오늘의 명언

| 예제 코드가 있다면 자바스크립트/타입스크립트 기준으로 작성되어 있습니다. |
시스템
콜드 스타트 | 데이터가 부족하여 프로그램이 목적을 달성하지 못하는 고질적인 문제
프로그램측면에서 데이터가 없는 상태를 의미합니다. 그래서 추천시스템의 cold start는 새롭게 들어오거나 특정한 유저들의 데이터를 충분히 확보하지 못하여 유저에 적합한 추천을 하지 못하는 문제 입니다.
모놀리스 아키텍처
모놀리스(Monolith) 아키텍처는 하나의 소프트웨어를 구성하는 모든 모듈과 코드를 한 프로젝트에서 관리하는 것을 의미합니다.
클라우드 컴퓨팅
IT 리소스를 인터넷을 통해 온디맨드로 제공하고 사용한 만큼만 비용을 지불하는 것을 의미합니다.
블로킹과 논블로킹
블로킹(Blocking) | 특정 작업 완료 까지 다음 작업을 중단하는 방식
블로킹 작업은 특정 작업이 완료될 때까지 프로그램의 실행을 중단하는 방식입니다. 즉, 어떤 작업이 완료될 때까지 그 다음 명령을 실행하지 않고 기다립니다. 블로킹 방식은 직관적이며, 단순한 프로그램에서 자주 사용됩니다.
예를 들어, 파일을 읽는 블로킹 호출을 사용하면, 파일 읽기 작업이 완료될 때까지 프로그램의 실행이 멈추게 됩니다. 그 동안 프로그램은 아무런 작업도 수행하지 않습니다.
논블로킹(Non-Blocking) | 특정 작업 완료를 기다리지 않고 다음 작업을 실행하는 방식
논블로킹 작업은 작업이 완료될 때까지 기다리지 않고, 바로 다음 명령을 실행합니다. 즉, 작업을 요청하고 바로 반환되며, 작업의 완료 여부와 관계없이 프로그램이 계속 실행됩니다. 이 방식은 비동기(Asynchronous) 프로그래밍과 함께 사용될 때가 많습니다.
예를 들어, 파일을 읽는 논블로킹 호출을 사용하면, 파일 읽기 작업을 요청한 후에 바로 다음 명령을 실행할 수 있습니다. 파일 읽기가 완료되면 콜백(callback) 함수를 호출하거나, 나중에 결과를 확인합니다.
블로킹과 논블로킹을 요리로 비유하자면
비유하자면, 블로킹 방식은 한 명의 요리사가 하나의 요리를 완성할 때까지 다른 요리를 시작하지 않는 것과 같습니다. 반면, 논블로킹 방식은 여러 명의 요리사가 각자 요리를 준비하고, 요리가 완료되면 이를 차례로 서빙하는 것과 비슷합니다.
콘텐츠 전송 네트워크 (CDN)
콘텐츠 전송 네트워크(CDN)는 지리적으로 분산된 서버 네트워크로, 사용자에게 빠르고 신뢰성 있는 콘텐츠 전송을 제공하는 데 목적을 둡니다. CDN은 웹 콘텐츠(이미지, 비디오, HTML 페이지, 스타일시트, JavaScript 파일 등)를 전송하는 방식을 최적화하여, 웹사이트 성능을 향상시키고 사용자 경험을 개선합니다.
주요 구성 요소와 동작 원리
원본 서버 (Origin Server) | 원본 콘텐츠를 저장하고 있는 서버
콘텐츠가 처음 저장되는 서버입니다. 모든 콘텐츠는 원본 서버에서 시작하여 CDN 네트워크로 배포됩니다.
캐시 서버 (Edge Server) | 원본 콘텐츠를 복사하여 사용자에게 실질적으로 콘텐츠를 제공하는 서버
CDN의 핵심 요소로, 전 세계 여러 위치에 분산되어 있습니다. 사용자에게 가장 가까운 캐시 서버가 콘텐츠를 제공함으로써 지연 시간을 최소화합니다.
POP(Point of Presence) | 캐시 서버가 위치한 데이터 센터 또는 지점
캐시 서버가 위치한 데이터 센터 또는 지점입니다. 전 세계에 분산되어 있어 사용자와의 물리적 거리를 줄입니다.
캐싱 (Caching) | 자주 요청되는 콘텐츠를 캐시 서버에 저장하는 것
자주 요청되는 콘텐츠를 캐시 서버에 저장합니다. 사용자가 요청하면 원본 서버 대신 캐시 서버에서 콘텐츠를 제공하여 응답 속도를 높입니다.
라우팅 (Routing) | 사용자가 콘텐츠 요청 시 가장 가까운 데이터 센터로 트래픽을 전송하는 기술
사용자가 콘텐츠를 요청할 때, 가장 가까운 POP으로 트래픽을 라우팅하여 최적의 성능을 제공합니다. 이는 지리적 위치, 서버 부하, 네트워크 조건 등을 고려하여 이루어집니다.
CDN의 주요 기능과 장점
속도 향상 | 캐싱된 콘텐츠를 분산된 데이터 센터의 캐시 서버(엣지 로케이션)를 통해 전달하므로 사이트 로딩 시간 단축
캐시 서버를 통해 콘텐츠를 제공함으로써 웹페이지 로딩 시간을 단축합니다. 사용자가 원본 서버 대신 가까운 POP에서 콘텐츠를 받을 수 있으므로 지연 시간이 줄어듭니다.
트래픽 부하 분산 | 원본 서버 대신 사용자와 가까운 데이터 센터의 캐시 서버로 트래픽을 분산하여 원본 서버에 가해지는 부하 분산
트래픽이 여러 캐시 서버로 분산되므로 원본 서버에 가해지는 부하가 줄어들고, 서버 과부하를 방지할 수 있습니다.
신뢰성 및 가용성 증가 | 여러 서버에 콘텐츠를 캐시하므로 문제가 발생해도 지속적으로 콘텐츠 제공이 가능
여러 서버에 콘텐츠를 분산하여 저장하므로, 특정 서버가 다운되더라도 다른 서버에서 콘텐츠를 제공할 수 있어 가용성이 높아집니다.
보안 강화
DDoS 공격을 방어하고, SSL 인증을 통해 데이터 전송을 암호화하여 보안을 강화합니다. 많은 CDN 제공업체는 추가적인 보안 기능을 제공합니다.
콘텐츠 최적화
이미지 최적화, 파일 압축, 브라우저 캐싱 등의 기술을 사용하여 콘텐츠 전달을 최적화합니다. 이는 사용자 경험을 향상시킵니다.
CDN 사용 사례
웹사이트 및 애플리케이션
전자 상거래 사이트, 뉴스 사이트, 포털 사이트 등 트래픽이 많은 웹사이트는 CDN을 통해 빠른 로딩 속도를 유지합니다.
비디오 스트리밍
Netflix, YouTube와 같은 스트리밍 서비스는 전 세계 사용자에게 원활한 스트리밍 경험을 제공하기 위해 CDN을 사용합니다.
소프트웨어 다운로드
게임 업데이트, 소프트웨어 패치 등을 전 세계 사용자에게 빠르고 안정적으로 배포하기 위해 사용됩니다.
게임
온라인 게임에서는 낮은 지연 시간과 빠른 응답 속도가 중요합니다. CDN을 사용하여 전 세계 게이머에게 원활한 게임 플레이를 제공합니다.
주요 CDN 제공업체
| Akamai | 가장 오래된 CDN 제공업체 중 하나로, 광범위한 네트워크와 다양한 보안 솔루션을 제공합니다. |
| Cloudflare | 보안 기능과 함께 CDN 서비스를 제공하며, 중소기업부터 대기업까지 널리 사용됩니다. |
| Amazon CloudFront | AWS의 CDN 서비스로, 다른 AWS 서비스와의 통합이 용이합니다. |
| Google Cloud | CDNGoogle의 글로벌 네트워크를 기반으로 빠르고 안정적인 콘텐츠 전송을 제공합니다. |
| Fastly | 실시간 콘텐츠 업데이트와 고성능 엣지 컴퓨팅 기능을 강조합니다. |
주요 기능
| 도메인 설정 | CDN 제공업체의 안내에 따라 도메인을 설정합니다. 일반적으로 DNS 설정을 통해 도메인을 CDN에 연결합니다. |
| 캐싱 정책 설정 | 어떤 콘텐츠를 캐싱할지, 캐시의 유효 기간 등을 설정합니다. 이는 CDN 제공업체의 관리 콘솔에서 설정할 수 있습니다. |
| HTTPS 및 보안 설정 | SSL 인증서를 설정하여 HTTPS를 통해 안전하게 콘텐츠를 전송합니다. 또한, DDoS 방어와 같은 추가적인 보안 설정을 적용할 수 있습니다. |
| 모니터링 및 분석 | CDN 제공업체의 대시보드를 통해 트래픽, 캐시 히트 비율, 응답 시간 등을 모니터링하고 분석하여 성능을 최적화합니다. |
libuv 라이브러리
libuv는 Node.js에서 주로 사용되는 C 라이브러리로, 주로 비동기 이벤트 기반 프로그래밍을 위해 설계되었습니다. 이 라이브러리의 주요 목표 중 하나는 Node.js의 비동기 작업 처리와 이벤트 루프 구현을 단순화하고, 다양한 플랫폼에서 일관된 동작을 보장하는 것입니다.
libuv는 다음과 같은 주요 기능을 제공합니다
이벤트 루프 (Event Loop) | 비동기 작업을 대기열에 넣고, 완료 후 콜백을 호출하여 결과 저장
Node.js 는 이벤트 기반 모델을 사용하여 작업을 비동기적으로 처리합니다. libuv는 이 이벤트 루프를 구현하는 주요 역할을 합니다. 이벤트 루프는 비동기 작업을 대기열에 넣고, 완료되면 콜백을 호출하여 결과를 처리합니다.
비동기 I/O
libuv는 비동기 입출력 (I/O) 작업을 지원하여 파일 시스템, 네트워크 및 기타 리소스에 대한 비동기 작업을 처리할 수 있도록 합니다. 이것은 Node.js가 단일 스레드에서 여러 작업을 동시에 처리할 수 있는 핵심적인 기능입니다.
이벤트 기반 프로그래밍 | 애플리케이션이 이벤트에 응답하고 처리하는 방식을 제어
libuv는 이벤트 기반 프로그래밍 모델을 구현하여 애플리케이션이 이벤트에 응답하고 처리하는 방식을 제어합니다. 이것은 비동기 작업 및 이벤트 처리를 간단하게 만들어줍니다.
네트워킹
libuv는 TCP 및 UDP 소켓을 비롯한 네트워킹 기능을 제공하여 네트워크 통신을 지원합니다. 이것은 Node.js를 사용하여 서버 및 클라이언트 애플리케이션을 작성하는 데 매우 유용합니다.
