오늘의 명언

포스트 목적
- 해당 포스트는 프로젝트 진행 시 구현한 기능 중 일부를 정리한 모음집 입니다.
- 포스트 순서는 기능 구현 개요 → 구현 과정 → 마무리(혹은 회고) 순으로 진행됩니다.
- 해당 포스트의 언어체는 '~였다.' 형식으로 작성됩니다.
[기능구현] 좋아요 기능
(기능 추가 이유 및 목적) 프로젝트를 진행하면서 좋아요 기능을 추가할 예정은 없었지만, 향후 사이트가 확장하여 보다 많은 명언 데이터를 가지게 되고, 어느 정도 활성화 되는 경우 어떤 데이터를 가지고 사용자에게 도움이 되는 정보를 제공할 수 있을지 고민하였다.
(결론) 이에 조회수와 좋아요를 기반으로 추천 명언을 보여주는 것이 제일 우선이 되어야 하는 기본이라 판단하여 해당 기능을 추가하기로 하였고, 이에 대한 기능구현 과정을 정리한다.
좋아요 로직
우선 좋아요 로직에 대해 나름 분석해보니 다음 시나리오에 따라 이루어질 것이라 짐작하였다.
① 사용자가 [좋아요] 아이콘 혹은 버튼을 클릭하면 사용자의 accessToken 과 해당 포스트 식별자(id) 를 서버 api 로 POST 요청한다.
② 서버에서는 accessToken 이 유효한지 확인하고, 유효한 토큰이 아니라면 접근 권한이 없다는 메시지와 함께 401 HTTP Code 를 응답한다.
③ 사용자가 접근 권한이 있다면, 해당 accessToken 의 페이로드에서 사용자의 id 정보가 담긴 sub 를 반환 받는다.
④ 앞서 클라이언트 측에서 전달받은 postId 와 토큰 검증을 통해 반환받은 사용자의 userId (= sub) 를 데이터베이스에 저장한다.
⑤ 이 때 데이터베이스에서 사용자의 좋아요 정보를 받아와서 클라이언트에 요청이 성공적으로 처리되었다는 201 코드와 함께 응답한다.
⑥ 클라이언트 측에서는 해당 좋아요 정보(좋아요 갯수, postId)를 응답받고, 응답 받은 postId 와 해당 포스트의 id 가 일치하는 경우에만 좋아요 갯수를 화면에 렌더링한다.
테이블 생성
원래 백엔드 단에서 이루어지는 테이블에 대한 정리를 해야 할까 고민했으나, NextJS 를 백엔드로 사용하는 특성 상 이에 대한 설명이 필요하다고 판단하여 이 부분을 추가하였다.
해당 기능 구현에서 사용된 테이블은 다음과 같다.
① quotes 테이블(명언 정보를 담고 있는 테이블)
명언 정보를 담고 있다. 여기서 quote_id 를 사용한다
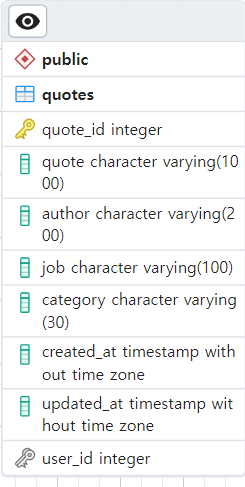
② quote_likes 테이블 (사용자의 좋아요 정보를 추적하는 테이블)

③ users(유저 정보를 담고 있는 테이블)
유저 정보를 담고 있다. 여기서 user_id 를 사용한다.

