해당 포스트는
- 현재 포스트는 나만의 명언집 프로젝트(NextJS 로 개발)의 코드를 개선하면서 얻은 산출물을 남겨두는 용도로 작성 되었습니다.
포스트 추가
server action 적용 전
- 클라이언트로 부터 서버로 요청이 전송되는데 0.21ms 걸림
- 서버로 부터 응답을 기다리는데 1.11초 걸림
- 서버로 부터 받은 콘텐츠를 다운로드 하는데 0.61ms 걸림

server action 적용 이후
- 클라이언트로 부터 서버로 요청이 전송되는데 0.37ms 걸림
- 서버로 부터 응답을 기다리는데 257.79ms초 걸림
- 서버로 부터 받은 콘텐츠를 다운로드 하는데 0.61ms 걸림
결과적으로
- 결과적으로, 1100ms−257.79ms=842.21ms(약 0.8초 ; 약 75.8%) 단축
포스트 수정
Server Action 적용 전
- 클라이언트로 부터 서버로 요청이 전송되는데 0.14ms 걸림
- 서버로 부터 응답을 기다리는데 1.25초 걸림
- 서버로 부터 받은 콘텐츠를 다운로드 하는데 0.56ms 걸림
Server Action 적용 후
- 클라이언트로 부터 서버로 요청이 전송되는데 0.17ms 걸림
- 서버로 부터 응답을 기다리는데 105.16ms 걸림
- 서버로 부터 받은 콘텐츠를 다운로드 하는데 6.77ms 걸림
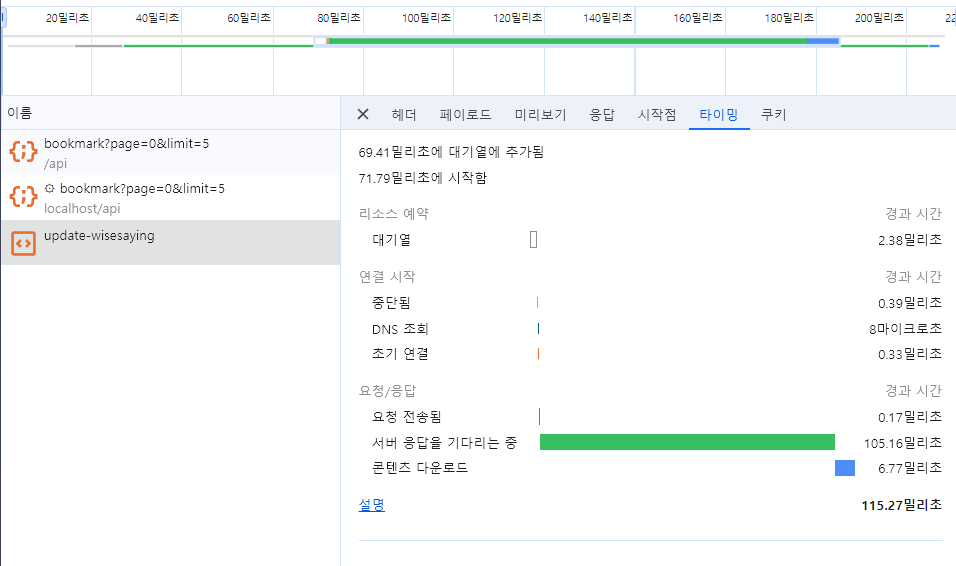
결과적으로
- 1250 ms - 115.27ms = 1137.73ms(약 1.135초; 약 90.78% ) 단축
포스트 삭제
Server action 적용 전
- 클라이언트로 부터 서버로 요청이 전송되는데 0.18ms 걸림
- 서버로 부터 응답을 기다리는데 723.91ms 걸림
- 서버로 부터 받은 콘텐츠를 다운로드 하는데 0.43ms 걸림
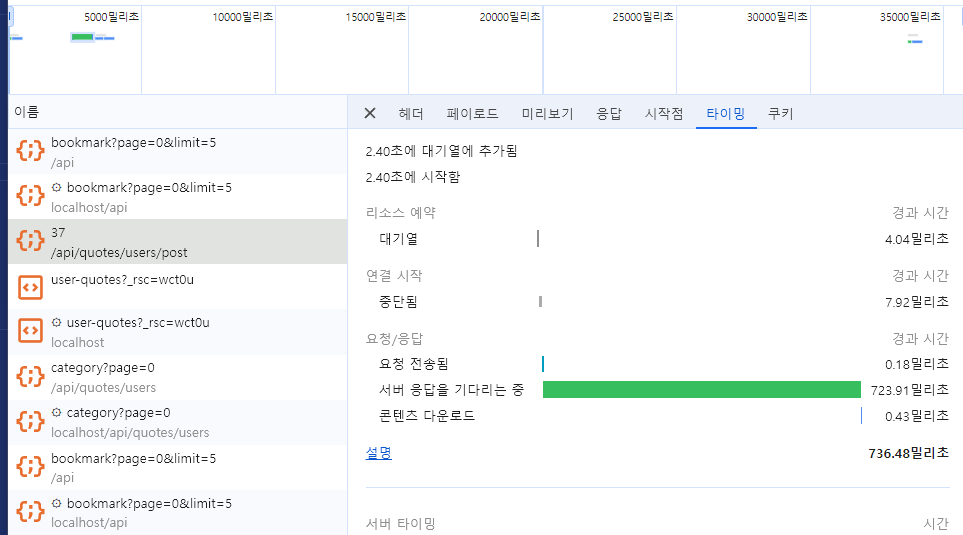
Server Action 적용 후
- 클라이언트로 부터 서버로 요청이 전송되는데 0.18ms 걸림
- 서버로 부터 응답을 기다리는데 209.75ms 걸림
- 서버로 부터 받은 콘텐츠를 다운로드 하는데 18.49ms 걸림
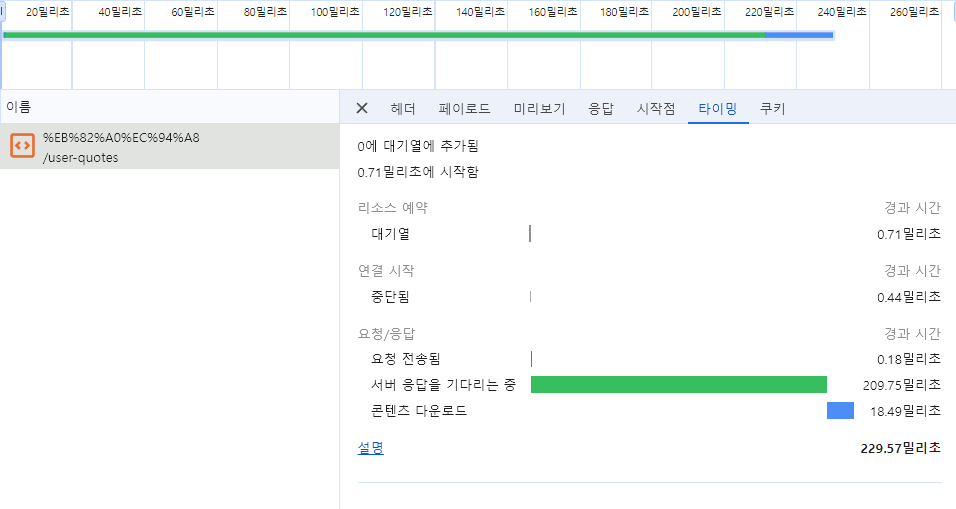
결과적으로
- 723.91ms - 209.75ms = 513.16ms(약 0.513초; 약 28.98% ) 단축