크로스 플랫폼 지원
libuv는 Windows, macOS, Linux 및 기타 주요 운영 체제에서 동작하도록 설계되었습니다. 따라서 Node.js가 다양한 플랫폼에서 일관된 동작을 보장할 수 있도록 돕습니다.
DOM(Dodument Object Model)
웹 페이지를 이루는 태그(<html/>, <body/>) 를 자바스크립트에서 접근할 수 있는 트리 형태로 만든 모델을 의미합니다.
파싱(Parsing) | 하나의 프로그램을 런타임 환경이 실제로 실행 가능한 내부 포맷으로 분석 후 변환하는 과정
하나의 프로그램을 런타임 환경이 실제로 실행할 수 있는 내부 포맷으로 분석하고 변환하는 것을 의미합니다.
하이드레이션 | 서버 측 렌더링된 HTML -> 클라이언트으로 전송 -> JS 파일 준비 -> JS로 동적으로 생성된 DOM 트리에 HTML 을 올려서 결합 -> 결론적으로 초기 렌더링 성능이 최적화
하이드레이션(hydration)은 웹 애플리케이션에서 서버 측 렌더링(SSR)을 사용할 때 사용되는 용어입니다. 이는 클라이언트 측 JavaScript 코드가 실행되기 전에 서버에서 렌더링된 HTML을 클라이언트에게 전송하여 초기 렌더링 성능을 향상시키는 방법입니다.
일반적으로 서버 측 렌더링을 사용하는 웹 애플리케이션에서는 첫 번째 요청에 대한 서버에서의 응답으로 HTML을 전송합니다. 이 HTML은 일반적으로 웹 페이지의 구조와 초기 데이터를 포함합니다. 클라이언트는 이 HTML을 받아서 화면에 렌더링하고, 동시에 자바스크립트 코드를 다운로드하고 실행하여 애플리케이션의 동적인 부분을 초기화합니다. 이 과정을 통해 초기 로딩 시간을 최소화하고 사용자 경험을 향상시킬 수 있습니다.
하이드레이션은 이러한 서버 측 렌더링의 결과물인 HTML을 클라이언트에서 받아와서 자바스크립트 코드에 의해 생성된 돔(DOM) 트리 위에 추가하는 작업을 의미합니다. 이를 통해 서버에서 렌더링된 HTML과 클라이언트에서 생성된 돔이 결합되어 초기 렌더링 성능을 향상시킵니다.
하이드레이션은 주로 리액트와 같은 자바스크립트 프레임워크에서 사용되며, ReactDOM.hydrate() 함수를 사용하여 수행됩니다. 이 함수는 서버 측 렌더링된 HTML과 클라이언트 측 자바스크립트 코드를 결합하여 초기 렌더링을 수행합니다.
하이드레이션 개념 요약
서버에서미리 준비된 HTML 파일을 클라이언트에게 보내고, 그 뒤에 자바스크립트 파일을 전송하여 앱의 동적인 부분을 초기화하는 기법으로 자바스크립트로 동적으로 생성된 DOM 트리 위에 미리 렌더링된 HTML 파일을 추가하는 작업을 수행하는 것 -> 이를 통해 초기 렌더링 성능을 최적화시킴
솔리드 원칙(SOLID)
오늘은 객체지향 프로그래밍뿐만 아니라 프로그래밍 패러다임에서 주요하게 적용되는 원칙인 솔리드 원칙에 대해 정리해봅니다.
단일 책임의 원칙 | 함수, 클래스, 컴포넌트는 단일한 책임을 지녀야 한다.
함수, 클래스, 컴포넌트 등은 단일한 책임을 지녀야 합니다. 즉, 하나의 클래스가 두 가지 이상의 책임을 지니면 단일 책임의 원칙을 위배하는 것입니다.
아래 예시는 UserService 라는 클래스는 사용자와 관련한 로직을 처리히고, EmailService는 이메일 처리에 필요한 책임만 가지고 있으므로 단일 책임의 원칙을 잘 지키고 있는 예시입니다.
class UserService {
// 사용자 정보를 관리하는 책임을 갖는 클래스
getUserById(userId) {
// 사용자 정보를 가져오는 코드
}
saveUser(user) {
// 사용자 정보를 저장하는 코드
}
}
class EmailService {
// 이메일 전송과 관련된 책임을 갖는 클래스
sendEmail(email) {
// 이메일을 전송하는 코드
}
}
개방-폐쇄의 원칙 | 확장(extends)에는 열려 있으나, 변경에는 닫혀(closed) 있어야 한다.
여기서 Shape 클래스에서 메소드는 형태만 갖춰질 뿐 기능 수정 및 구현 불가능하고, 이 기능을 구현하는 것은 해당 메소드를 상속(extends) 받은 자식 클래스에서 이루어져야 합니다. 아래 예시에서도 Shape 클래스에서 draw 메소드는 구현이 불가능하고, 그 자식 클래스에서 구현하도록 되어 있습니다.
class Shape {
// 도형의 기본 클래스
constructor(type) {
this.type = type;
}
draw() {
throw new Error("This method should be overridden");
}
}
class Circle extends Shape {
// 원 도형 클래스
draw() {
// 원을 그리는 코드
}
}
class Square extends Shape {
// 정사각형 도형 클래스
draw() {
// 정사각형을 그리는 코드
}
}
리스코프 치환의 원칙(LSP) | 하위 타입은 기본타입으로 대체할 수 있어야 한다.
이 말을 더 간단하게 설명하면, 부모 클래스로 부터 오버라이딩된 자식 클래스의 메소드는 동일한 인터페이스를 가져야 합니다. 즉, 부모 클래스로부터 log(name) 이라는 메소드를 여러 자식 클래스 또한 동일한 log(name) 이라는 메소드를 가지고 있어야 합니다. 즉, 자식 클래스는 부모 클래스의 하위 타입과 같고 부모 클래스는 상위 타입과 같으므로 상위 타입인 부모 클래스의 객체를 대체할 수 있어야 한다는 말입니다.
아래 코드를 보시면, Shape 이라는 클래스로 부터 draw() 메소드를 Circle 과 Square 클래스가 동일하게 가지고 있으며(오버라이딩), 이들은 부모 클래스로 부터 동일한 인터페이스를 가지는 메소드를 사용하기 때문에, 기존 코드 베이스를 변경하지 않고도 새로운 기능이나 프로세스를 추가해 나갈 수 있으므로 일관성과 확장성이 보장됩니다.
class Shape {
// 도형의 기본 클래스
constructor(type) {
this.type = type;
}
draw() {
throw new Error("This method should be overridden");
}
}
class Circle extends Shape {
// 원 도형 클래스
draw() {
// 원을 그리는 코드
}
}
class Square extends Shape {
// 정사각형 도형 클래스
draw() {
// 정사각형을 그리는 코드
}
}
인터페이스 분리의 원칙 | 사용하지 않는 인터페이스에 클라이언트가 의존하도록 강요해서는 안 됨
쉽게 말해서, 클라이언트가 사용하지도 않는 기능을 사용하도록 강제해서는 안 된다는 말입니다. 예를 들어, 클라이언트가 음식점을 방문했을 때, 콜라는 시키고 싶지 않은데, 콜라를 무조건 주문해야 한다고 강제한다면 안 되겠죠? 비유가 이상하긴 한데, 결론만 말씀드리면, 키오스크 인터페이스는 클라이언트가 자신이 원하는 것을 구매할 수 있도록 주문(), 결제() 와 같은 필수적인 것을 구현하도록 클라이언트에 맞춰 나가야 하지. 콜라구매() 와 같이 클라이언트의 요구사항과는 무관하게 강제하는 기능을 구현하도록 설계해서는 안 된다는 것 입니다.
아래 예시의 경우도 Vehicle 이라는 클래스에서 엔진 시동과 중지 라는 꼭 필요한 기능만 확장하여 구현하도록 하고 있습니다. 또한 Boat 클래스에서는 기존의 확장된 기능 이외에 클라이언트의 요구사항에 맞춰 필요한 추가적인 기능인 sail() 이 존재합니다.
class Vehicle {
// 교통 수단의 기본 클래스
startEngine() {
throw new Error("This method should be overridden");
}
stopEngine() {
throw new Error("This method should be overridden");
}
}
class Car extends Vehicle {
// 자동차 클래스
startEngine() {
// 엔진을 시작하는 코드
}
stopEngine() {
// 엔진을 정지하는 코드
}
}
class Boat extends Vehicle {
// 보트 클래스
startEngine() {
// 보트 엔진을 시작하는 코드
}
stopEngine() {
// 보트 엔진을 정지하는 코드
}
sail() {
// 선박을 항해하는 코드
}
}
의존성 역전의 원칙 | 상위 클래스와 하위 클래스 간에 직접적인 의존 관계가 아닌 둘다 추상화에 의존해야 한다는 원칙
이 원칙을 적용한다면, 상위 레벨에 있는 모듈은 하위 레벨의 모듈에 종속되어서는 안 됩니다. 대신 둘 다 인터페이스에 의해 정의된 추상화에 의존해야 합니다. 즉, 두 모듈이 서로 의존하게 되면 하나의 모듈이 변경될 때 마다 서로가 직접적인 영향을 받기 때문에 코드 리팩터링과 테스트, 유지 보수 등에 좋지 못한 경험을 제공할 수 있습니다. 따라서 하나의 추상화된 인터페이스 계층을 두어서 각 모듈이 변경이 발생하여도 서로 간에는 직접적인 영향을 미치지 않도록 해주는 것이 의존성 역전의 원칙입니다.
의존성 역전의 원칙에서 주요 구성 요소 두 가지
의존성 역전의 원칙은 두 가지 주요 포인트가 있습니다. 알아두면 좋을 것 같아서 언급하고 가는 것이므로 자세한 내용은 언급하지 않고 간략하게만 용어를 정의하고 넘어 갑니다.
제어의 역전(IoC)
제어의 역전은 상위 모듈이 객체를 생성하고 관리하는 책임을 하위 모듈에 위임하는 디자인 패턴입니다. 이 때 상위 모듈과 하위 모듈 간에 인터페이스가 존재하고, 각 모듈은 이 인터페이스를 통해서 상호작용하게 됩니다.
의존성 주입(DI)
의존성 주입은 객체에 필요한 종속성을 하위 모듈이 직접 생성하는 것이 아니라 하위 모듈에 종속성을 제공하는 기법입니다.