[참고] 해당 테이블은..
quotes_likes 테이블은 user_id 와 quote_id 를 담고 있는 quotes 와 users 테이블의 중간에서 매개 역할을 하는 테이블이다.
quote_likes 테이블과 users 테이블은 One To Many(일 대 다) 의 관계를 가지는데, quote_likes 테이블의 입장에서는 한 명의 유저를 가리키는 반면, users 테이블의 입장에서는 여러 개의 좋아요를 가질 수 있기 때문이다.
quote_likes 테이블과 quotes 테이블은 Many To Many(다 대 다)의 관계를 가진다. quote_likes의 각 좋아요 정보를 담고 있는 각각의 로우(행)가 가리키는 대상이 quotes 테이블에서 각 명언을 담고 있는 로우(행) 가 될 수 있고, quotes 테이블의 입장에서도 하나의 명언이 여러 개의 좋아요(→ 여러 사람이 좋아요를 클릭할 수 있으니까) 를 가질 수 있기 때문이다.
로직 작성
① 사용자가 [좋아요] 아이콘 혹은 버튼을 클릭하면 사용자의 accessToken 과 해당 포스트 식별자(id) 를 서버 api 로 POST 요청한다.
// /quotes/[category]/[name]/[id]/page.tsx
const onClickHandleLikeClick = () => {
const token = getAccessToken() || ''
if (token.length < 2) return
const url = '/api/quotes/' + id + '/like'
const config = {
method: 'POST',
headers: {
authorization: `Bearer ${token}`
}
}
fetch(url, config).then((response) => {
return response.json()
}).then((result) => {
const { meg, status, likeCount, quoteId } = result
if (status === 201) {
setLikeCount(likeCount)
setQuoteId(quoteId)
}
else alert(meg)
}).catch(error => {
console.error('좋아요 클릭 에러:', error)
})
}② 서버에서는 accessToken 이 유효한지 확인하고, 유효한 토큰이 아니라면 접근 권한이 없다는 메시지와 함께 401 HTTP Code 를 응답한다.
// /api/quotes/[id]/like
/* tokenVerify(req, accessToken | refreshToken) */
const { meg, status, success, user } = tokenVerify(req, true)
if (status === 400) {
return NextResponse.json({ status, success, meg })
}
if (status === 401) {
return NextResponse.json({ status, success, meg })
}③ 사용자가 접근 권한이 있다면, 해당 accessToken 의 페이로드에서 사용자의 id 정보가 담긴 sub 를 반환 받는다.
const { meg, status, success, user } = tokenVerify(req, true)
// ...중략
const { sub: userId } = user④ 앞서 클라이언트 측에서 전달받은 postId 와 토큰 검증을 통해 반환받은 사용자의 userId (= sub) 를 데이터베이스에 저장한다.
const insertQuery = `
INSERT INTO quote_likes(user_id, quote_id)
VALUES ($1, $2)
`
await db.query(likeCountSelectQuery, [quoteId])⑤이 때 데이터베이스에서 사용자의 좋아요 정보를 받아와서 클라이언트에 요청이 성공적으로 처리되었다는 201 코드와 함께 응답한다(주의할 점은 만일 해당 포스트에 해당 유저가 이미 좋아요를 클릭했다면, 해당 요청을 무시하도록 처리해야 한다.).
const checkSelectQuery =`
SELECT COUNT(*) as count
FROM quote_likes
WHERE user_id = $1 AND quote_id = $2
`
const insertQuery = `
INSERT INTO quote_likes(user_id, quote_id)
VALUES ($1, $2)
`
const likeCountSelectQuery = `
SELECT COUNT(*) as count
FROM quote_likes
WHERE quote_id = $1
`
const checkResult= await db.query(checkSelectQuery, [userId, quoteId])
const isLiked = checkResult.rows[0].count
if(isLiked>0) {
return NextResponse.json({meg:'이미 처리된 요청입니다.', status:409, success:false})
}
await db.query(insertQuery, [userId, quoteId])
const result = await db.query(likeCountSelectQuery, [quoteId])
const likeCount = result.rows[0].count
return NextResponse.json({ meg: '정상적으로 처리되었습니다.', status: 201, success: true, likeCount, quoteId })⑥ 클라이언트 측에서는 해당 좋아요 정보(좋아요 갯수, postId)를 응답받고, 응답 받은 postId 와 해당 포스트의 id 가 일치하는 경우에만 좋아요 갯수를 화면에 렌더링한다.
const showLikeCountQuoteIdMatch = Number(quoteId) === Number(id)
return (
<article className="absolute bottom-3 left-[43%] transform-x-[-50%] hover:shadow-[0_0_15px_3px_tomato] rounded-[10px] transition-shadow ">