Home 페이지
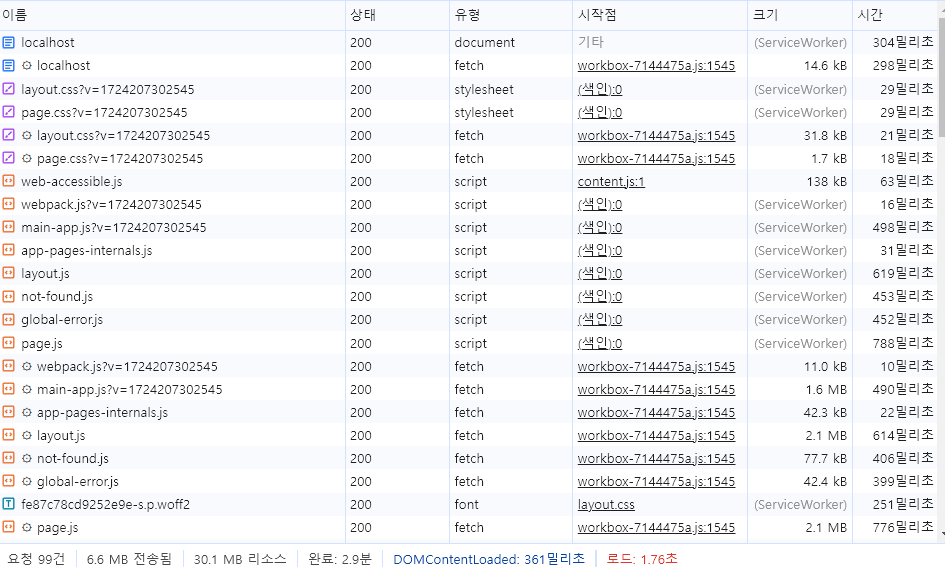
각 명언 세부 페이지 조회수 요청
현재 문제
각 명언 카드 마다 view 측정 카운트를 별도로 fetch 요청으로 불러오므로 요청되는 게시글의 수가 증가할 수록 전체 로드 시간이 점점 길어짐
요청 개수가 218 건 인 경우
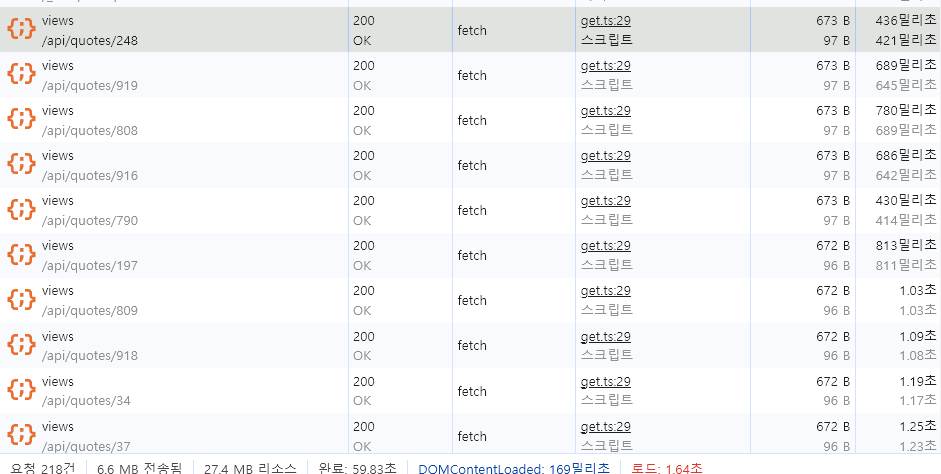
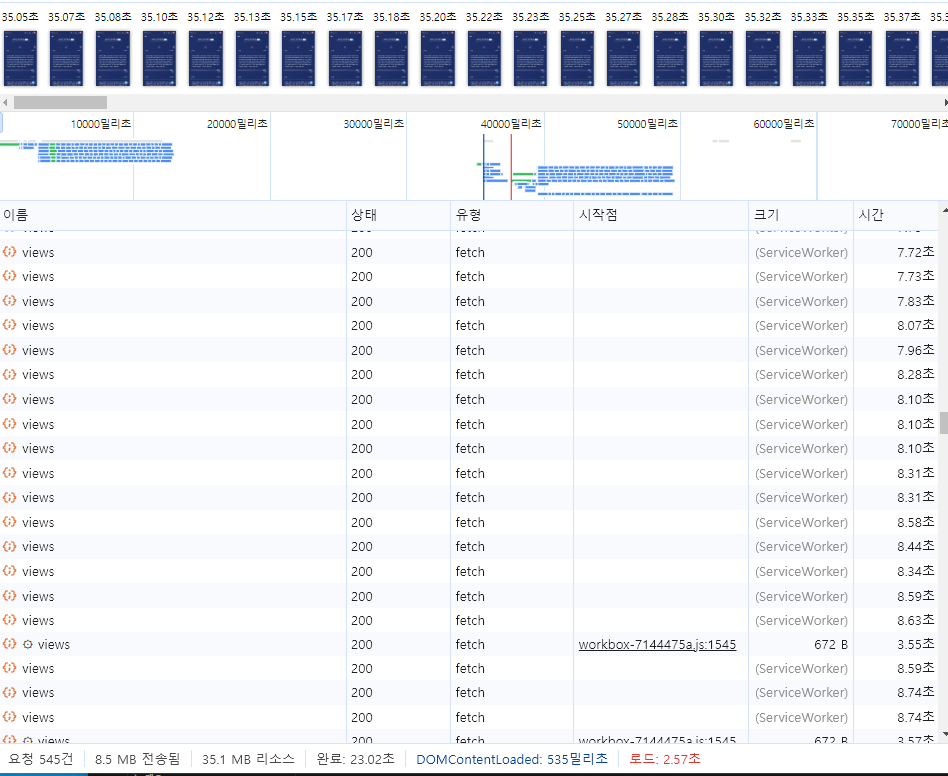
게시글의 수가 증가하여 요청 수가 545건이 되었을 때 로드 시간도 2.57초로 길어짐
현재 조회수 요청 서버 측 로직
기존 조회수 요청 로직
GET 요청 시 쿼리 스트링으로 받은 명언 별 id 로 조회수를 개별적으로 조회. 명언의 개수가 많을수록 그 개수 만큼 선형적으로 HTTP GET 요청이 발생
// GET | 명언 조회수 가져오기
export async function GET(req: NextRequest, res: { params: { id: string } }) {
const { id } = res.params || { id: 0 }
const db = await openDB();
try {
const selectQuery = ` SELECT views FROM views WHERE quote_id = $1 `
const selectResult = await db.query(selectQuery, [id])
const views = selectResult.rows[0]?.views || 0
return NextResponse.json({ ...HTTP_CODE.OK, views })
} catch (error) {
console.error('/api/quotes/[id]/views/route.ts', error)
return NextResponse.json(HTTP_CODE.INTERNAL_SERVER_ERROR)
} finally {
db.end()
}
}
변경된 로직
- 애초에 명언 테이블 조회시 views 테이블과 inner 조인하여 한 번에 응답 객체에 담아서 보내도록 수정
- 실질적으로 HTTP 요청이 선형적인 증가에서 최초 1회로 감소