의존성 역전의 원칙 예시
아래 예시는 Database의 추상화 계층인 IDatabase 인터페이스를 생성하여 Database 와 User 클래스가 추상화 계층인 IDatabase 에 의존하게 되었습니다 .이로 인해 Database 인스턴스를 User 클래스 내부에서 만들 필요가 없습니다.
interface IDdatabase {
connect(): void;
disconnect():void;
query(query:string):any;
}
class Database implements IDdatabase {
constructor(){ }
connect():void {
// 데이터베이스 연결 로직
}
disconnect():void {
// 데이터베이스 연결해제 로직
}
query(query:string):any {
// 데이터베이스 쿼리 로직
}
}
class User {
private db: IDatabase;
private name: string;
constructor(name:string, db: IDatabase) {
this.db = db;
this.name = name;
}
save():void {
this.db.connect();
this.db.query('INSERT INTO users(name) VALUES("+this.name+")');
this.db.disconnect();
}
}
DOCTYPE | 문서가 어떤 버전의 HTML, XHTML 로 작성되었는지 브라우저에 알리기 위한 선언
DOCTYPE은 HTML 문서의 맨 위에 위치하는 것으로, 문서가 어떤 버전의 HTML이나 XHTML로 작성되었는지 브라우저에게 알려주는 역할을 합니다. 다시말해서 DOCTYPE 선언은 브라우저가 문서를 올바르게 해석하고 렌더링하는 데 중요한 역할을 합니다.
DOCTYPE 선언은 다음과 같은 형식을 가집니다.
<!DOCTYPE doctype_name>일반적으로 HTML5 문서의 경우에는 다음과 같이 DOCTYPE을 선언합니다.
<!DOCTYPE html>
이것은 HTML5의 DOCTYPE 선언입니다. 이것은 이전 버전의 HTML과는 달리 간단하고 표준화되어 있으며, 대부분의 모던 웹 사이트에서 사용됩니다.
DOCTYPE 선언은 브라우저에게 문서의 형식을 알려주므로 올바른 방식으로 문서를 렌더링할 수 있도록 도와줍니다. 만약 DOCTYPE이 선언되지 않으면 브라우저는 문서를 "quirks mode"로 렌더링할 수 있으며, 이는 예상치 못한 레이아웃 문제를 유발할 수 있습니다. 따라서 DOCTYPE 선언은 HTML 문서에서 중요한 부분 중 하나입니다.
Quirks mode
쿼크 모드(Quirks mode)는 웹 브라우저가 웹 페이지를 렌더링하는 방식을 결정하는 두 가지 모드 중 하나입니다.
다른 하나는 표준 모드(Standard mode)입니다.
사용 사례
오래된 웹 페이지
쿼크 모드는 오래된 웹 표준을 사용하여 작성된 웹 페이지와의 호환성을 유지하기 위해 사용됩니다. 이러한 웹 페이지는 현대 웹 브라우저에서 표준 모드로 렌더링될 때 올바르게 표시되지 않을 수 있습니다.
DOCTYPE 선언 누락
웹 페이지에 DOCTYPE 선언이 없는 경우 브라우저는 해당 페이지를 쿼크 모드로 렌더링할 가능성이 높습니다. DOCTYPE 선언은 브라우저에게 해당 페이지가 어떤 웹 표준을 따르는지 알려줍니다.
주요 특징
비표준적 CSS 속성 지원
쿼크 모드는 표준 모드에서 지원되지 않는 일부 비표준적 CSS 속성을 지원합니다. 이러한 속성은 오래된 웹 브라우저에서 사용되었을 수 있습니다.
테이블 레이아웃의 차이
쿼크 모드와 표준 모드에서 테이블 레이아웃이 다르게 렌더링될 수 있습니다.
문자 인코딩 문제
쿼크 모드는 표준 모드와 다른 방식으로 문자 인코딩을 처리할 수 있습니다. 이로 인해 일부 문자가 올바르게 표시되지 않을 수 있습니다.
이러한 특징 등으로 인해 웹 페이지가 쿼크 모드와 표준 모드에서 모두 올바르게 렌더링되는지 확인해야 합니다. 이를 위해 DOCTYPE 선언을 사용하고 표준 웹 표준을 따르는 것이 좋은 이유 입니다.
참고로 웹 브라우저의 개발자 도구를 사용하여 웹 페이지가 어떤 모드로 렌더링되는지 확인할 수 있습니다.
가상돔 | 실제 DOM과 동일한 구조를 가지는 가벼운 복제본
이번에 정리하는 내용은 리액트나 뷰와 같은 프론트엔드 프레임워크에서 적용되는 주요 개념인 가상돔에 대한 부분입니다.
가상돔의 등장배경과 이점
가상돔(Virtual DOM)은 웹 애플리케이션의 성능을 향상시키고 개발자가 더 효율적으로 UI를 관리할 수 있도록 도와주는 개념입니다.
일반적으로 웹 애플리케이션은 사용자의 상호작용에 따라 동적으로 변합니다. 이때 돔의 변화를 관리하는 것은 중요한 과제입니다. 그러나 실제 돔을 직접 조작하는 것은 비용이 많이 들 수 있습니다. 예를 들어, 돔 요소를 추가, 삭제 또는 수정할 때마다 브라우저가 다시 렌더링하고 페이지를 다시 그리기 때문에 성능에 영향을 미칠 수 있습니다.
가상돔은 이러한 문제를 해결하기 위해 도입되었습니다. 가상돔은 실제 돔과 동일한 구조를 가진 가벼운 복제본입니다. 상태 변화가 발생할 때마다 프레임워크는 가상돔을 업데이트하고 이전 가상돔과 비교하여 실제로 변경된 부분을 식별합니다. 그런 다음 변경된 부분만을 실제 돔에 적용하여 전체 페이지를 다시 렌더링하는 것보다 효율적으로 돔을 관리할 수 있습니다.
이러한 방식으로 가상돔은 성능을 향상시키고 불필요한 돔 조작을 최소화하여 웹 애플리케이션의 반응성을 향상시킵니다. 또한, 가상돔은 개발자가 UI 상태를 추적하고 관리하는 데 도움을 줍니다. 예를 들어, React는 상태 변화를 추적하고 가상돔을 통해 이를 처리하는 데 도움을 주므로 개발자가 UI 상태를 직접 관리하기보다는 컴포넌트의 상태를 업데이트함으로써 더 효율적으로 상태 관리를 할 수 있습니다.
리액트에서 가상돔의 동작원리
마지막으로 프론트엔드 진영에서 압도적으로 채택되어 사용되는 리액트의 가상돔 동작원리에 대해 살펴보고 마무리하겠습니다.
리액트(React)에서의 가상돔(Virtual DOM) 동작 원리를 이해하기 위해서는 다음과 같은 과정을 살펴볼 수 있습니다.
상태 변화 감지
우선, 개발자가 상태(State)를 업데이트하는 액션(Action)을 발생시킵니다. 이는 주로 이벤트 핸들러 함수 내에서 발생합니다. React 컴포넌트는 상태가 변경되었음을 감지하고, 해당 컴포넌트와 하위 컴포넌트에 대한 렌더링을 시작합니다.
가상돔 생성
React는 업데이트를 시작하기 전에 현재 상태의 가상돔을 생성합니다. 이것은 이전 가상돔과 동일한 구조를 가지지만, 현재 UI의 상태를 반영합니다.
가상돔 비교
React는 이전 가상돔과 새로 생성된 가상돔을 비교합니다. 이를 통해 변경된 요소와 속성을 식별합니다. 이 과정에서 효율적인 알고리즘(주로 재귀적 차별화 알고리즘이 사용됩니다)을 사용하여 가상돔 트리를 순회하고 비교합니다.
변경 요소 식별
가상돔 비교 과정에서 변경된 요소와 속성을 식별합니다. 이는 이전 가상돔과 새로 생성된 가상돔 간의 차이를 계산하여 수행됩니다.
실제 돔 업데이트
변경된 요소와 속성을 기반으로 React는 실제 돔에 업데이트를 적용합니다. 이때 변경된 부분만을 최소한의 작업으로 업데이트하므로써 성능을 향상시킵니다. 이러한 과정을 재조정(Reconciliation)이라고도 합니다.
렌더링 완료
변경된 부분이 실제 돔에 적용되면 React는 렌더링이 완료되었음을 알리고 사용자에게 새로운 UI를 표시합니다.
이러한 과정을 통해 React는 상태 변화를 효율적으로 관리하고 UI를 업데이트할 수 있습니다. 이는 가상돔을 활용하여 실제 돔 조작을 최소화하고 렌더링 성능을 최적화하는 것을 목표로 합니다.
패키지 관리 파일
이번에 정리하는 내용은 NodeJS 진영에서 필수적으로 사용되는 패키지 관리 파일인 package.json 과 package.lock.json 파일에 대한 정리입니다.
package.json | 프로젝트의 메타데이터와 종속성을 관리
package.json 파일은 프로젝트의 메타데이터와 종속성(dependency) 정보를 포함합니다. 즉, 프로젝트의 이름, 버전, 설명, 저작권 정보 등과 함께, 프로젝트가 의존하는 외부 라이브러리들의 정보를 포함합니다.
이 파일은 npm init 명령을 사용하여 초기화하거나, 수동으로 작성할 수 있습니다. 또한, npm install 명령을 사용하여 종속성을 설치하면, 해당 종속성들의 정보가 package.json 파일에 기록됩니다. 일반적으로 package.json 파일은 소스 코드 버전 관리 시스템에 포함되며, 프로젝트의 메타데이터와 종속성 관리를 위해 사용됩니다.
{
"name": "my-node-project",
"version": "1.0.0",
"description": "A sample Node.js project",
"main": "index.js",
"scripts": {
"start": "node index.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "John Doe",
"license": "MIT",
"dependencies": {
"express": "^4.17.1",
"lodash": "^4.17.21"
}
}
package-lock.json | 설치된 종속성의 정확한 버전 정보를 보장하기 위한 파일
package-lock.json 파일은 프로젝트의 종속성 트리(dependency tree)와 실제로 설치된 패키지의 정확한 버전 정보를 포함합니다. 이 파일은 npm 5부터 도입된 파일로, npm이 종속성을 설치할 때 패키지의 정확한 버전을 보장하기 위해 사용됩니다.
package-lock.json 파일은 npm install 명령을 실행하면 자동으로 생성되며, 패키지의 버전이나 종속성 트리에 변경이 있을 때마다 업데이트됩니다. package-lock.json 파일은 보통 소스 코드 버전 관리 시스템에 포함되지만, 종속성의 정확한 버전을 보장하기 위한 파일이므로 수정되지 않아야 합니다.
{
"name": "my-node-project",
"version": "1.0.0",
"lockfileVersion": 1,
"requires": true,
"dependencies": {
"express": {
"version": "4.17.1",
"resolved": "https://registry.npmjs.org/express/-/express-4.17.1.tgz",
"integrity": "sha512-wavUfEKELl9Xj2JDQWZCJ9xFdr1zmf/rCwz/4h/V+mVjQBveu2oYzAEB0uU4Lpxo0fszPpgX5FZ5IlgCs4mXFg==",
"requires": {
"accepts": "~1.3.7",
"array-flatten": "1.1.1",
"body-parser": "1.19.0",
"content-disposition": "0.5.3",
// 추가적인 종속성 정보...