<button onClick={onClickHandleLikeClick} className="text-[1.2em] flex items-center px-[15px] rounded-[10px] relative bg-[#fa5669]">
<HiHeart /><span className="mx-[2px]"> {showLikeCountQuoteIdMatch ? likeCount : 0}</span>
<span className="border-b-[5px] border-l-[10px] border-r-[10px] border-transparent border-t-[10px] border-t-[#fa5669] bottom-[-0.8em] left-[50%] translate-x-[-50%] absolute"></span>
</button>
</article>
)
[개선] 2024년 3월 4일 기준 변경점(해당 개선은 금일 이전에 이루어짐.)
위 기능 구현의 가장 큰 문제점은 사용자가 자신의 평가를 다시 취소할 수 없다는 점이었다. 따라서 이러한 문제를 개선하기 위해 추가적으로 아래의 로직을 추가하여 좋아요를 취소할 수 있도록 개선되었다.
// 실제 적용된 코드에서는 0을 기준으로 보지 않고 각 사용자가 해당 명언에 대한 좋아요 클릭 유무를 기준으로 처리하였습니다.
if (Number(isLiked) > 0) {
await db.query(deleteQuery, [userId, quoteId])
const result = await db.query(likeCountSelectQuery, [quoteId])
const likeCount = result.rows[0].count
return NextResponse.json({
meg: '평가를 취소합니다..',
status: 201,
success: true,
likeCount,
quoteId,
})
}
구현 결과(시연)
아래 시연은 기존 기능의 문제를 개선한 결과를 반영한 GIF 이다. 현재 까지는 큰 문제없이 동작하는 것을 확인할 수 있었다.
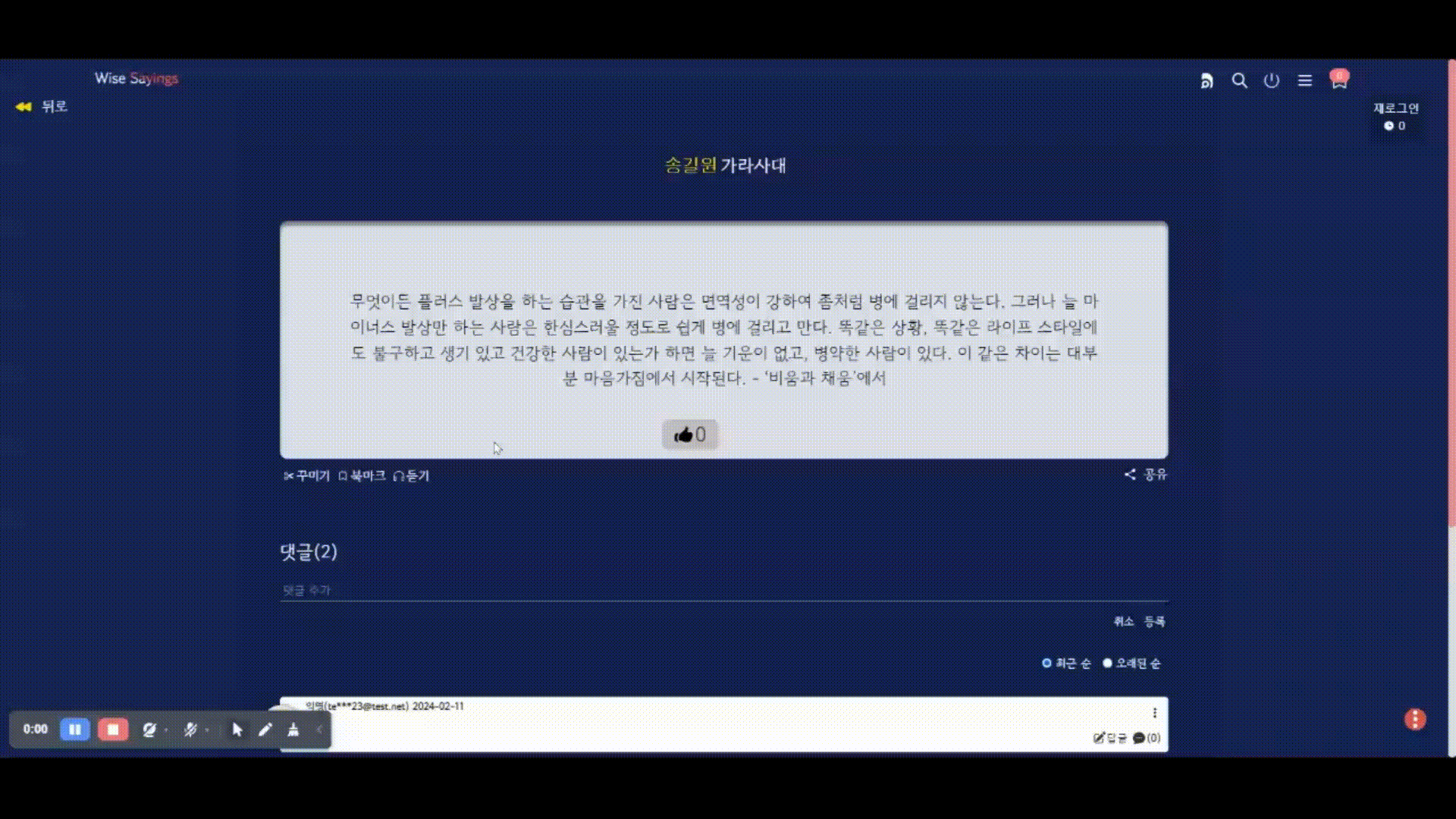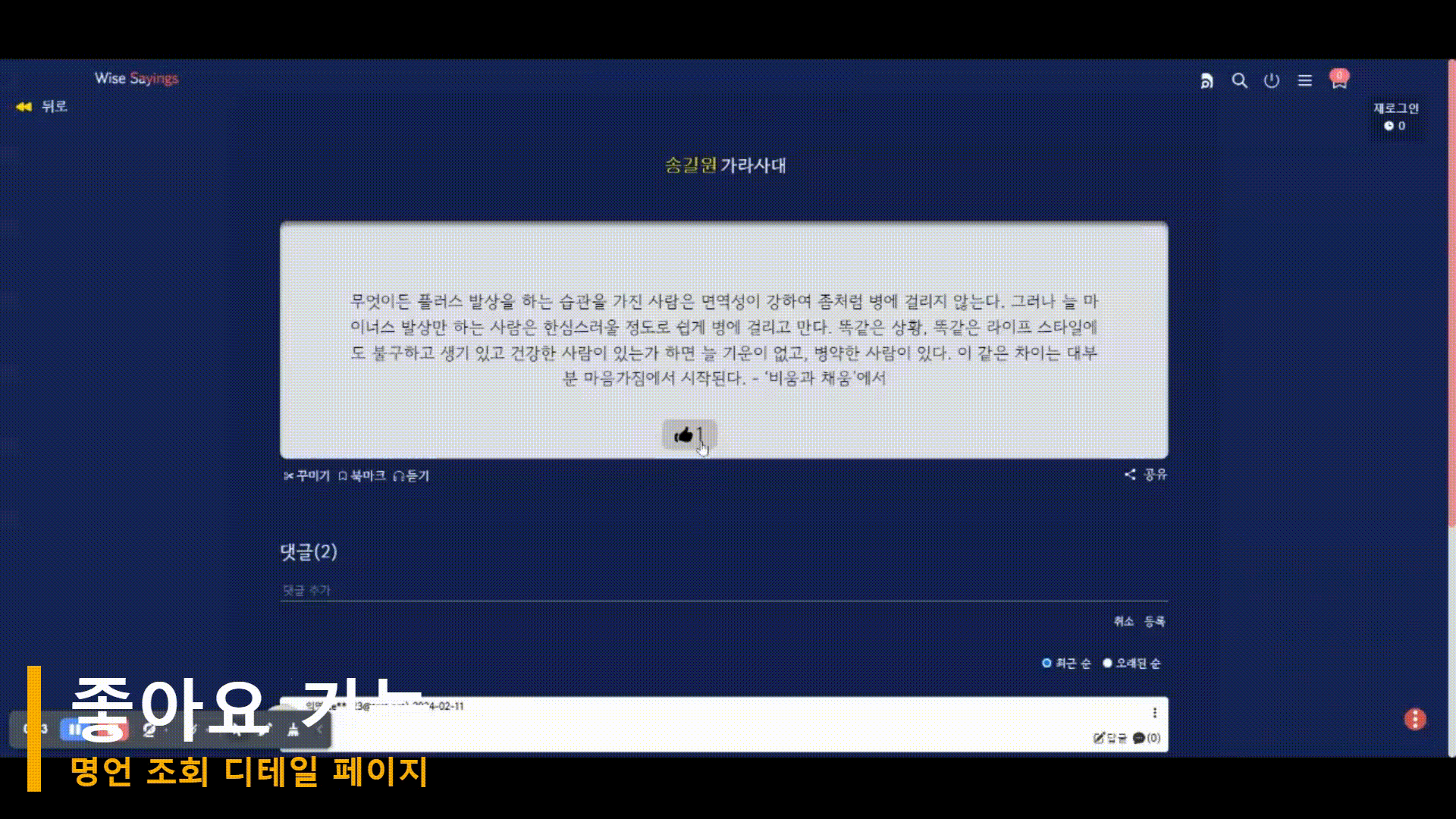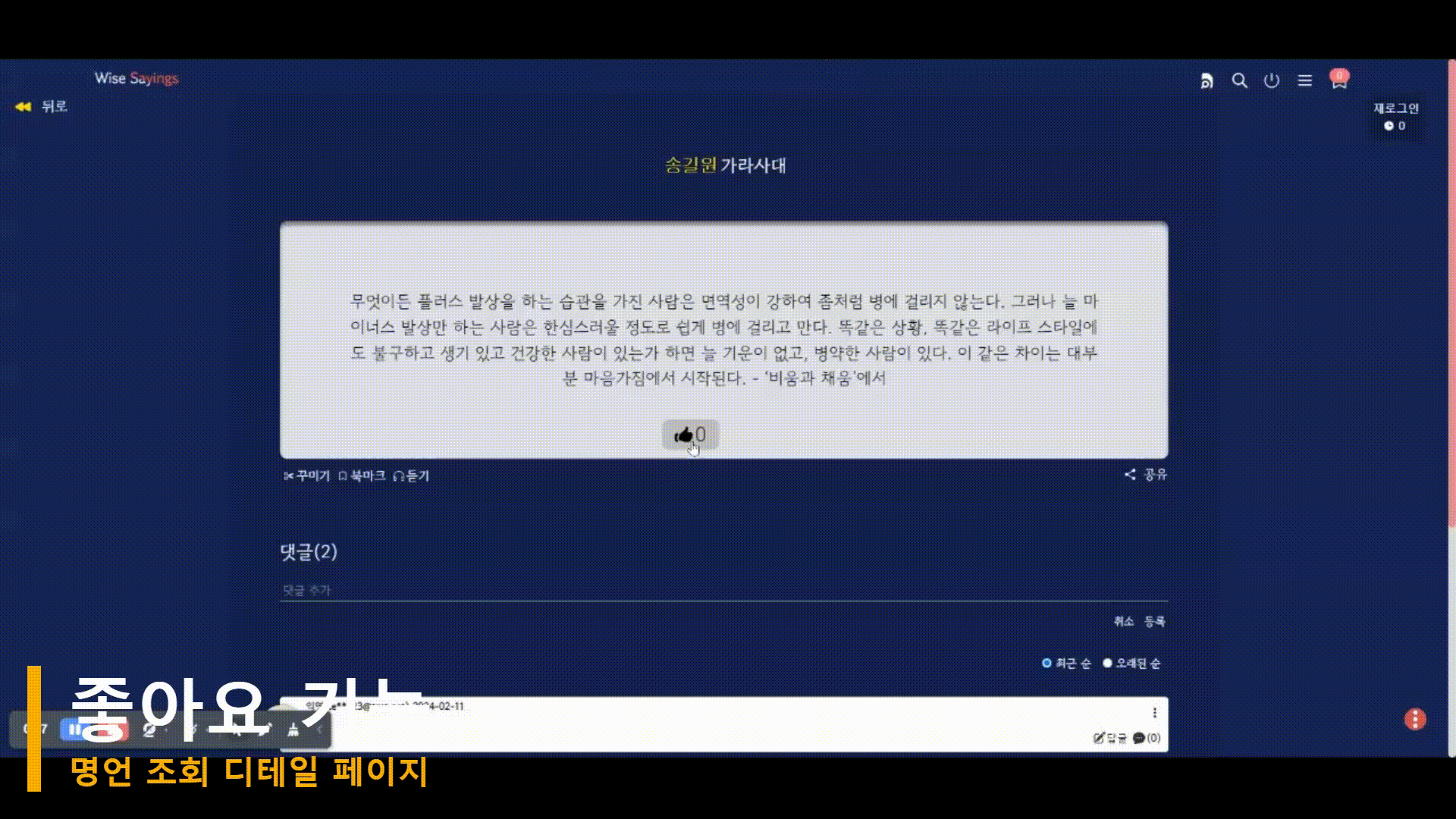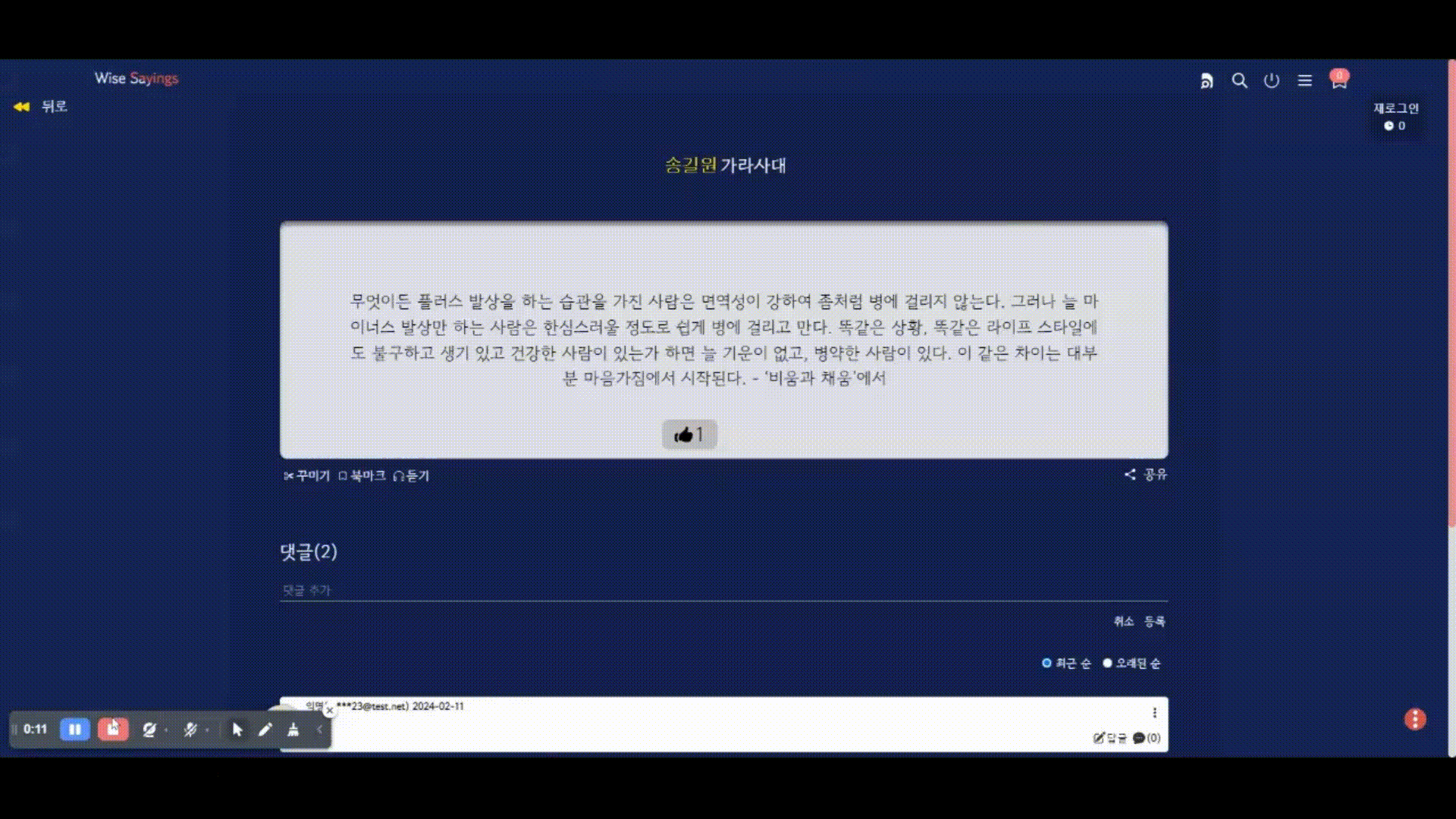
[마무리] 기능 구현 시 어려웠던 점?
왜 좋아요의 상태가 바로 업데이트 안 되는거지??..
좋아요 기능을 구현할 때 가장 어려웠던 점은 좋아요가 업데이트되고, 취소되는 그 과정이 사용자에게 바로 보이게 하는 일이었다. 이 부분을 원래라면 useSWR 과 뮤테이션을 적용하여 해결할까 고민도 했지만, 굳이 깊이 있는 컴포넌트 간에 거리가 있는게 아니라서 이렇게 하는 것은 너무 라이브러리를 남용하는 것 같아서 배제했다.
그래서 선택했던 방법은 백엔드 측에서 사용자가 좋아요를 클릭하면, 해당 좋아요가 반영된 최신 데이터를 조회하고, 그 데이터를 Response 객체에 담아서 클라이언트 측으로 응답하는 로직을 추가하기로 결정했었다.
여러 차례의 알고리즘 구상 및 반영, 수정, 삭제 등의 시도 끝에 결과적으로 기능 구현이 잘 되어서 현재는 위의 시연 영상과 같이 그 결과가 바로 되도록 했다.
다 대 다 테이블 설계가 뭐지?..
또한, 좋아요 기능의 특성상 다양한 사용자가 해당 기능을 사용할 수 있기 때문에, 테이블과 테이블 간의 관계가 어떠한지를 고려해서 데이터베이스 테이블을 설계해야 했는데, 평소에 프론트엔드의 NoSQL 를 사용했었기에 이에 대한 지식이 부족하여 추가적인 공부를 이어 나가야 하는 상황에 놓이기도 했다.
이렇게 직면한 어려움 속에서 배움의 기회가 주어졌다는 것은매우 재밌고, 즐거운 일이 아닌가 라는 생각이 들었다.
[기능구현] 전통적인 페이지네이션 기능 구현
(기능목적) 사용자가 많은 데이터를 하나의 화면에서 모두 본다는 것은 상식적으로 좋지 못한 사용자 경험을 제공하므로 이에 대한 문제를 사전에 방지하기 위해 페이지네이션 기능을 구현하였다.
(참고) 페이지네이션 관련 다양한 라이브러리가 존재하지만, 현 기능의 구현은 직업 코드를 알고리즘에 따라 구현하였다.
(개요) 해당 로직은 커서 기반이 아닌 전통적인 방식의 페이지네이션을 구현하는 과정을 정리한다. 전통적인 방식은 클라이언트에서 서버로 다음 페이지 정보를 전달하면, 서버에서 해당 페이지에 해당하는 데이터를 데이터베이스에서 조회하여 response 객체에 담아서 반환한다.
페이지네이션 로직
① 사용자가 페이지 버튼을 클릭하면 ,클라이언트 측에서 서버 측으로 다음 페이지에 대한 정보를 전달한다. (page=1)
② 서버 측에서는 해당 페이지 정보를 받아서 데이터베이스에서 데이터를 조회하고 반환한다.
이렇게만 본다면, 로직 자체는 단순하다. 단, 프론트엔드 화면에서 각 페이지를 렌더링하기 위한 별도의 로직을 필요로 한다
기능을 구현하기 위해서는 백엔드와 프론트엔드 모두에서 각각 관련 로직을 작성 후 처리해야 한다. 따라서 프론트엔드와 백엔드로 구분하여 각 각 어떻게 구현해 나갔는지 정리해 본다.
[프론트엔드] 로직 작성
① 구현에 사용된 알고리즘과 원리
현재 프론트엔드 페이지네이션에 사용된 로직은 페이지를 그룹 별로 나누고, 각 그룹에 따라 첫 번째 페이지(FirstPageNum)와 마지막 페이지(LastPageNum)를 다르게 하여 화면에 렌더링 되는 숫자가 그룹에 따라서 다르게 적용되는 일반적인 알고리즘이 적용되어 있다.
예를 들어, 한 번에 최대로 렌더링할 수 있는 페이지의 수(MAX_PAGE)를 5라고 정하고, 현재 페이지를 1, 전체 목록의 길이가 7 이라고 가정해보자
MAX_PAGE = 5;
currnetPage = 1;
itemsLength = 7
위 변수가 있을 때 해당 페이지의 그룹을 구한다면 아래 로직을 활용한다.
group = Math.ceil(currentPage / MAX_SIZE)
여기서, Math.ceil 은 자바스크립트에서 제공하는 내장 함수로서 1.1, 1.2 와 같은 소숫점을 가진 숫자가 있다면 이를 올림(ceil) 하여 2 를 반환하는 기능을 수행한다.
그럼 이를 활용해서 현재 페이지로 지정되어 있던 1 속한 그룹은 어디일까? 이를 구해보자

