 스레드의 점유률을 낮춰야 하는 근본적인 이유에 대해서 알아보는 시간이었던 것 같습니다.특히 프리로드 스캐너가 존재해서 스크립트 태그가 구문분석기와 만나기 전에 미리 자원에 대한 로드 요청을 보낸다는 것을 새롭게 알게 되었고, 여러모로 배울게 많은 시간이었던 것 같네요. 정말 좋은 자료들이 MDN 에 많이 올라와 있는데, 자주 참고해서 읽어보면 좋을 것 같습니다.
'자바스크립트' 카테고리의 다른 글
| [JS] Array.from 의 두번째 인자는 map 과 유사한 함수다. (0) | 2024.05.12 |
|---|---|
| 실행 컨텍스트(execution context) 를 다시보자 (0) | 2024.03.27 |
| [JS] 흔히 블로그에서 자동으로 생성되는 목차는 어떻게 만드는 걸까? (3) | 2024.03.10 |
| [javascript] HTML5 Web Speech API 로 TTS 만들기 (0) | 2024.01.15 |
| [javascript] 3d 스틸 박스 (작성중) (0) | 2024.01.11 |