}
},
"lodash": {
"version": "4.17.21",
"resolved": "https://registry.npmjs.org/lodash/-/lodash-4.17.21.tgz",
"integrity": "sha512-v2kDEe57lecTulaDIuNTPy3Ry4gLGJ6Z1O3vE1krgXZNrsQ+LFTGHVxVjcXQJQWE6SeCMdasen+CcSNw8qOtwQ=="
}
}
}
TDZ 이란? "변수 초기화 전 까지 사용할 수 없도록 변수 접근을 차단 하는 임시 상태"
TDZ(Temporal Dead Zone)는 일시적으로 접근할 수 없는 변수가 있는 영역을 말합니다. 이는 let과 const로 선언된 변수가 호이스팅되었지만 초기화되기 전까지의 상태를 나타냅니다.
TDZ의 개념은 JavaScript의 변수 선언과 초기화의 차이를 명확하게 하기 위해 도입되었습니다. let과 const는 호이스팅되지만, 초기화되기 전까지는 사용할 수 없습니다. 따라서 TDZ에 있는 변수를 참조하려고 하면 오류가 발생합니다.
예를 들어, 다음의 코드를 살펴보겠습니다:
console.log(myVar); // ReferenceError: Cannot access 'myVar' before initialization
let myVar = 42;
이 코드에서 myVar는 호이스팅되지만 초기화되기 전까지는 TDZ에 있습니다. 따라서 console.log(myVar)를 호출하면 TDZ에 있는 변수에 접근하려고 하므로 오류가 발생합니다.
TDZ는 변수의 라이프사이클을 더 명확하게 이해할 수 있도록 도와줍니다. 호이스팅은 변수가 선언되기 이전에 접근할 수 있다는 것을 의미하지만, TDZ는 변수가 초기화되기 전까지는 사용할 수 없다는 것을 보장합니다.
var, let ,const 의 차이점
var
- var로 선언된 변수는 해당 스코프의 최상단으로 끌어올려집니다. 이것은 변수가 선언되기 이전에도 접근할 수 있다는 것을 의미합니다.
- 초기화가 없는 var 변수는 undefined로 초기화됩니다.
- 함수 스코프를 가지므로 함수 내 어디서든 접근할 수 있습니다. 이 말은 if, for 문 등의 블록스코프에 영향을 받지 않으므로, if 나 for 문 내에서 var 키워드로 초기화된 변수가 존재한다면 if 나 for 스코프 바깥에서 console.log 를 해도 출력이 된다는 의미입니다.
간단한 예시를 보여드리면, if 문 내에 초기화된 a 라는 변수를 { } 바깥에서 console.log(a) 를 하니 그대로 a 변수가 출력된 것을 볼 수 있습니다. 이것이 var 키워드를 조심해서 사용하거나 아에 let, const 만 사용해야 하는 이유 중 하나입니다.

let
- 블록 스코프를 가지므로 블록 내에서만 유효합니다. var 와 다르게 if () { } 바깥에서 console.log(a) 를 하니 a 변수는 정의되지 않았다고 에러를 띄워줍니다.
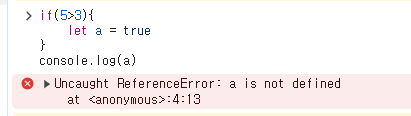
- let으로 선언된 변수는 호이스팅은 발생하지만, TDZ(Temporal Dead Zone)에 의해 초기화되기 전까지 접근할 수 없습니다. TDZ는 해당 변수가 선언된 위치부터 초기화되는 지점까지의 영역을 말합니다.
- 초기화되지 않은 let 변수는 사용할 수 없는 상태(초기화되기 전)에서 TDZ에 갇힙니다.
const
- 블록 스코프를 가지며, 한 번 할당된 값은 변경할 수 없습니다. 즉, 상수로 취급됩니다. 앞서 console.log() 예시에서 본 것처럼 let 과 동일한 결과를 보입니다.
- const로 선언된 변수도 let과 마찬가지로 호이스팅은 발생하지만, 초기화되기 전까지는 접근할 수 없습니다. TDZ에 영향을 받습니다.
- const 변수는 선언과 동시에 초기화되어야 합니다.
요약하자면
var는 함수 스코프를 가지며 호이스팅되어 선언 이전에도 접근할 수 있습니다. 반면에 let과 const는 블록 스코프를 가지며, TDZ에 의해 초기화되기 전에는 접근할 수 없습니다. 따라서 let과 const는 변수를 더 명확하게 관리하고 오류를 줄일 수 있도록 도와줍니다.
렉시컬 스코프
렉시컬 스코프(lexical scope)는 변수가 함수 내에서 어디에서 사용될지를 결정하는 방법을 설명합니다. 이것은 코드가 작성된 위치에 따라 변수의 유효 범위가 결정된다는 것을 의미합니다.
자바스크립트에서 함수가 정의될 때, 해당 함수의 스코프가 정적으로 결정됩니다. 즉, 함수가 선언된 위치에서부터 스코프가 정의됩니다. 이것은 함수가 호출되는 위치와는 관계없이 스코프가 정해진다는 것을 의미합니다. 이것이 렉시컬 스코프의 핵심 아이디어입니다.
예를 들어, 다음의 코드를 살펴보겠습니다
const globalVar = "I'm global";
function outer() {
const outerVar = "I'm outer";
function inner() {
const innerVar = "I'm inner";
console.log(globalVar); // 전역 변수에 접근 가능
console.log(outerVar); // outer 함수 내의 변수에 접근 가능
}
inner();
}
outer();
이 코드에서 inner 함수는 outer 함수 내에서 정의되었습니다. 따라서 inner 함수는 outer 함수의 스코프 내에 있습니다. 이것은 inner 함수가 outer 함수 내에서 정의된 변수인 outerVar에 접근할 수 있음을 의미합니다. 또한 inner 함수는 outer 함수의 스코프를 벗어나 전역 스코프에 있는 변수인 globalVar에도 접근할 수 있습니다.
렉시컬 스코프의 이러한 특성은 코드를 읽고 이해하는 데 도움이 될 수 있으며, 변수의 유효 범위를 예측하는 데 도움이 됩니다. 함수의 스코프가 정의된 위치를 알고 있다면, 해당 함수가 어떤 변수에 접근할 수 있는지 쉽게 알 수 있습니다.
연관 포스트
[JS] 나름 실행 컨텍스트(execution context) 이해 해보기
이 포스트는.. 사실 많은 분들이 실행 컨텍스트에 대해서 포스트를 작성했죠. 저 또한 과거에 작성한 이력이 있고, 기술 블로그라면서 기술에 대한 포스트 보다는 이론에 대한 포스트라서 자격
duklook.tistory.com
cURL
cURL은 "Client URL"의 약자로, 커맨드 라인에서 사용되는 데이터 전송 도구입니다. cURL을 사용하면 다양한 프로토콜을 통해 데이터를 전송하고 받을 수 있습니다. HTTP, HTTPS, FTP, FTPS, SCP, SFTP 등 다양한 프로토콜을 지원합니다.
일반적으로 cURL은 다음과 같은 기능을 수행합니다:
- 데이터 전송: URL을 사용하여 서버로 데이터를 보내거나, 서버에서 데이터를 가져올 수 있습니다.
- 다운로드 및 업로드: 웹 서버에서 파일을 다운로드하거나, 웹 서버에 파일을 업로드할 수 있습니다.
- HTTP 요청 보내기: HTTP GET, POST, PUT, DELETE 등 다양한 HTTP 요청을 보낼 수 있습니다.
- 인증 및 쿠키: 서버에 대한 인증 정보를 제공하거나, 쿠키를 설정하여 세션을 유지할 수 있습니다.
- SSL 지원: 안전한 통신을 위해 SSL 및 TLS 프로토콜을 지원합니다.
cURL은 커맨드 라인에서 간편하게 사용할 수 있으며, 다양한 운영 체제에서 지원됩니다. 다양한 웹 서비스나 API와 상호 작용할 때 유용하게 사용됩니다. 또한 cURL을 통해 간단한 웹 서비스 테스트나 디버깅을 수행할 수도 있습니다.
cURL 예시
웹 페이지 다운로드
curl -O http://example.com/file.zip
이 명령어는 http://example.com/file.zip에서 파일을 다운로드하여 현재 디렉토리에 저장합니다.
HTTP GET 요청
curl http://api.example.com/data
이 명령어는 http://api.example.com/data에 HTTP GET 요청을 보내고, 서버의 응답을 출력합니다.
HTTP POST 요청
curl -X POST -d "username=user&password=pass" http://api.example.com/login
이 명령어는 http://api.example.com/login에 HTTP POST 요청을 보내고, username과 password를 서버로 전송합니다.
인증된 HTTP GET 요청
curl -u username:password http://api.example.com/data
이 명령어는 http://api.example.com/data에 인증된 HTTP GET 요청을 보냅니다. -u 옵션을 사용하여 사용자 이름과 비밀번호를 지정합니다.
HTTPS 요청
curl https://secure.example.com/data
이 명령어는 https://secure.example.com/data로 안전한 HTTPS 요청을 보냅니다.
파일 업로드
curl -F "file=@localfile.txt" http://api.example.com/upload
이 명령어는 localfile.txt 파일을 http://api.example.com/upload에 파일 업로드합니다.
헤더 포함한 요청
curl -H "Authorization: Bearer token123" http://api.example.com/data
이 명령어는 http://api.example.com/data에 Authorization 헤더를 포함한 요청을 보냅니다.
Flux 패턴
Flux는 Facebook에서 개발된 애플리케이션 아키텍처 패턴입니다. 주로 React와 함께 사용되며, 복잡한 사용자 인터페이스를 효율적으로 관리하기 위해 설계되었습니다. Flux 아키텍처는 다음과 같은 핵심 원칙을 기반으로 합니다.
- 단방향 데이터 흐름: Flux는 데이터의 단방향 흐름을 강조합니다. 애플리케이션에서 데이터는 한 방향으로만 흐르며, 변경 사항은 항상 동일한 경로를 따릅니다. 이로써 데이터 흐름이 예측 가능하고 디버깅이 용이해집니다.
- 단일 소스의 진실(Single source of truth): 애플리케이션의 상태는 단일 데이터 스토어에 저장됩니다. 이는 모든 컴포넌트가 동일한 상태에 대한 접근 및 업데이트를 보장하여 데이터 일관성을 유지합니다.
- 데이터 변경 시점의 명확성: Flux 아키텍처에서는 데이터 변경을 수행하는 명확한 지점이 존재합니다. 이러한 지점을 "액션(Action)"이라고 하며, 상태 변화를 일으키는 유일한 방법입니다. 액션은 애플리케이션의 사용자 상호작용 또는 외부 이벤트와 같은 트리거에 의해 발생합니다.
- 뷰와 로직의 분리: Flux는 뷰(View)와 비즈니스 로직을 분리하여 유지 보수성을 향상시킵니다. 뷰는 단순히 상태를 표시하고 사용자 입력을 수신하며, 비즈니스 로직은 스토어와 액션에서 처리됩니다.