이게 끝이다. 이 알고리즘을 기반으로 최대 페이지가 넘어가는 시점에 렌더링되는 페이지의 번호를 업데이트 해주면 제일 단순하면서도 간단한 페이지네이션을 구현할 수 있다.
마지막으로 해당 페이지네이션을 구현하는 데 꼭 필요한 값들이 있다. 이는 렌더링 되는 페이지의 첫 번째 페이지에 해당하는 firstPage 와 마지막 페이지를 의미하는 lastPage , 모든 목록을 렌더링하고 난 뒤 해당 페이지가 실제 마지막 페이지인지 체크할 수 있는 limit 이다.

② 구현하기 | 상태 생성하기
원리를 살펴 보았으니 해당 페이지네이션을 실제로 구현해 볼 것이다.
우선 위에서 언급한 변수들을 선언한다. 이 때, 주의할 점은 리액트에서는 상수이거나 여러번 렌더링 할 필요가 없는 값은 const PAGE 혹은 useRef 를 사용해서 상태를 관리하는 것을 권장하는데, 여기서 우리가 사용하는 limit , firstPage, lastPage, pageGroup 은 모두 사용자가 페이지을 컨트롤 할 때 값이 유동적으로 바뀐다.
즉, 리렌더링 때 마다 새로운 상태로 업데이트 되고 그것이 화면에 바로 나타나야 하기 때문에 useState 을 사용하여 상태를 관리해야 한다.
이를 반영하여 각 상태를 생성하면 다음과 같다.
const [limit, setLimit] = useState(0)
const [firstPage, setFirstPage] = useState(1)
const [lastPage, setLastPage] = useState(0)
const [pageGroup, setPageGroup] = useState(1)
기본값으로 각각 0과 1을 준 이유는 undefined 관련 이슈를 초기에 방지하기 위해서 임의로 넣은 값이다.
③ 구현하기 | 초깃값으로 할당한 변수 선언 및 초기화하기
위에 useState 의 기본값음 임의값이고 실질적으로 사용될 값을 useEffect 내부에서 로직을 구현한다. 따라서
우선적으로 앞서 const 키워드를 사용한 예시와 같이 각 상태에 지정할 초깃값을 설정한다.
// 페이지 네이션 상태 초기 셋팅
useEffect(() => {
// 페이지 그룹 구하기
const pageGroup = Math.ceil((page + 1) / MAX_SIZE);
// 페이지 렌더링 제한 값 구하기
const limit = Math.ceil(count / MAX_SIZE);
// 마지막 페이지 구하기
const lastPage = pageGroup * MAX_SIZE;
// 첫 페이지 구하기
const firstPage = lastPage - (MAX_SIZE - 1);
}, [])
여기서 page 변수는 현재 페이지를 의미한다. page+ 1 이 된 이유는 서버에서 페이지네이팅을 수행할 때 page = 0 을 받아서 처리하지만 프론트엔드 에서는 화면에 표시되는 현재 페이지는 page+ 1 이 되는 값이어야 하기 때문이다.
lastPage 는 현재 보여지는 페이지네이션에 표시된 페이지의 마지막 페이지 번호를 의미한다. 현재 페이지 그룹이 1 이고, 최대 페이지 크기인 MAX_SIZE 가 5인 경우 1 * 5 = 5 가 되는데 이 값은 향후 페이지네이션를 렌더링 할 때 최대 길이로서 동작한다.