export async function GET(
req: NextRequest,
res: { params: { category: string } },
) {
try {
const { category } = res.params
const limit = req.nextUrl.searchParams.get('limit') || 30
const limitNum = Number(limit)
const db = await openDB()
/** 명언 목록 */
if (category !== 'category-all') {
const page = req.nextUrl.searchParams.get('page') || 0
const pageNum = Number(page)
const query = `
SELECT A.quote_id, B.author AS author, quote, job, birth, intro, C.views AS view
FROM quotes A
INNER JOIN authors B ON A.author_id = B.author_id
INNER JOIN views C ON A.quote_id = C.quote_id
WHERE B.author = $1
ORDER BY A.quote_id DESC
LIMIT $2 OFFSET $3
`
const results = await db.query(query, [
category,
limit,
pageNum * limitNum,
])
const items = results.rows
console.log(items)
await db.end()
return NextResponse.json(items)
}
}
조회 시 다음과 같이 view 도 함께 조회되도록 개선
[
{
quote_id: 94,
author: '오손 웰스',
quote: '자신이 해야 할 일을 결정하는 사람은 세상에서 단 한 사람, 오직 나 자신뿐이다.',
job: '미국 배우',
birth: null,
intro: null,
view: 5
}
]

각 페이지별 카테고리

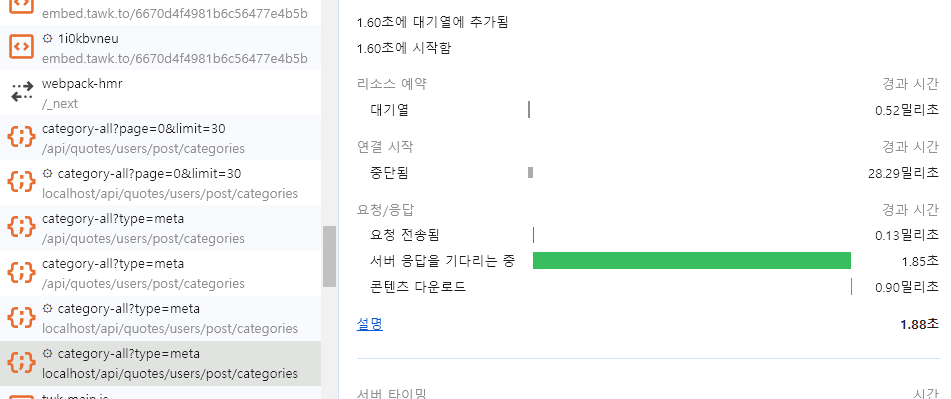
메타데이터 조회(현재 카테고리 수 / 전체 카테고리 수) ex. 사용자 명언 페이지

- 서버가 클라이언트의 요청을 처리하고 응답하는 데 까지 1.85초 걸림(오래 걸림)