- 평평한 데이터 흐름: Flux 아키텍처에서는 애플리케이션의 상태가 "평평한" 구조를 가지도록 권장됩니다. 이는 데이터가 중첩되지 않고 단일 레벨의 구조를 가지도록 하는 것을 의미합니다.
Flux 아키텍처는 주로 다음과 같은 요소로 구성됩니다
- 액션(Action): 애플리케이션에서 발생하는 이벤트 또는 사용자 상호작용을 나타냅니다(상태변화 발생).
- 디스패처(Dispatcher): 액션을 스토어로 전달하는 중앙 허브 역할을 합니다.
- 스토어(Store): 애플리케이션의 상태를 저장하고 관리하는 역할을 합니다.
- 뷰(View): 사용자 인터페이스를 표시하고 사용자 입력을 처리합니다.
패턴 예시

Action creator는 라이브러리에서 제공하는 도움 메소드로 메소드 파라미터에서 action을 생성하고 type 을 설정하거나 dispatcher에게 제공하는 역할을 합니다.
모든 action은 store가 dispatcher에 등록해둔 callback을 통해 모든 store에 전송되며, action에 대한 응답으로 store가 스스로 갱신을 한 다음에는 자신이 변경되었다고 모두에게 알립니다.
controller-view라고 불리는 특별한 view가 변경 이벤트를 듣고 새로운 데이터를 store에서 가져온 후 모든 트리에 있는 자식 view에게 새로운 데이터를 제공합니다.
Babel
바벨은 ECMAScript 표준에 따른 자바스크립트 최신 문법을 오래된 버전의 브라우저에서도 동일하게 사용할 수 있도록 코드를 변환시켜주는 트랜스파일러 입니다.
예를 들어 ES6 에 등장한 class 문법의 경우 과거 오래된 브라우저에서는 인지 못할 수 있습니다. 이 때 바벨은 해당 문법을 ES5 문법 구조로 변환하여 class 가 오래된 브라우저에서도 동작 가능하게 코드는 변환시켜 줍니다.
Babel은 .babelrc 파일을 통해 설정을 구성할 수 있습니다. 이를 사용하여 변환 옵션을 지정하거나 플러그인을 설정할 수 있게 됩니다.
SMTP(Simple Mail Transfer Protocol)
SMTP는 Simple Mail Transfer Protocol의 약자로, 인터넷 상에서 이메일을 전송하는 데 사용되는 표준 프로토콜입니다.
(이메일) 클라이언트나 (이메일) 서버 간에 이메일을 주고받는 데 사용되는 SMTP는 전송 프로토콜로서, 클라이언트가 이메일을 수신하는 수신 서버로 이메일을 전송하는 역할을 합니다. 그냥 쉽게 말해서 이메일을 전송하는데 사용되는 규약을 의미합니다.
SMTP는 클라이언트-서버 모델을 따르며, 일반적으로 클라이언트가 이메일을 작성하여 SMTP 서버에 보내고, SMTP 서버는 해당 이메일을 수신자의 SMTP 서버로 전달합니다. 수신자의 SMTP 서버는 이메일을 수신하여 해당 사용자의 메일박스에 저장하거나 다른 서버로 전달합니다.
SMTP는 TCP/IP 프로토콜 스택 위에서 작동하며, 기본적으로 25번 포트를 사용합니다.또한, 일반적으로 SMTP 서버는 이메일 클라이언트가 SMTP를 통해 이메일을 보낼 수 있도록 리스닝(대기)하고 있습니다.
SMTP는 단순히 이메일을 전송하는 데 사용되므로 이메일의 수신, 저장 및 읽기와 같은 다른 작업들을 수행하지 않습니다. 그러므로 SMTP는 POP (Post Office Protocol) 또는 IMAP (Internet Message Access Protocol)과 함께 사용되어 이메일을 수신하는 데 사용됩니다. 이러한 프로토콜들은 이메일 클라이언트가 서버로부터 이메일을 가져오고, 읽고, 삭제할 수 있도록 합니다.
요약하면, SMTP는 이메일을 보내기 위한 프로토콜로서, 클라이언트가 이메일을 작성하여 서버에 전송하고, 해당 서버가 수신자의 SMTP 서버로 전달하여 이메일을 전송하는 역할을 합니다.
| 간이 전자 우편 전송 프로토콜(SMTP) 모델에서 발신자의 이메일 클라이언트는 SMTP 클라이언트 역할을 하고 발신자의 이메일 서버는 SMTP 서버 역할을 합니다. 이 클라이언트는 서버와의 연결을 시작하고 수신자 세부 정보, 제목 및 본문이 포함된 이메일을 전송합니다. 서버는 이 이메일을 처리하고 수신자 주소를 기반으로 적합한 다음 서버를 결정합니다. 다음 서버는 전송 경로에 있는 다른 SMTP 서버일 수도 있고 최종 대상, 즉 수신자의 이메일 서버일 수도 있습니다. 메시지가 받는 사람의 서버에 도착하면 POP 또는 IMAP 같은 다른 프로토콜을 사용하여 받는 사람의 받은 편지함으로 전달됩니다. |
HTTP(HyperText Transfer Protocol)
HTTP 란 무엇일까요??
하이퍼텍스트 전송 프로토콜, 인터넷에서 데이터를 전송할 때 사용하는 규약을 의미합니다.
더 설명하자면, TCP 기반의 클라이언트와 서버 사이에 이루어지는 요청/응답 프로토콜입니다. HTTP는 Text Protocol로 사람이 쉽게 읽고 쓸 수 있으며. 프로토콜 설계상 클라이언트가 요청을 보내면 반드시 응답을 받아야 합니다. 응답을 받아야 다음 request를 보낼 수 있습니다.
단어만 본다면 무슨 말인지 이해하기 어려울 수 있습니다. 다만, 이를 하나하나 해석해보면 쉽게 이해 가능합니다.
우선 HyperText 는 텍스트에 링크가 걸려 있어서 해당 링크를 클릭하면 다음 웹 페이지를 이동할 수 있게 해주는 텍스트 입니다. Transfer 은 단어 그대로 옮기다 라는 의미인데, 명사로는 전송이라고 이해하면 됩니다. 대망의 Protocol 은 규약, 규정을 의미하는데, 지켜야하는 규칙을 의미 합니다.
이 모든 단어의 의미를 합쳐서 해석해보면, "하이퍼 텍스트를 전송하는 데 지켜야하는 규칙" 이라고 이해하면 됩니다. 즉, 하이퍼텍스트를 클라이언트와 서버 사이에 주고 받을 때 꼭 지켜야 하는 것들을 정해놓았기에 이를 따라야 한다는 의미와 같죠.
웹 사이트에서는..
보통 웹 사이트에서 HTTP 는 클라이언트(브라우저)와 서버 간의 요청과 응답 사이 이루어지는 통신 방법을 규정 합니다. 해당 요청과 응답에는 HTML, CSS, JS, 이미지 등등의 다양한 요소가 포함되어 있구요.
HTTP 통신이 이루어지는 포트는 기본 80 으로 되어 있는데, 해당 포트를 통해 데이터를 주고받을 때 사용하는 패킷은 전송되는 중에 해커에 의해 스니핑이 가능하므로 이를 불가능하게 TLS 나 SSL 처리한 HTTPS 가 존재합니다. 참고로 HTTPS 는 443 포트를 기본 포트로 지정해서 사용합니다.
HTML(HyperText Markup Language)
HTML 이란 무엇일까요? 제가 찾아본 바로는 HTML 은 하이퍼텍스트를 마크업 형태로 구조를 설계하는 언어로 정의가 됩니다.
여기서 하이퍼텍스트는 텍스트에 링크가 걸려 있어서 다른 웹 페이지로 이동이 가능한 텍스트를 의미하는데요. 흔히 a 태그를 이용해서 href 를 지정하고 그 사이에 텍스트를 입력하게 되면, 해당 텍스트가 하이퍼텍스트가 됩니다.
즉, 이러한 하이퍼텍스트를 마크업 구조(<a></a>) 로 표현하여 웹 페이지(문서)를 구조화하는 것 HTML 입니다. 다만, 현재에 와서 하이퍼텍스트뿐만 아니라 비디오, 오디오, 이미지 등의 요소를 모두 다루기 때문에 하이퍼텍스트에만 국한하여 보는 언어는 아니라는 사실을 인지할 필요는 있을 것 같습니다.
분산 하이퍼 미디어 시스템
분산 하이퍼미디어 시스템은 분산된 컴퓨터 시스템과 하이퍼미디어 기술을 결합한 시스템을 의미합니다. 이는 다수의 컴퓨터나 네트워크 장치가 서로 연결되어 분산되어 있으며, 이를 통해 다양한 형태의 하이퍼미디어 콘텐츠에 접근하고 상호 작용할 수 있는 시스템을 말합니다.
여기서 핵심이 되는 키워드는 서로 연결, 분산 이라는 점인데요. 서로 멀리 떨어져 있어도 그물망 처럼 연결되어 있기 때문에 서로 간에 상호작용이 가능하도록 관리하고 있는 시스템이라 할 수 있겠습니다.
| 정보) 하이퍼미디어 |
| 텍스트, 이미지, 오디오, 비디오 등 다양한 미디어 형식으로 구성된 데이터를 의미합니다. 분산 하이퍼미디어 시스템은 이러한 하이퍼미디어를 다루는 데에 중점을 두고 있으며, 사용자가 이를 검색, 검토, 공유, 조작할 수 있는 환경을 제공합니다. |
하이퍼미디어 시스템하면 WWW 가 떠오르죠.
분산 하이퍼미디어 시스템의 예로는 월드 와이드 웹(WWW)이 있습니다. 월드 와이드 웹은 전 세계적으로 분산된 서버와 클라이언트로 구성되어 있으며, 하이퍼텍스트 문서(HTML), 이미지, 비디오, 오디오 등 다양한 미디어를 포함하고 있습니다. 사용자는 웹 브라우저를 통해 이러한 리소스에 접근하고 상호 작용할 수 있습니다.
또한, 분산 하이퍼미디어 시스템은 다양한 분야에서 사용되고 있습니다. 예를 들어, 온라인 미디어 스트리밍 서비스, 분산 문서 공유 시스템, 협업 툴, 온라인 교육 플랫폼 등이 분산 하이퍼미디어 시스템의 예입니다. 이러한 시스템은 사용자가 다양한 미디어를 공유하고 협업하는 데에 활용됩니다.