limit 는 페이지 렌더링을 제한할 값을 의미한다.
내부적으로 count 변수를 사용하여 값을 구하고 있는데, 여기서 count 는 총 목록의 길이 즉, 모든 페이지에 걸쳐서 렌더링할 수 있는 아이템의 총 갯수를 의미한다.
| 만일 목록 내 포함된 아이템의 수가 7개 이고, MAX_SIZE 가 5일 때 나눈 나머지가 1.2 가 되고 여기서 ceil 을 통해 2 라는 값을 얻을 수 있는데, 이는 최대로 그릴 수 있는 페이지의 수가 2가 최대라는 의미이다. |
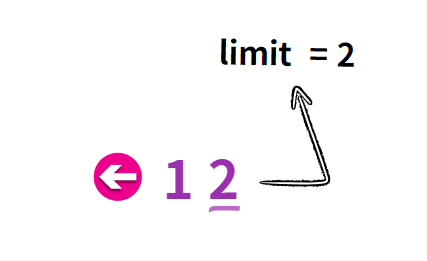
마지막으로 firstPage 는 용어 그대로 첫 번째 페이지를 의미한다. lastPage - (MAX_SIZE - 1); 을 살펴보면 lastPage 가 5 인 경우 MAX_SIZE 에서 -1 을 한 결과를 할당한다.
예를 들어, 페이지 그룹이 2가 되고, 마지막 페이지가 10이 된다면, 해당 그룹에서 첫 번째 페이지는 10 - (5-1) = 6 이 될 것이다.
③ 구현하기 | 페이지네이션을 렌더링하는 렌더러 함수 구현하기
현재 코드에서 사용되는 렌더러 함수는 아주아주 전통적인 for 문을 활용한다. 참고로, 구현하기에 따라서 slice 나 splice 를 사용하는 경우도 있으며, 복잡한 패턴을 가지는 페이지네이션은 특정 자료구조나 디자인 패턴을 적용하는 경우도 있다.
아무튼 렌더러 함수를 구현하면 다음과 같다.
// 페이지네이션 렌더러
const render = useCallback(() => {
const pageList: number[] = []
for (let i = firstPage; i <= lastPage; i++) {
pageList.push(i)
}
setPageList(pageList)
}, [firstPage, lastPage])
useCallback (→ 동일한 결과를 캐싱하여 리렌더링 시 상태를 업데이트하지 않고 기존 상태를 활용하는 동작을 수행함.) 이 붙은 이유는 하나의 useEffect 안에 연관성 있는 상태를 관리하기 때문에, 이로 인한 리렌더링 문제를 개선하기 위해 캐싱처리한 것이다.
앞서 언급했던 것 처럼 firstPage 와 lastPage 를 사용하여 최소로 그려야 하는 페이지의 번호는 firstPage 로 잡고, 최대로 그릴 수 있는 페이지의 수는 lastPage 를 사용하여 구현 하였다.
즉, firstPage 와 lastPage 사이에 렌더링 되는 i++ 값들이 실제 페이지네이션에 표시될 각각의 페이지 번호가 된다.
pageList 변수는 이러한 페이지 인덱스를 배열 형태로 보관하여, setPageList 를 통해 기존 상태를 한 번에 업데이트 할 때 사용된다.
| pageList 변수가 두 개인데 문제가 되는거 아니냐 라고 할 수 있다. render 함수 내부에서 pageList 변수를 선언하면 이름은 동일한 별개의 메모리 공간이 생성되므로 서로 다른 변수로 취급되어서 걱정할 필요는 없다. |
④ 구현하기 | 상태 업데이트 함수 구현하기
앞서 렌더러 함수 까지 구현하고 나면, 상태를 업데이트 하는 함수를 구현한다. 앞서 처음에 아래의 초깃값을 지정하는 각각의 변수를 생성하고 초기화하였는데, 이대로 두면 당연히 안 되고, setState 를 사용하여 기존 상태를 업데이트 해줘야 한다.
// 페이지 그룹 구하기
const pageGroup = Math.ceil((page + 1) / MAX_SIZE);
// 페이지 렌더링 제한 값 구하기
const limit = Math.ceil(count / MAX_SIZE);
// 마지막 페이지 구하기
const lastPage = pageGroup * MAX_SIZE;
// 첫 페이지 구하기
const firstPage = lastPage - (MAX_SIZE - 1);
이 때 주의할 점은 각각의 상태에 제 각기 실행되도록 해서는 안 되고, 하나의 업데이트 함수 내부에 상태를 업데이트할 수 있도록 해줘야 한다. 이는 나중에 적용할 페이지네이션을 렌더링할 때에만 상태 업데이트가 이루어질 수 있도록 하기 위함이기도 하고, 코드 가독성을 높이기 위한 목적도 크다.
따라서 상태를 업데이트 하는 함수를 구현하면 다음 형태와 유사해질 것이다.
// 상태 업데이트 함수
const updateState = (pageInfo: { [key:string]:number}) => {
const { pageGroup, limit, firstPage, lastPage } = pageInfo
setPageGroup(pageGroup);
setLimit(limit);
setFirstPage(firstPage);
setLastPage(lastPage);
};
여기서 매개변수 pageInfo 는 객체 {} 를 인자로 전달받는다. 또한, 각 키는 문자열이지만, 할당된 값은 숫자형이므로 { [key:string]:number} 와 같이 타입을 지정하였다.
⑤ 구현하기 | 상태 업데이트가 필요한 경우에만 렌더링 되도록 하기
이 부분이 제일 중요하다. 현재 하나의 useEffect 내부에 연관된 상태를 모두 가지고 있기 때문에, 잘못 관리하는 순간 대량의 리렌더링이 발생할 여지가 있다. 따라서 이를 예방하기 위한 조건을 추가한다.
// 필요한 경우에만 렌더링 함수 호출
if (page !== lastPage
|| count !== limit
|| firstPage !== lastPage - (MAX_SIZE - 1)
|| pageGroup !== Math.ceil((page + 1) / MAX_SIZE)) {
updateState({ pageGroup, limit, lastPage, firstPage });
render();
}
여기서 현재 페이지(page) 와 마지막 페이지(lastPage) 가 같은 경우는 만일 제한된 페이지의 수(limit)가 2이고, 마지막페이지도 2인 경우 현재 페이지 또한 2가 되는 상황(즉, 젤 마지막 페이지)을 의미한다. 즉, page === lastPage === limit 가 되는 지점이다. 이 경우에는 굳이 상태를 업데이트 할 필요가 없기 때문에 추가로 발생할 수 있는 렌더링을 차단한다.
count 는 서버에서 받아오는 총 목록의 갯수(총 길이)를 의미한다. 만일 총 목록이 1개 인 상태라면 limit 도 1이 되는 지점이기 때문에, 이 또한 불필요한 상태 업데이트가 이루어질 필요가 없으므로 리렌더링을 차단한다.
firstPage 와 lastPage - (MAX_SIZE - 1) 의 경우는 예상치 못한 에러를 차단하기 위해서이다. 이 조건을 추가하기 전에는 페이지네이션의 수가 -1 로 내려가는 문제가 발생하였는데(리액트만 사용하는 경우에는 없었던 문제) 이를 사전에 차단하기 위해서 조건으로 추가하였다.
pageGroup 도 마찬가지이다. 리는 firstPage 부분의 조건만 적용해도 문제가 발생하지 않았지만, 예기치 못한 문제가 발생할 여지를 사전에 차단하기 위해 마지막으로 추가하였다.
마지막으로 render 함수를 호출함으로써 화면에 페이지가 그려지도록 마무리 하였다.
⑥ 프론트엔드 페이지네이션 전체 로직
위에 설명한 전체 로직
const [limit, setLimit] = useState(0)
const [firstPage, setFirstPage] = useState(1)
const [lastPage, setLastPage] = useState(0)
const [_, setPageGroup] = useState(1)
const [pageList, setPageList] = useState<number[]>([])
// 페이지네이션 렌더러
const render = useCallback(() => {
const pageList: number[] = []
for (let i = firstPage; i <= lastPage; i++) {
pageList.push(i)
}
setPageList(pageList)
}, [firstPage, lastPage])
// 상태 업데이트 함수
const updateState = (pageInfo: { [key: string]: number }) => {
const { pageGroup, limit, firstPage, lastPage } = pageInfo
setPageGroup(pageGroup);
setLimit(limit);
setFirstPage(firstPage);
setLastPage(lastPage);
};
// 페이지 네이션 상태 초기 셋팅
useEffect(() => {
// 페이지 그룹 구하기
const pageGroup = Math.ceil((page + 1) / MAX_SIZE);
// 페이지 렌더링 제한 값 구하기
const limit = Math.ceil(count / MAX_SIZE);
// 마지막 페이지 구하기
const lastPage = pageGroup * MAX_SIZE;
// 첫 페이지 구하기
const firstPage = lastPage - (MAX_SIZE - 1);
// 필요한 경우에만 렌더링 함수 호출
if (page !== lastPage
|| count !== limit
|| firstPage !== lastPage - (MAX_SIZE - 1)
|| pageGroup !== Math.ceil((page + 1) / MAX_SIZE)) {
updateState({ pageGroup, limit, lastPage, firstPage });
render()
}
}, [page, count, lastPage, render]);
이를 기반으로 페이지네이션을 그리는 UI 를 개발 후 서버로 부터 데이터를 받아와 렌더링하면 기능 구현은 끝이다.
[백엔드] 로직 작성
본인의 경우 Next.JS(14.1) 를 사용하여 백엔드 로직을 구현하였다. 데이터베이스의 경우에는 PostgreSQL 을 사용하였고, 별도의 ORM 을 사용하지 않고 쿼리를 직접 작성하였다.
| ORM 을 사용하지 않은 이유는 기본적인 쿼리를 제대로 작성하지 못하면서 편리한 도구에 의존하는 것을 피하고 싶어서 이다. |
암튼 앞서 구현한 페이지네이션을 완성하려면 결국 데이터를 서버에서 처리하여 데이터베이스로 부터 필요한 데이터를 가져와서 응답을 해줘야 하므로 나머지 로직을 작성해 볼 것이다.
① 구현하기 | url 지정하기
프론트엔드에서 사용자가 아래와 같이 페이지를 선택했다고 가정해보자.

위 이미지 처럼 만일 1 페이지를 사용자가 클릭했다면, 프론트엔드에서 해당 페이지 번호는 특정 상태에 저장되어 api 서버로 전달될 것이다.
이 때 본인의 경우에는 해당 페이지 번호를 쿼리 파라미터에 담아서 보냈기 때문에, 다음 형태로 url 을 작성하였다.

잠깐 위 로직을 설명하자면,
hasToken 은 사용자가 로그인하였는지 판단하기 위한 것이며,
tapId 는 마이페이지에 존재하는 여러 탭 중에서 특정 탭을 식별하기 위한 id 값이다.
userId 는 현재 마이페이지에 접속한 유저를 구분하는 식별자 역할을 하는 것이고,
page 는 앞서 사용자가 페이지를 선택하면 해당 페이지 번호가 입력되는 파라미터 이다.
② 구현하기 | 백엔드에서 받은 데이터 처리하는 로직 작성하기(page, limit, userId)
앞서 url 을 통해 서버로 GET 요청을 보내면 서버에서는 해당 쿼리를 파싱하여 데이터를 읽어올 수 있다. NextJS 에서는 NextRequest 객체의 .nextUrl.searchParams.get() or getAll() 을 활용하여 읽을 수 있으며, 본인의 경우도 이를 활용하여 페이지 정보를 읽어왔다.