- 클라이언트가 서버로 요청하는 데 걸린 시간은 0.13ms 걸림(적당)
- 서버로 부터 받은 콘텐츠를 다운로드 하는 시간은 0.90ms 걸림(적당)
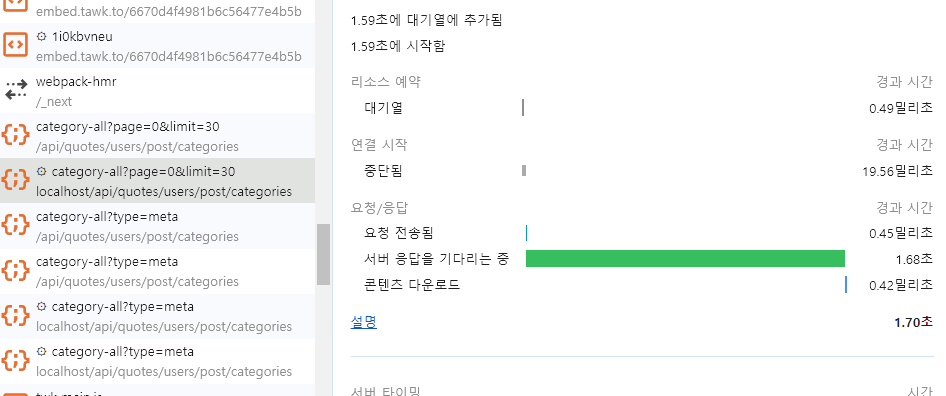
카테고리 목록 조회

- 서버가 클라이언트의 요청을 처리하고 응답하는 데 까지 1.68초 걸림(오래 걸림)
- 클라이언트가 서버로 요청하는 데 걸린 시간은 0.45ms 걸림(적당)
- 서버로 부터 받은 콘텐츠를 다운로드 하는 시간은 0.42ms 걸림(적당)
문제 및 개선 방향
- 서버 응답 대기 시간(1.85초): 전체 시간 중 가장 큰 부분을 차지 하며, 렌더링 할 데이터의 개수(명언 리스트의 길이)가 클수록 메타데이터를 요청하는 API 로직이 미치는 영향도 증가하는 것은 불가피
- 해당 데이터의 경우 굳이 클라이언트 측에서 조회할 필요가 없으므로 서버 측 렌더링 통해 미리 데이터를 렌더링하는 방향으로 개선
- API 요청을 제거하고, 즉시 조회할 수 있는 함수 구현 후 재사용
// metadata.ts
import { openDB } from '@/utils/connect'
import { QUOTE_CATEGORY_TOTAL_LIMIT } from '@/constants'
// 메타데이터 요청 타입
export enum Target {
USER_QUOTE_CATEGORY_ALL = 'USER_QUOTE_CATEGORY', // 명언 카테고리 메타데이터
USER_QUOTE = 'USER_QUOTE',
QUOTE = 'USER_QUOTE',
QUOTE_CATEGORY = 'QUOTE_CATEGORY',
}
export type QuoteMetaDataType = {
type: Target
category?: string
};
export async function getQuoteMetadata({ type, category }: QuoteMetaDataType) {
let query = ''
// 쿼리 분기처리
switch (type) {
case Target.USER_QUOTE_CATEGORY_ALL:
query = `
SELECT COUNT(DISTINCT category) AS count
FROM user_quotes