REST API
REST는 REpreSentational State Transter 의 약자로 나름 의역해보면 대표적인 상태 전송자 입니다. 물론 Representational 의 다른 의미로 재현, 표현이라는 말도 있기 때문에 표현적인 상태 전송자 라고 보는게 더 맞는 것 같네요. 보다 명확한 정의는 네크워크를 통해 서로 다른 분산 시스템 간에 데이터를 효율적으로 주고받는 데 사용되는 표준화된 방법이라 할 수 있습니다. 참고로 여기서 데이터가 상태를 의미합니다.
| 즉, 방대하게 퍼져 있는 분산 시스템 사이를 연결하는 아주 효율적인 경로를 지정하여 데이터를 주고받을 수 있도록 구조화되어 있는 통신법이라 이해해도 무방할 것 같습니다. |
보통 네트워크 통신을 통해 데이터를 주고 받을 때, REST 원칙에 따라 데이터를 전송 및 응답받는데, 여기서 데이터를 주고받는데 사용되는 경로를 URI 라고 부릅니다(보통 /files 이렇게 표기). 즉, URI 라는 리소스 를 식별하는 경로 통해 데이터를 주고받을 수 있습니다(참고로 리소스 혹은 자원 자체는 files 이고, /files 를 합쳐서 URI 라고 부릅니다. 즉, files 라는 자원을 식별하는 경로가 URI).
| 예를 들어, 클라이언트에서 example.com/items 라고 요청을 서버로 보내면 서버에서 /items 경로로 요청이 온 것을 확인하고 클라이언트의 요청을 처리한 후 응답을 하게 됩니다. 여기서 /items 가 리소스(자원)인 것이죠. |
REST API 를 누가 만들었는지 찾아보니 2000년대 로이 필딩(Roy Fielding) 이라는 사람이 웹의 아키텍처를 설계할 때 사용된 원칙을 정리하고 분류하기 위해 소개하였다고 나와 있습니다.
필딩의 논문에서 소개된 REST 원칙은 자원, 표현, 상태, 인터페이스 및 연결성 등의 개념으로 이루어져 있습니다. 이는 HTTP 프로토콜을 기반으로 하는 분산 하이퍼미디어 시스템의 설계 원칙을 제공하는데, 이를 표로 정리해보면 다음으로 정리가 됩니다.
REST 원칙

REST API 의 구성요소

JSON
JavaScript Object Notation 의 약자로 데이터를 키-값 형태인 자바스크립트 객체 형태로 표기하는 데이터 표기법을 의미합니다. 물론, 실제 자바스크립트 객체와 달리 키와 값의 문자열은 모두 " " 으로 감싸야 한다는 점, undefined와 같이 일부 데이터 타입에 대한 변환을 지원하지 않는다는 차이점이 존재합니다.
그러함에도 JSON은 플랫폼 독립적인 특징과 이해하기 쉽고, 표기가 단순하다는 장점으로 다양한 프로그래밍 언어나 플랫폼 간에 재사용성이 높다는 강점을 지닙니다.
보통 웹 환경에서는 클라이언트와 서버 간의 네트워크 통신에서 요청과 응답 사이에 데이터를 주고 받을 때 사용됩니다.
JSON 에서 허용되는 데이터 타입
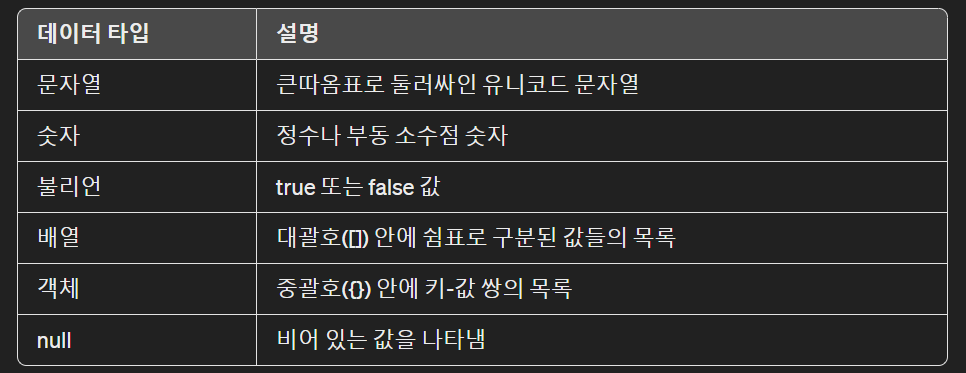
JSON 에서 허용되지 않는 데이터 타입

직렬화와 역직렬화
직렬화 | 데이터(원본)를 메모리 저장 및 전송하기 위한 데이터 형태로 포맷을 변환하는 프로세스
객체나 데이터 구조(자료구조) 를 메모리 상에 저장할 수 있는 형태로 변환하거나, 다른 시스템 환경으로 전송할 수 있는 형태인 바이트 스트림이나 다른 데이터 형태로 포맷을 변환하는 프로세스입니다. 이렇게 직렬화된 데이터는 다른 환경에서도 역직렬화를 통해 해당 환경에 맞는 데이터 포맷(원본)으로 변환할 수 있습니다.
보통 자바스크립트에서 직렬화를 위한 메서드로 JSON.stringifiy() 메소드를 지원하고 있는데요. MDN 에서 포스팅한 내용의 일부인데, 해당 메서드가 어떤 역할을 하는지 다음 단어를 보시면 이해하기 쉬울 것 같네요.

역직렬화 | 직렬화된 데이터를 현재 환경에서 사용할 수 있는 원본 상태로 되돌리는 프로세스
직렬화된 데이터를 현재의 시스템에서 사용 가능하도록 현재 환경에 맞는 데이터의 원본 상태로 변환하는 프로세스 입니다.
B2B SaaS
"B2B SaaS"는 "Business-to-Business Software as a Service"의 약어입니다. 이 용어는 기업 간에 서비스로 제공되는 클라우드 기반 소프트웨어를 가리킵니다. 이는 기업이 자사의 비즈니스 운영을 지원하고 향상시키기 위해 구독 형태로 소프트웨어를 이용하는 모델을 말합니다.
예를 들어, 프로젝트 관리, 고객 관리, 인사 관리, 회계, 마케팅 자동화 등과 같은 다양한 기업 운영 부문에 대한 소프트웨어 서비스를 B2B SaaS로 제공할 수 있습니다. 이러한 서비스는 대개 구독 기반으로 제공되며, 기업들은 웹 브라우저를 통해 이를 액세스하여 필요한 기능을 사용할 수 있습니다. 이러한 모델은 소프트웨어를 구매하고 설치하는 전통적인 방식에 비해 유연성이 높으며 초기 투자를 줄일 수 있어 많은 기업들에게 매력적입니다.
디바운스
디바운스 라는 말 들어보셨나요? 소프트웨어에서는 디바운스를 디바운싱이라는 기술로 불리며 발생하는 여러 이벤트를 하나로 압축하여 처리하는 기술로 불리고 있습니다. 그런데, 이 디바운스라는 언어는 어디서 왔는지 궁금하지 않으셨나요?? 그래서 이에 대해 알아보고 정리해 보았습니다.
우선, 디바운스(Debounce)의 어원은 기계, 특히 전기 및 전자 기기에서 나온 용어입니다. 즉, "디바운스"는 전기 스위치의 특정 문제를 설명하는 데 사용되는 용어였습니다.
전기 스위치나 버튼을 누를 때, 스위치의 접점(접촉되는 지점)이 물리적으로 접촉되는 순간에는 여러 번의 접촉이 발생할 수 있습니다(쉽게 말해 탁 하고 끝나는게 아니라 타타탁 할 수 있다는 말이죠).
이는 전기 신호에서 바운스(bounce) 현상으로 알려져 있습니다. 이러한 바운스 현상은 신호의 불안정성을 유발할 수 있습니다. 이러한 문제를 해결하기 위해 디바운싱은 스위치의 여러 개의 연속적인 신호를 하나의 단일 신호로 압축하여 처리하는 기술입니다. 이를 통해 스위치의 신호를 안정적으로 처리할 수 있게 되는 거죠.
이러한 개념이 소프트웨어 개발에 적용될 때, 디바운스는 연이어 발생하는 이벤트를 하나로 묶어서 제어하는 기술을 의미합니다. 주로 사용자 인터페이스(UI)에서 사용되며, 사용자의 반복적인 동작에 따른 불필요한 처리를 방지하거나 성능을 최적화하는 데 활용됩니다. 보통 자바스크립트에서 Scroll 이벤트를 등록하여 사용할 때 스크롤 시 엄청 많은 이벤트가 호출되죠. 이것은 의도된 방식이지만, 너무 과도한 이벤트 콜백의 호출은 때로는 메모리 과부하를 일으키기도 합니다. 특히 모바일 환경에서는 심각한 버벅임 문제가 발생할 수 있죠.
그래서 이 때 적용하는 방법이 디바운싱 혹은 디바운스 라고 불리는 기술이고, 과도하게 발생하는 이벤트의 호출을 막고, 일정 시간이 지난 후에 한 번만 이벤트가 호출되도록 하는 것입니다.
그럼 여기서 쓰로틀링 이라는 기술과 헷갈릴 수 있어요. 둘 다 함수나 이벤트 호출을 제한하는 것은 동일하지만, 쓰로틀링의 경우에는 반복 호출되는 함수의 실행 간격을 지정해두고 그 간격 마다 매번 함수를 실행하는 것이지만(즉, 여러 번의 함수 호출이 이루어질 때 해당 함수의 호출이 5초를 간격으로 지정해두면 5초 마다 호출이 되는 것입니다),
디바운싱은 아에 함수나 이벤트의 실행 자체를 매 이벤트 호출마다 매번 무효화 시킵니다. 즉, 사용자가 스크롤 하고 있다고 가정한다면, 스크롤이 되는 동안에는 이벤트나 함수의 호출 자체를 막아버리죠.
쉽게 말해, A 라는 친구가 말할 때 마다 "아~~아아~~" 거리면서 말 못하게 막다가, 그만두면 몇 초의 정적이 흐른 뒤에 A 라는 친구가 말할 수 있도록 해주는 것입니다.
즉, 사용자가 마우스 스크롤을 그만 두는 순간부터 지정된 시간(예를 들어 5초 라면 5초의 시간)이 지난 후 이벤트를 호출한다는 점에서 차이가 있습니다.
마지막으로 GPT가 정리한 내용을 남기고 마무리 합니다.

이벤트 위임
이벤트 위임은 자바스크립트 언어에서 사용되는 개념 중 하나로 부모 요소가 이벤트를 관리하여, 자식 요소에서 발생시키는 이벤트를 부모요소가 대신 호출해주는 방식을 의미합니다.
쉽게 말해, 이벤트에 대한 관리 권한을 자식요소 모두가 부모 요소에게 위임하는 것이죠. 이 방식의 장점은 자식 요소 각각에 이벤트 리스너를 등록하지 않아도 되므로 메모리 낭비를 막을 수 있다는 점 입니다. 또한 동적으로 늘어나는 자식 요소 모두에게 이벤트 리스너를 등록하는 것은 생각보다 신경써야 할 문제가 많기 때문에(- 예를 들어 for문이나 foreach로 모든 자식요소를 순회하여 이벤트 리스너를 등록하는 경우, 만일 createElement 등으로 동적으로 생성된 요소라면 이벤트 리스너가 등록되지 않는 문제가 발생할 수 있음) 여러모로 장점이 많은 방식입니다.