참고로 limit 의 경우에는 클라이언트 단에서 사용하는 limit 와는 다른 변수이다. 해당 변수의 경우에는 앞으로 작성할 Query(질의어) 에서 사용되는데, 데이터베이스로부터 읽어오는 데이터(여기서는 row)의 갯수를 제한하는데 사용된다.
③ 구현하기 | 쿼리 작성 및 데이터 조회하기
필요한 정보는 클라이언트로 부터 받아왔기 때문에, 데이터베이스로 부터 요청한 페이지의 목록을 조회하도록 쿼리를 작성 하였다.
const db = await openDB()
const query = `
SELECT quote_id AS id, author, quote, category, created_at
FROM quotes
WHERE user_id = $1
ORDER BY id DESC
LIMIT $2 OFFSET $3 * 5
`
부연 설명하자면, db 의 경우 postgres 데이터베이스와 백엔드 서버를 연결하는 connect 함수를 여러 모듈에서 재사용할 수 있도록 추상화 시킨 함수를 담은 변수이다.
query의 경우 quotes 라는 명언 정보를 저장하고 있는 테이블에서 특정 유저가 작성한 명언 정보를 조회하는 쿼리를 작성한 것이다. 각각에 사용된 문법에 대해 설명은 아래를 참고하면 된다.
| $1: 이는 사용자의 ID를 나타내며, WHERE 절에서 해당 사용자의 명언을 필터링하는 데 사용. $2: 이는 반환할 명언의 최대 개수를 제한하는 데 사용된다. 즉, 한 번에 반환되는 명언의 최대 개수를 제한하는 데 사용된다. $3: 이는 limit 에 담겨 있는 값이 전달되는 플레이스홀더를 의미하며, OFFSET을 계산하는 데 사용된다. 참고로, OFFSET은 결과 집합에서 건너뛸 레코드의 수를 나타낸다. 여기서 5를 곱하는 이유는 페이지네이션을 구현하기 위해서이다. 예를 들어, $3이 0이면 첫 번째 페이지의 명언을 반환하고, $3이 1이면 두 번째 페이지의 명언을 반환하게 한다. |
위 쿼리에서 주요한 역할을 수행하는 것은 아래 두 가지이다. 이에 대한 각각의 설명을 적어보았다.
| LIMIT : 한 번에 반환할 명언의 최대 개수를 제한. 이를 통해 한 페이지에 표시할 명언의 수를 제한할 수 있다. OFFSET: 결과 집합에서 건너뛸 레코드의 수를 지정한다. 페이지 번호와 페이지당 항목 수를 곱한 값이 여기에 사용된다. |
④ 구현하기 | 쿼리 실행 및 데이터 조회하기
위 쿼리까지 작성하고 나서 마지막으로 쿼리를 요청하여 조건에 일치하는 데이터를 반환받으면 된다.
const itemsResults = await db.query(query, [
userId,
limit,
pageNum,
])
const quotes = itemsResults.rows
그리고 반환 받은 데이터의 경우 다시 클라이언트로 응답하기 위해서는 NextJS 에서는 NextResponse 객체를 제공해주고 있으며, 본인의 경우에는 응답을 .json 메서드를 사용하여 응답하였다.
return NextResponse.json({
meg: '요청을 완료하였습니다.',
status: 200,
success: true,
quotes,
...
})
현재 기능의 문제점
다만, 현재 기능에서 가장 큰 문제점은 useSWR 의 사용 이점을 누리지 못하고 있는 점이다. 보통 사전로드 된 페이지가 존재하면 다음 페이지 버튼을 클릭하더라도 부드럽게 이동이 가능한데, 몇 번의 페이지 버튼을 클릭해야 프리로드된 데이터를 로드하도록 되어 있다. 이 부분은 향후 개선할 것이다(2024/03/04 기준) .
구현 결과

[마무리] 이번 기능 구현 시 어려웠던 점
환경 마다 같은 코드도 동작하는게 다르다.
전통적인 방식의 페이지네이션은 프로젝트 때 마다 구현해봤기에 쉬울 것이라 생각했지만, 매번 만들 때 마다 컴포넌트 구조나 깊이가 달라짐에 따라 미묘하게 발생하는 차이가 기능 구현을 매우 어렵게 했다.
즉, 기본 자바스크립트에서 되었던 기능이 리액트에서는 사이드 이펙트 문제로 오작동하고, 리액트에서는 적용되었던 기능이 NextJS 에서는 서버 컴포넌트와 클라이언트 컴포넌트 간의 관계가 그 미묘한 간극을 일으켰다.
그럼에도, 그 차이를 이해하고, 다시 그 상황에 맞는 코드를 작성할 때 마다 예전보다 더 효율적인 코드가 작성되고 있다는 생각이 들었고, 조금 씩 이나마 성장하고 있다는 생각이 들어서 값진 경험이 아니였나 싶다.
[기능구현] [버튼형] 무한 스크롤
(기능 목적) 현재 프로젝트의 주요 특징은 방대한 카테고리 및 명언 데이터를 사용자가 가볍게 스크롤해도 확인할 수 있도록 한다. 이 때, 버튼형으로 무한 스크롤을 구현한 목적은 사용자가 다음 페이지가 로드 되기 전에 해당 페이지에 로드된 명언 카드에 집중할 수 있도록 배려하기 위해서이다.
(개요) 이번에 구현한 기능은 페이지 기반 무한 스크롤이다. 무한 스크롤도 커서 기반과 전통적인 방식의 페이지 무한 스크롤이 존재하는데, 적용한 방식은 페이지 기반 무한 스크롤 중에서도 버튼을 클릭하면 새로운 데이터가 로드되는 방식을 활용하였다.
| 버튼형으로 구현한 이유는 사용자가 필요에 의해서 새로운 데이터를 로드할 수 있도록 하여 현재의 화면에 렌더링된 명언 카드에 주의를 집중할 수 있도록 유도하기 위한 의도 때문이다. |
또한 이번 무한스크롤에 사용된 라이브러리는 SWR 에서 제공하는 useInfiniteScroll 을 활용하였다. 해당 훅은 getKey 함수를 사용하여 요청할 페이지와 이전 페이지 데이터를 기반으로 다음 페이지에 대한 요청을 서버로 전달하고, 서버에서 전달받은 아이템을 배열 형태로 만들어 반환하는 기능을 수행한다.
버튼형 무한 스크롤의 로직
버튼형으로 동작하는 무한 스크롤은 크게 보면 3 단계로 구분되는 것 같다. 이를 적어보면 다음과 같다.
① 사용자가 페이지 최하단으로 스크롤 한다.
② 하단의 [더보기] 버튼을 클릭하여 새로운 데이터를 로드한다.
③ 1과 2의 동작을 반복한다.
로직 작성
① 구현하기 | SWR 설치 및 hook 가져오기 외 기본셋팅
우선적으로 제일 필요한 라이브러리인 swr 을 설치해야 한다.

그 다음에는 해당 훅 사용의 튜토리얼에 나온 사용 방식대로 기초적인 토대를 설정하면 된다.

본인의 경우에는 필요에 맞게 다음과 같이 지정하였다.

[참고]각 옵션에 대한 설명을 대략적으로 해보자면,
- data 는 말그대로 서버에서 응답받은 데이터가 담겨 있고
- isLoading 은 서버로 부터 최초로 데이터를 받아오기 까지의 상태를 나타내며
- size 는 현재 페이지
- setSize 는 다음 페이지를 설정하는 setState 함수이다.
- getKey 는 내부적으로 매개변수를 두 가지(페이지 인덱스, 이전 페이지 데이터) 받는 함수 로서 일반적인 useSWR 에서 key 에 해당하는 함수이다. 즉, 이 함수가 최종적으로 반환하는 값이 해당 훅을 식별하는 Key 값이 된다.
- getInfiniteFetcher 는 서버로 데이터를 요청하는 fetch 함수로서 fetcher 라고 불린다.
② 구현하기 | getkey 구현하기
앞서 getKey 는 내부적으로 매개변수를 두 가지 받는 함수로서 Key 에 해당하는 역할을 수행한다고 하였는데, 본인이 해당 함수를 구현한 전체 코드를 보면 다음과 같다.
// 데이터 식별 키(해당 키를 기반으로 fetch 함수에 url 을 공급하고, 키에 변동 사항이 생기면 서버에서 데이터를 불러온다.)
const getKey = (pageIndex: number, previousPageData: any) => {
if (previousPageData && !previousPageData.length) return null // 끝에 도달
let url = ''
switch (mainCategory) {
case 'topics':
case 'authors': {
url = `/api/quotes/${mainCategory}/${subCategory}?page=${pageIndex}&limit=15`
break
}
case 'users': {
url = `/api/quotes/${mainCategory}/post/categories/${subCategory}?page=${pageIndex}&limit=15`
break
}
}
return url
}
위 코드에서 주요한 부분만 설명하면 다음과 같다.
우선, getKey 의 매개변수를 보면, pageIndex 와 previousPageData 를 받는 것을 볼 수 있다. 이는 각각 업데이트 할 페이지의 인덱스와 이전 페이지의 데이터를 나타낸다.
여기서 pageIndex 는 사용자가 다음페이지를 나타내는 버튼이나 [더보기] 를 클릭하는 경우 setSize 를 통해 전달되는 size 와 동일하다.
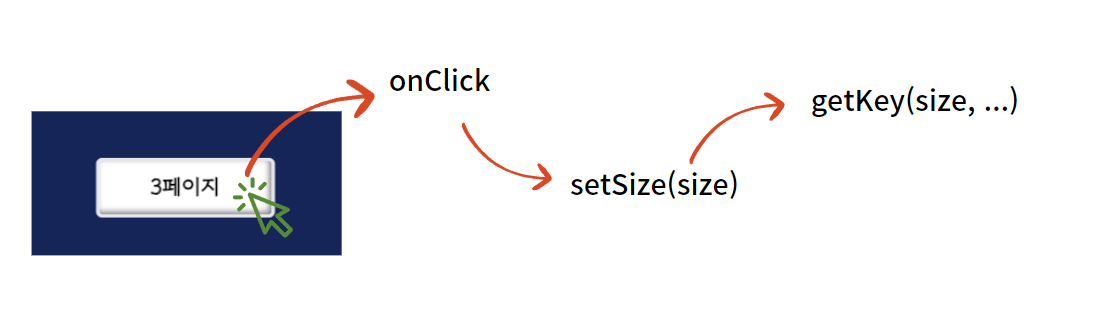
다음은 아래 조건식 부분 인데, previousPageData 는 setSize 를 통해 설정한 pageIndex 를 기반으로 다음 페이지 정보를 가져오는 경우 그 이전 페이지 기반으로 가져온 데이터(과거 데이터) 를 보관하는 캐싱 변수라고 보면 된다. 이 변수는 더 이상 반환할 데이터가 없으면 빈배열 [ ] 을 반환하기 때문에, 이전 데이터가 존재하지만, 그 데이터의 길이가 0 이라면 더 이상 가져올 데이터가 없다고 가정하여 null 을 반환한다.
if (previousPageData && !previousPageData.length) return null