`
break;
case Target.USER_QUOTE:
query = `
SELECT COUNT(*) AS count
FROM user_quotes
WHERE category = $1
`
break;
case Target.QUOTE:
query = '/api/quotes/meta'
break;
case Target.QUOTE_CATEGORY:
query = '/api/quotes/category/meta'
break;
default:
throw new Error('요청 타입이 맞지 않습니다.')
}
// 조회
const db = await openDB()
try {
const result = category
? await db.query(query, [decodeURIComponent(category)])
: await db.query(query)
const TOTAL_COUNT = Number(result.rows[0].count) || 0
const MAX_PAGE = (Math.ceil(TOTAL_COUNT / QUOTE_CATEGORY_TOTAL_LIMIT))
return { maxPage: MAX_PAGE, totalCount: TOTAL_COUNT }
} catch (error) {
console.error('메타데이터 생성 실패:', error)
return false
} finally {
db.end()
}
}
'프로젝트 > 나만의명언집' 카테고리의 다른 글
| ec2 재부팅 시 사이트 접속 불가 (PostgreSQL, Nginx) (0) | 2024.07.31 |
|---|---|
| [나만의 명언집] GithubActions 을 통한 CI 와 AWS CodePipeline (CodeDeploy)을 통한 CD 구축 | NextJS 프로젝트를 EC2 인스턴스로 배포하는 과정 (0) | 2024.06.21 |
| WIndow 환경에서 Open SSH 로 접속 및 AWS EC2 인스턴스와 연결하기(+ 번외: SCP 사용해서 EC2 인스턴스로 파일 전송하기) (0) | 2024.06.18 |
| [나만의 명언집] 트러블 슈팅 모음집 ③ | 14 ~ 16 (1) | 2024.06.18 |
| 크롤링이 되긴 되었는데.. (0) | 2024.04.14 |