이러한 동작이 가능한 이유는 바로 이벤트 버블링 덕분인데요. 자식요소에서 감지된 이벤트는 DOM 객체의 최상위 노드로 전파되는 특징이 있기 때문에, 이러한 이벤트 전파를 부모 요소에서 캡처하기 때문입니다.
컨텍스트(Context)
컨텍스트는 프로그래밍에서 현재 실행되는 코드의 상황이나 환경을 나타내는데, 이는 코드가 실행될 때 현재의 스코프, 변수, this 값 등을 포함합니다. 컨텍스트는 현재 코드의 실행 상황을 나타내는데, 스코프 체인, 변수, 함수 등과 같은 정보들이 해당 컨텍스트에 속합니다
단일 진실 공급원
단일 진실 공급원은 정보 모형과 관련된 데이터 스키마, 즉 모든 데이터 요소를 한 곳에서만 제어 또는 편집하도록 조직하는 관례로서, 데이터 요소로의 가능한 연결은 모두 참조로만 이루어집니다.
HTTP/1.0 과 HTTP/1.1 의 차이점
지속적인 연결 (Persistent Connection)
- HTTP/ 1.0: 각 요청에 대해 새로운 연결을 맺고, 응답 후에 연결을 끊어야 합니다.
- HTTP/ 1.1: 단일 연결을 통해 여러 요청과 응답을 처리할 수 있습니다. 이를 통해 연결을 맺고 끊는 과정의 오버헤드를 줄일 수 있습니다.
파이프라이닝 (Pipeline)
- HTTP/ 1.0: 요청과 응답이 순차적으로 처리되므로, 다음 요청을 보내기 전에 이전 요청이 완료되어야 합니다.
- HTTP/ 1.1: 여러 요청을 병렬로 보내고, 응답이 도착하는 순서대로 처리할 수 있습니다. 이를 통해 네트워크 지연을 최소화할 수 있습니다.
캐시 관리 (Caching)
- HTTP/ 1.0: 캐시 제어에 대한 표준화가 부족하며, 캐시를 사용할지 여부는 서버의 응답에 따라 결정됩니다.
- HTTP/ 1.1: 캐시 제어를 향상시켜 캐시 동작을 명시적으로 제어할 수 있습니다. 이를 통해 캐시 효율성을 높일 수 있습니다.
호스트 헤더 필수화 (Host Header Requirement)
- HTTP/ 1.0: 호스트 헤더가 선택 사항이지만, 대부분의 서버에서는 필수적으로 요구합니다.
- HTTP/ 1.1: 모든 요청에는 호스트 헤더가 필수로 포함되어야 합니다.
왜 호스트 헤더가 필수화 되었을까에 대해서 정리하자면, 원래 HTTP/1.1 이전의 버전에서는 단일 IP 주소당 하나의 호스트명만을 가정했습니다(무조건 요청 1개만 보낼 수 있으니 당연했죠).
하지만 HTTP1.1에서는 동일한 웹 서버에서 여러 개의 도메인 이름을 호스팅할 수 있으므로, 클라이언트는 요청을 보낼 때 호스트 헤더를 사용하여 요청하는 도메인 이름을 명시적으로 지정해야 합니다. 안 그러면 구분 못 하니까요.
호스트 헤더는 다음과 같은 형식으로 표현됩니다.
Host: example.com
여기서 "example.com"은 요청을 전송하려는 대상 호스트의 도메인 이름이나 IP 주소를 나타냅니다.
호스트 헤더의 존재는 하나의 웹 서버에서 여러 개의 도메인을 호스팅할 수 있도록 하고, 가상 호스트(Virtual Host)를 구현하는 데 중요한 역할을 합니다. 요청을 받은 서버는 호스트 헤더를 기반으로 요청을 처리하고, 해당 요청을 처리할 도메인에 대한 서비스를 제공합니다.
요청 파이프라이닝 (Request Pipelining)
HTTP/ 1.0: 지원하지 않습니다.
HTTP/ 1.1: 여러 요청을 병렬로 보낼 수 있어서, 요청과 응답 사이의 지연 시간을 줄일 수 있습니다.
참고로, 요청 파이프라이닝(Request Pipelining)은 HTTP 클라이언트가 여러 개의 요청을 동시에 보내고, 이에 대한 응답을 순차적으로 받는 기술입니다
HTTP/1.1 의 단점
HTTP1.1 은 1.0 에 비해서 요청을 병렬로 처리하고, keep-alive 속성을 서버에서 제어하여 TCP 연결 시간을 늘려서 한 번의 연결 동안에 여러 번 송수신이 가능하다는 장점이 있지만, 문제는 동기적으로 처리되는 고질적인 문제로 처음에 요청한 파일의 크기가 어어어엄청 크다면, 그 뒤에 밀려있는 네트워크 요청에 대한 패킷 처리도 어어어엄청 지연되는 문제가 발생한다.
예를 들어, 이미지 파일이 2GB가 넘는다고 가정할 때, 뒤에 있는 JS 와 소소한 파일들은 2MB 를 넘지 않는다고 가정하자. 이 때 JS 와 소소한 파일들이 거대한 이미지 파일을 제치고 우선 처리되는 것이 아니라 우선 요청이 들어온 이미지 파일에 대한 처리를 우선시 하므로 네트워크 송수신 사이에 지연이 발생할 수 있다는 치명적인 단점이 존재했다. 그리고 이러한 문제를 HOL(Head Of Line Blocking) 이라 부른다.
또한 받아와야 하는 이미지의 수가 50개와 같이 대량으로 각각 네트워크 요청으로 받아와야 하는 상황이 있다고 가정해보자. 이 때 HTTP/1.1 의 경우에는 이를 병렬로 처리하더라도 각 이미지에 대한 네트워크 요청에 대한 송수신을 진행해야 하므로 많은 부하를 경험하게 된다. 물론 이 문제를 개선하기 위해 이미지 스프라이트와 같은 기술을 적용하거나, 애초에 네트워크 요청을 발생시키지 않는 Base64 인코딩을 사용한 이미지 처리도 있지만 얻는게 있으면 잃는 것도 있는법이니 완벽한 방법은 아니다.
가상머신
한 대의 물리적 컴퓨터 위에 여러 개의 가상머신을 구성하여, 그 내부에서 운영체제를 돌리는 형태로 구동하는 방식 입니다. 다시 말해, CPU 나 RAM 가 같은 하드웨어 장치들을 가상의 설정만으로 사용할 수 있도록 하는 것을 의미 합니다.
이 때 가상의 설정이 가능하도록 하는 중간 계층을 하이퍼바이저라고 부릅니다. 즉, 하드웨어 → 하이퍼바이저 → 여러 개의 가상머신[ 이 때, 각 가상머신 당 하나의 운영체제 ] 형태가 되는 것이죠.
지수 백오프 알고리즘
지수 백오프 알고리즘은 부작용에 대응하여 제어되는 프로세스의 속도를 줄이는 폐쇄 루프 제어 시스템 의 한 형태입니다. 예를 들어, 스마트폰 앱이 서버 연결에 실패하면 1초 후에 다시 시도하고, 다시 실패하면 2초 후에 다시 시도하고, 그 다음에는 4번을 시도합니다. 매번 일시 중지에 고정된 양이 곱해집니다(여기서는 사례 2). 이 경우 부작용은 서버 연결에 실패하는 것입니다. 부작용의 다른 예로는 네트워크 트래픽 충돌 , 서비스의 오류 응답 또는 속도를 낮추라는 명시적인 요청(예: "백오프")이 있습니다.
지수 백오프(Exponential Backoff) 알고리즘은 네트워크 통신에서 재전송을 제어하기 위한 알고리즘입니다. 이 알고리즘은 특히 통신 시 발생할 수 있는 충돌이나 혼잡을 관리하고, 네트워크 리소스의 효율적인 사용을 도모합니다.
일반적으로 데이터를 전송하는 시스템에서는 ACK(Positive Acknowledgement)와 같은 메시지를 받지 못했을 때 재전송을 요청합니다. 이때 지수 백오프 알고리즘은 다음과 같은 절차를 따릅니다.
- 초기화: 초기에는 일정한 시간 간격으로 재전송을 시도합니다.
- 백오프: 만약 ACK를 받지 못하면, 재전송 시간을 증가시킵니다. 이를 통해 네트워크 혼잡이나 다른 이유로 인한 전송 지연을 고려할 수 있습니다.
- 지수 증가: 재전송 시간을 지수적으로 증가시킵니다. 대부분의 경우, 재전송 시간은 이전 재전송 시간의 배수로 증가합니다.
- 최대 재전송 제한: 재전송 시간이 너무 길어질 수 있으므로 최대 재전송 시도 횟수나 최대 재전송 시간을 설정하여 네트워크 리소스의 낭비를 방지합니다.
참고자료
https://en.wikipedia.org/wiki/Exponential_backoff
상태
상태는 프로그램이나 시스템이 실행되는 동안 유지되는 정보를 의미합니다. 예를 들어, 자바스크립트 코드에서 다음과 같은 변수가 있다고 가정해봅시다.
let a = 5;
여기서 a 변수는 상태를 나타내는 변수이며, 5라는 상태를 프로그램이 실행되는 동안 유지하고 있게 됩니다. 이 외에도 변수에 담길 수 있는 모든 값들이 상태라고 이해하면 됩니다. 해당 변수에 담긴 값은 프로그램이 실행되는 동안 메모리 상에 기억되어 있기 때문이죠. 그리고 이 값(상태)은 프로그램이 실행되는 동안 해당 상태를 활용하는 모든 동작에서 영향을 미치게 됩니다.
참고로 함수형 프로그래밍이나 리액트에서 상태의 불변성을 이야기할 때 불변성은 기존 a 라는 변수에 10 이라는 새로운 값을 직접적으로 할당하여 변경해서는 안 된다는 것을 의미합니다.
즉, a = 10; 과 같이 값을 할당하는 것이 아니라 let b = 10; 와 같이 새로운 변수를 생성하여 새로운 상태를 할당해야 합니다. 이러한 원리는 리액트에서 setState 의 내부 동작에서 잘 드러나고 있습니다. setState 로 상태를 업데이트하면 기존 상태를 유지한 상태에서 변경하는 것이 아니라, 기존 상태를 버리고 새로운 상태로 대체하는 방식을 취함으로써 불변성을 유지합니다.
HMR
프로그래밍에서 HMR은 Hot Module Replacement의 약자로, 모듈 교체 또는 핫 리로딩이라고도 불립니다. HMR은 웹 개발 과정에서 코드를 변경하면 새로고침 없이 실시간으로 변경 사항을 적용하는 기능입니다. 개발 과정을 크게 효율화하고 시간을 절약할 수 있는 매우 유용한 기능입니다.