마지막은 url 을 반환하는 로직을 살펴보자.
| * 아래는 본인의 편리성에 따라서 아래와 같이 정의 했지만, 보다 효율적이고 좋은 코드가 있다면 거기에 맞춰서 작성하면 된다. * 참고로 case 문의 마지막에는 break 를 지정하지 않아도 된다. * 만일 케이스와 일치하지 않는 경우 default 를 지정하여 반환하는게 좋다고 하는데, 굳이 그럴 필요성이 없어 보여서 배제했다. |
여기서 잠깐 언급할 것이 있는데, 앞서 getKey 는 훅의 key 역할을 수행한다고 했다. 여기서 key 는 해당 훅을 식별하는 데 사용되는 특수한 속성으로서 SWR 에서는 기존적으로 해당 키를 url 로 지정한다.
즉, 아래 로직은 서로 다른 api 경로에 따라 case 로 처리한 후 반환된 값을 url 에 담아서 반환하는 것이다.

사실 이 부분이 제일 중요하다. 해당 키가 제대로 훅을 식별하지 못한다면 구현된 훅은 캐싱, 데이터 페치 등의 동작을 수행하지 않기 때문이다.
③ 구현하기 | fetcher 함수 구현하기
이번에는 서버로 부터 데이터를 가져오도록 요청하는 fetcher 함수를 구현한다. 해당 함수는 기본적으로 우리가 알고 이는 axios 나 fetch 등을 사용하여 GET, POST, PUT, PATCH, DELETE 와 같은 HTTP 요청을 처리한다.
이를 구현한 함수의 전체 로직은 다음과 같다.
export async function getInfiniteFetcher(url: string) {
try {
const response = await fetch(url)
const items = await response.json()
return items
} catch (error) {
console.error('GET 리스트 조회 실패:', error)
}
}
여기서 주요하게 볼 부분은 url 이다. 앞서 getKey 함수가 호출되어 반환된 키(Key)인 URL 이 첫 번째 매개변수로 전달되고, fetcher 함수는 이를 처리하여 서버에 데이터를 요청하게 되고, 응답 받은 데이터를 반환하면, 훅에서 해당 데이터를 배열 형태로 반환해주게 된다.
예를 들어, size = 1 이 될때, url 은 page = 1 이라는 정보를 받아서 서버에 데이터를 요청하고, 서버는 해당 정보를 바탕으로 1 페이지에 대한 정보를 조회하여 클라이언트로 반환한다.
그 후 fetcher 내부에서는 응답받은 데이터를 return 으로 반환하고, 해당 데이터는 swr 내부적으로 처리되어 배열 형태로, data 변수에 할당되어 반환된다.
이 때 사용자가 다음 페이지인 size = 2 를 요청하면, url 에 page = 2 가 전달되고, 서버에서는 해당 데이터를 반환하게 한다.
| → 여기서 size =1 에 대한 데이터(이전 데이터)는 swr 내부적인 처리로 캐싱처리 되어있다가, size = 2 로 전달받은 새로운 데이터를 내부적으로 [page1, page2] 와 같이 배열 형태로 생성한다. 그리고 이를 반환하는 것이 swr에서 제공하는 data 변수인 것이다. |
단, 이대로 데이터를 사용한다면, [ [ ], [ ] ] 와 같이 배열 안에 배열이 들어있는 중첩 배열이 생성된다.
이대로 사용한다면, 반환된 데이터를 렌더링 하는데 많은 노력이 소요되므로 이를 평탄화하여 하나의 배열 형태로 만들어주는 처리가 필요하다.
즉, 바로 아래와 같은 처리가 필요하다.

[참고] 그 외 기본적인 fetch 동작이 궁금하다면?
fetch 는 기본적으로 GET Method 를 사용하기 때문에 전달받은 url 에 대한 GET 요청을 서버로 보내게 된다.
그리고 반환되는 값은 Promise 객체로서 Pending 상태를 반환한다. 따라서 async ~ await 이나 then 체이닝을 통해 이행 상태로 변경해야 한다.
또한, 데이터의 경우 JSON 형태로 직렬화되어 오는데, 이를 Response 에서 제공하는 .json() 메소드를 사용하여 역직렬화 해야 원본 데이터를 받아올 수 있게 되고, 이를 items 변수에 할당할 수 있게 된다.
참고로 직렬화는 기존 환경에서 사용 가능한 데이터를 다른 환경에서도 재사용할 수 있도록 문자열과 같은 형태로 변환해주는 것을 의미한다.
역직렬화는 반대로 직렬화된 문자열 데이터를 해당 환경에서 사용할 수 있는 형태로 변환하는 과정을 의미한다.
④ 구현하기 | 받아온 데이터를 후처리하는 로직 작성하기
여기서 후처리는 서버로 부터 받아온 데이터를 가공하여 뿌리기 위한 작업을 의미한다. 앞서 fetcher 로 받아온 데이터는 일차적으로 data 배열에 담겨서 오지만 중첩 배열의 형태이므로 이대로 사용하기에는 무리가 있다.
따라서 후처리를 통해 중첩 배열을 하나의 배열 형태로 병합하는 과정을 처리해야 한다.
아래 로직은 본인이 사용한 로직의 일부이다.
// 일부 로직 참조) https://swr.vercel.app/ko/examples/infinite-loading
// (참조 전 이전 로직)const items = itemInfo ? itemInfo.flatMap((item)=> { return item} ) : null
const items = itemInfo ? [].concat(...itemInfo) : null
const itemCount = items?.length || 0 // 현재 로드 중인 아이템 갯수
const isLoadingMore =
isLoading ||
(size > 0 && itemInfo && typeof itemInfo[size - 1] === 'undefined')
각 로직에 대해서 자세하게 설명하자면,
const items = itemInfo ? [ ].concat(...itemInfo) : null 의 경우 itemInfo가 존재하면(참 값으로 평가될 경우) 모든 itemInfo 배열 내의 항목들을 하나의 배열로 결합한다. 그렇지 않으면 items에 null을 할당한다.
| concat 에 대해 부연 설명하면, 해당 메서드는 기존 배열에 인자로 전달받은 배열을 병합하여 하나의 배열로 만들어서 반환해준다. Array.prototype 에 정의된 메서드로서 모든 배열은 이를 상속 받아 사용할 수 있게 되므로 [ ] 배열 객체에 접근하여 사용할 수 있다. |
const itemCount = items?.length || 0 는 items 배열의 길이를 확인하여 itemCount 변수에 할당한다. items가 존재하지 않거나 null이면 0을 사용한다.
const isLoadingMore = isLoading || (size > 0 && itemInfo && typeof itemInfo[size - 1] === 'undefined') 은 isLoading이 true이거나, 혹은 (size > 0)이면서 itemInfo가 존재하고, itemInfo 배열의 마지막 요소가 undefined인 경우 isLoadingMore 변수에 true를 할당토록 한다. 이 때, 반환된 boolean 값은 사용자가 더보기 버튼을 클릭시 로딩중... 이라는 표시를 확인할 수 있도록 하는데 사용하였다.
⑤ 구현하기 | 마지막으로 구현된 변수 사용하기
여기 까지 왔으면 무한 스크롤에 필요한 모든 데이터를 준비하였고, 이제 이를 반환하여 필요한 곳에서 적용하기만 하면된다.
본인의 경우에는 해당 무한 스크롤 로직을 다양한 곳에서 재사용하기 때문에 useInfiniteScroll 이라는 커스텀 훅을 생성하여 그 내부에 무한스크롤 로직을 구현하였다.
따라서 다음과 같이 return 하여 useInfiniteScroll 를 import 하여 사용한다.
// useInfiniteScroll.tsx
return { items, isLoading, size, setSize, isLoadingMore, itemCount }// QuotesCategoryList.tsx
import useInfiniteScroll from '@/custom/useInfiniteScroll'
//SWR INFINITE | 저자 목록을 가져온다.
const {
items,
size,
setSize,
isLoading,
isLoadingMore,
itemCount: currentCount,
} = useInfiniteScroll(`${category}`, 'category-all')
여기서 다시 한 번 각 변수를 정리하면
items 는 렌더링할 아이템 목록, size 는 페이지 인덱스, setSize 는 새로운 페이지 인덱스를 지정, isLoading 은 최초로 서버에서 데이터를 가져올 때의 상태 정보를 담은 변수, isLoadingMore 를 사용자가 새로운 페이지 정보를 가져올 때 까지 대기 상태를 나타내는 변수, itemCount 는 현재 로드된 아이템 갯수를 담고 있는 변수이다.
본인의 경우에는 앞서 언급했듯이 switch 를 사용해서 각기 다른 api 경로로 GET 요청을 보내기 때문에, 필요한 각 정보를 훅의 인자로 담아서 전달하고 있다.
⑥ 구현하기 | 로드 버튼 만들기
앞서 로직을 작성하였고, 화면에 데이터를 렌더링하는 데 까지 구현하였다면, 로드 버튼을 구현해야 한다. 해당 버튼의 역할은 사용자가 버튼을 클릭하면 setSize 가 호출되어 기존 size 의 상태를 새로운 상태로 업데이트하고 그 값을 getKey 로 전달하는 것이다.