HMR 작동 방식
HMR은 일반적으로 다음과 같은 방식으로 작동합니다.
- 개발자는 웹 개발 서버와 클라이언트 앱을 실행합니다.
- 개발자가 코드를 변경하면 서버는 변경 사항을 감지합니다.
- 서버는 변경된 모듈을 클라이언트 앱에 전송합니다.
- 클라이언트 앱은 새 모듈을 로드하고 적용합니다.
- 페이지 새로고침 없이 변경 사항이 화면에 반영됩니다.
HMR 장점
HMR은 다음과 같은 장점을 가지고 있습니다.
- 개발 속도 향상: 페이지 새로고침 없이 코드 변경 사항을 확인할 수 있기 때문에 개발 속도를 크게 향상시킬 수 있습니다.
- 편리함: 개발 과정에서 번거로운 새로고침 작업을 줄일 수 있습니다.
- 디버깅 용이: 코드 변경 사항의 영향을 실시간으로 확인하여 디버깅 작업을 용이하게 합니다.
- 생산성 향상: 개발 과정의 효율성을 높여 생산성을 향상시킬 수 있습니다.
HMR 사용 방법
HMR은 다양한 프로그래밍 언어와 프레임워크에서 지원됩니다. 일반적으로 다음과 같은 방법으로 HMR을 사용할 수 있습니다.
- 웹팩: webpack-dev-server와 같은 도구를 사용하여 HMR을 설정할 수 있습니다.
- React: react-hot-loader와 같은 라이브러리를 사용하여 HMR을 설정할 수 있습니다.
- Vue.js: vue-hot-reload-api와 같은 라이브러리를 사용하여 HMR을 설정할 수 있습니다.
HMR은 웹 개발 과정을 크게 효율화하고 시간을 절약할 수 있는 매우 유용한 기능입니다. 웹 개발을 하는 경우 HMR을 적극 활용하는 것이 좋습니다.
참고 자료
Webpack Hot Module Replacement: https://webpack.js.org/guides/hot-module-replacement/
React Hot Loader: https://github.com/gaearon/react-hot-loader
CSS
CSS (Cascading Style Sheets)는 웹 페이지의 시각적 디자인을 정의하는 스타일 시트 언어입니다. HTML은 웹 페이지의 기본 구조를 정의하지만, CSS는 웹 페이지를 더욱 아름답고 사용하기 편리하게 만들어줍니다.
CSS 동작 방식
CSS는 선택자와 속성을 사용하여 웹 페이지의 요소에 스타일을 적용합니다.
선택자: CSS 스타일을 적용할 대상을 선택하는 문자열입니다. 예를 들어, h1 선택자는 모든 h1 요소에 스타일을 적용합니다.
속성: CSS 스타일을 정의하는 정보입니다. 예를 들어, color 속성은 텍스트의 색상을 정의합니다.
캐스케이딩(계단식)
CSS는 계단식(cascading) 방식으로 작동합니다. 즉, 여러 개의 스타일 규칙이 동일한 요소에 적용될 경우, 가장 우선 순위가 높은 규칙이 적용됩니다.
캐스케이딩(Cascading)이란 ‘폭포같은, 계속되는, 연속적인’이라는 의미를 가진 단어인데, 이는 곧 ‘위에서부터 아래로 내려가며 이어진다’는 의미이기도 합니다.
참고자료
MDN Web Docs: https://developer.mozilla.org/ko/docs/Web/CSS
W3Schools: https://www.w3schools.com/css/
Khan Academy: https://www.khanacademy.org/computing/computer-programming/html-css
위키독스 https://wikidocs.net/190952
DNS(Domain Name System)
도메인 이름 시스템(Domain Name System, DNS)은 인터넷에서 도메인 이름을 IP 주소로 변환하거나, 그 반대로 IP 주소를 도메인 이름으로 변환하는 역할을 하는 시스템입니다. DNS는 전 세계적으로 분산되어 있는 계층적인 데이터베이스 시스템으로 구성되어 있으며, 네트워크에서 호스트 이름을 식별하기 위해 사용됩니다.
여기에서 DNS의 주요 기능과 작동 방식은 다음과 같습니다.
도메인 이름 해석
DNS는 사용자가 입력한 도메인 이름을 해당 도메인의 IP 주소로 변환합니다. 이를 통해 사용자는 도메인 이름을 기억하여 서버에 연결할 수 있습니다. 예를 들어, "example.com"이라는 도메인 이름은 실제로 IP 주소로 변환되어 웹 서버에 연결됩니다.
다른 예시로,
① 사용자가 "naver.com"과 같은 도메인 이름을 입력하면, 먼저
② 해당 도메인 이름을 해석하기 위해 로컬 DNS 캐시 또는 DNS 서버로 쿼리가 전송됩니다.
③ DNS 서버는 이 쿼리를 받아 해당 도메인 이름의 IP 주소를 찾습니다. 이후에,
④ DNS 서버는 "naver.com"의 IP 주소를 찾아 응답합니다. 이 IP 주소는 네이버의 서버를 가리키며, 이 IP 주소로 네이버의 서버에 연결됩니다.
위 과정을 거치고 나서 비로소, 해당 서버에서는 사용자의 요청을 처리하여 사용자가 볼 수 있는 네이버의 홈페이지를 제공합니다.
요약하면, DNS는 사용자가 입력한 도메인 이름을 실제로 호스팅되고 있는 서버의 IP 주소로 해석하여 사용자의 요청을 해당 서버에 전달합니다. 이를 통해 인터넷 사용자는 도메인 이름을 통해 서비스에 접속할 수 있습니다.
IP 주소 해석
DNS는 IP 주소를 도메인 이름으로 변환할 수도 있습니다. 이는 주로 IP 주소를 사용하여 호스트를 식별하는 경우에 유용합니다.
계층적인 구조
DNS는 계층적인 구조로 구성되어 있습니다. 최상위에는 전 세계적인 루트 DNS 서버가 있고, 그 아래에는 최상위 도메인(Top-Level Domain, TLD) 서버, 그 다음에는 도메인의 인가 서버가 있습니다. 이러한 계층 구조를 통해 DNS는 빠르고 효율적인 도메인 이름 해석을 가능하게 합니다.
| 전 세계적인 Root DNS 서버 |
| 최상위 도메인 서버(Top-Level Domain, TLD) |
| 도메인의 인가서버 |
캐싱
DNS는 캐싱을 통해 이전에 해석된 도메인 이름과 IP 주소를 저장합니다. 이를 통해 동일한 요청이 반복될 때 매번 동일한 서버에 새로운 질의를 보내지 않고 캐시된 정보를 사용하여 응답 속도를 높일 수 있습니다.
MX 레코드
DNS는 이메일 전송을 위한 MX(Mail Exchange) 레코드도 관리합니다. MX 레코드는 이메일을 수신하는 메일 서버의 주소를 지정합니다.
다시 말해, 이메일을 수신하는 메일 서버의 주소를 지정하는 DNS 레코드입니다. 이 레코드는 이메일을 전송할 때 수신자의 도메인에서 어떤 메일 서버가 해당 도메인의 이메일을 처리하는지를 지정합니다.
DNS 쿼리
DNS는 클라이언트가 도메인 이름을 IP 주소로 해석하거나, 반대로 IP 주소를 도메인 이름으로 해석하는 요청을 처리하기 위해 DNS 쿼리를 사용합니다.
참고자료
https://www.cloudflare.com/ko-kr/learning/dns/what-is-dns/
https://www.ibm.com/kr-ko/topics/dns
https://aws.amazon.com/ko/route53/what-is-dns/
선언적 | 결과를 명시하면 이를 시스템이 내부적으로 최적의 결과를 알아서 도출 vs 명령형 | 일일이 시스템에게 이거해라 저거해라 지시
"선언적(Declarative)"이라는 용어는 프로그래밍에서 특정 작업을 수행하는 대신 원하는 결과를 기술하는 방식을 가리킵니다. 이는 프로그래머가 어떤 작업을 수행하기 위해 명령어를 하나씩 나열하는 대신(이를 명령형이라 부름), 원하는 결과를 설명하면, 프로그램이 그 결과를 달성하는 방법을 사용자가 모르게 내부적으로 처리하도록 하는 것을 의미합니다.
선언적인 접근 방식은 명령형(imperative) 접근 방식과 대조적입니다. 명령형 프로그래밍에서는 컴퓨터에게 어떤 일을 어떻게 수행해야 하는지 세세하게 지시합니다. 반면에 선언적 프로그래밍에서는 원하는 결과만을 명시하고, 컴퓨터가 내부적으로 최적화하여 작업을 수행합니다.
예를 들어, 리액트에서 JSX를 사용하여 UI를 작성하는 것은 선언적인 방식입니다. JSX는 원하는 UI의 구조를 선언하고, 리액트는 해당 UI를 효율적으로 렌더링하는 방법을 처리합니다. 여기서, 개발자는 UI가 어떻게 렌더링되는지에 대해 명령할 필요가 없고, 단지 원하는 UI를 설명하기만 하면 됩니다.
이 외에도 HTML 마크업을 생성하여 브라우저가 화면에 렌더링하는 것도 선언적으로 이루어 집니다. 예를 들어 개발자가 다음과 같은 마크업 구조를 명시하는 경우 브라우저는 이를 해석해서 화면에 렌더링하게 됩니다.
<ul>
<li>Apple</li>
<li>Orange</li>
<li>Banana</li>
</ul>
정리하자면, 선언적 프로그래밍은 개발자가 특정 결과에 대해 설명하면, 해당 설명을 시스템이 개발자가 모르는 내부에서 최적의 방식으로 처리하여 결과를 보여주는 방식이라면
명령형 프로그래밍은 개발자가 특정 결과를 도출하기 위한 모든 과정의 절차를 시스템에게 지시하여 결과를 도출해내도록 하는 방식을 의미합니다.
참고하면 좋은 자료
JSON MDN https://developer.mozilla.org/ko/docs/Learn/JavaScript/Objects/JSON
aws smtp
https://aws.amazon.com/ko/what-is/smtp/
HTTP 1.0 등 설명을 잘해둔 블로그 https://oozoowos.tistory.com/entry/%EC%9B%B9-HTTP10-HTTP11-HTTP2-HTTP3-%EC%B0%A8%EC%9D%B4
'나만의 모음집' 카테고리의 다른 글
| 나중에 참고할 수도 있는 코드 모음집 (0) | 2024.05.08 |
|---|---|
| [모음집] Zustand 모음집 (0) | 2024.05.06 |
| [나만의 모음집] VSCODE 사용자 코드 조각 아카이브 (1) | 2024.04.30 |
| [명령어 모음집] 다양한 명령어 혹은 팁을 모아두는 아카이브 (0) | 2024.04.30 |
| git 명령어를 모아두는 아카이브 (1) | 2024.04.10 |