따라서 구현한 로드 몰 버튼의 컴포넌트 로직 중 주요 부분은 다음과 같이 정리해 보았다.
import { MouseEventHandler, useEffect, useState } from 'react'
interface PropsType {
onClickSetSize: MouseEventHandler<HTMLButtonElement>
size: number
maxPage: number
isLoadingMore: boolean
}
export default function ListLoadMoreButton({
size,
maxPage,
isLoadingMore,
onClickSetSize,
}: PropsType) {
const [isLastPage, setIsLastPage] = useState(false)
useEffect(() => {
setIsLastPage(size === maxPage)
}, [size, maxPage])
return (
<button
onClick={onClick}
>
{isLastPage
? '마지막 페이지'
: isLoadingMore
? '조회중 입니다...'
: size + '페이지'}
</button>
)
}
여기서 maxPage 는 최대 페이지 사이즈를 나타내는 변수로서 현재 페이지가 마지막 페이지인 경우를 표시하기 위해 사용되었다. 또한 당 데이터는 별도의 api 경로에서 처리되어 가져온 데이터 이므로 이번 구현에서 언급을 배제하였다.
isLoadingMore 은 로딩 스피너를 구현하는 데 쓰이는데, 본인의 경우에는 버튼의 텍스트를 교체하여 로딩 상태를 표시하도록 구현하였다.
중요한 것은 사용자가 onClick 이벤트를 호출했을 때 이루어지는 동작인데, 해당 이벤트의 처리는 버튼의 상위 컴포넌트에서 아래와 같은 형태로 prop 으로 전달된다. setSize 를 호출해서 기존 size 를 새로운 상태로 업데이트하는게 전부이며, 이를 통해 새로운 데이터를 계속해서 로드해 올 수 있다.
<LoadMoreButton
onClick={() => setSize(size + 1)}
size={size}
isLoadingMore={isLoadingMore}
maxPage={MAX_PAGE}
/>
구현 결과
[마무리] 이번 구현에서 어려웠던 점
후처리 해야 할 로직이 복잡했던 점
swr 라이브러리에서 제공하는 무한 스크롤 전용 훅을 사용하여 무한 스크롤 기능을 구현해보았는데, 해당 기능 구현에서 가장 어려웠던 점은 서버에서 받아온 데이터를 후처리하여 다음 데이터를 가져올 때 로딩중... 이 뜨도록 로직을 구상하고 구현하는 일이었다.
다 구현하고 나서 공식 사이트의 별도 예제에 구현 방법에 대한 내용들이 있음을 발견했는데, 배움의 과정 자체에 후회는 없지만, 해당 자료를 참고했다면 더 빠른 시일 내에 기능을 구현할 수 있었을텐데 라는 아쉬움이 드는 것은 어쩔 수 없는 것 같다.
[기능 구현] accessToken 자동 재발급 기능
(기능 목적) 해당 기능은 사용자가 현재 로그인 상태를 지속적으로 유지하기 위해 자동으로 accessToken 을 재발급받을 수 있도록 하는 기능이다.
(적용 이전 기능 및 문제점 인식) 해당 기능 구현 이전에는 북마크 리스트를 GET 으로 5초 마다 불러오도록 할 때 사용자의 accessToken 만료 여부를 GET 요청 시 마다 매번 확인하는 형식을 취했으므로 매우 비효율적이었고, 네트워크 요청에 대한 리소스 낭비가 심했다. 또한 서버에서 데이터베이스에 접근하는 것 또한 결코 적은 비용이 드는 처리가 아니였기 때문에 북마크 리스트의 기능을 개선하면서 이에 대한 로직도 제거하였다.
(결론) 그 이후 accessToken 을 재발급 받을 수 있는 로직에 대해 고민하고, 구상해본 결과 setInterval 과 토큰의 만료기간, 현재시간을 활용해서 토큰의 만료 시간을 추적하는 기능을 구현하는 방식 현 프로젝트에 적용하였다.
[백엔드] 로직 작성
우선적으로 백엔드에서 어떻게 기능을 구현하였는지 정리해볼 것이다. 그 이유는 백엔드에서 accessToken 의 만료 시간을 json 객체에 담아서 응답하므로 이에 대한 이해가 우선되어야 프론트엔드 에서 왜 그렇게 구현했는지 이해가 되기 쉽다고 보았기 때문이다.
① 구현하기 | 기존 accessToken 발급 로직 수정 및 exp 추출 및 반환 함수 정의
기존 로직에서는 accessToken 의 만료시간을 7분으로 지정하고 사용했었으나, 지금은 기능의 테스트를 위해 1분 마다 토큰이 만료되도록 기존 로직을 수정했다.
[참고] Math.floor 관련 로직에 대한 설명이 궁금하다면?
참고로 Math.floor 는 내림 메서드로 소수점 이하를 모두 버린다. Date.now() 를 UTC 기준으로 1970년 1월 1일 0시 0분 0초부터 현재까지 경과된 밀리초를 반환한다. 여기서, Date.now() / 1000 을 한 이유 시간단위가 너무 밀리초로 세분화되므로 작업을 용이하게 하기 위해 초 단위로 변환한 것이며, 이대로 사용하면 소수점 까지 같이 나오기 때문에 Math.floor() 를 사용하여 소수를 버린다.
그 후 현재 1분을 나타내는 60초 에 1을 곱하여 1분을 계산하고, 그 결과를 현재 초 단위 시간에 더하여 값을 구한다.
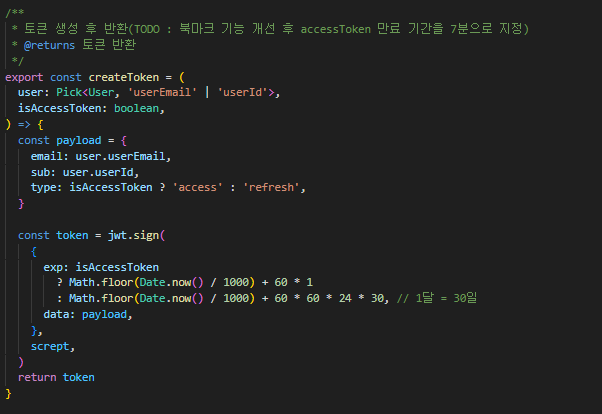
createToken 함수를 통해 accessToken 이 발급된다면, 해당 토큰을 디코드(decode) 처리하여 해당 jwt 페이로드에 저장된 exp 를 추출해야 한다.
따라서 이를 편리하게 활용하기 위해 함수를 작성하였다(해당 함수는 로그인 이외에 accessToken 을 재발급하는 처리에서 재사용된다.)
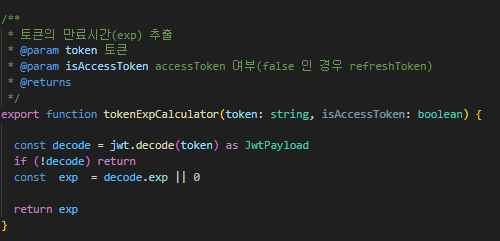
② 구현하기 | exp 을 accessToken 과 함께 클라이언트단으로 응답
앞서 구현된 exp 추출 함수에서 반환된 결과를 Response 객체에 담아서 클라이언트로 응답하기만 하면 된다.


TMI | 참고로 현재 NextResponse 에 사용되는 메시지가 다른 요청에서도 동일하게 사용되는 경우가 많으므로 모듈화하여 재사용성을 높이면 어떨까 고민 중이다.
[프론트엔드] 로직 작성
① Response 객체에서 exp 받은 후 세션 스토로지에 저장( + 관련 헬퍼 함수 정의)
이제 서버에서 받은 데이터를 프론트엔드 단에서 로컬의 sessionStorage 에 저장하여 재활용하는 일만 남았다. 우선적으로 다음 로직 처리와 같이 서버에서 받는 데이터에 exp 를 같이 추가하였고, exp 를 설정하고, 가져오는 함수를 따로 작성하여 재사용성을 높이는 작업을 수행했다.

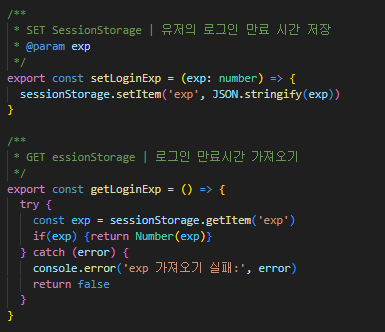
② 구현하기 | Timer.tsx 파일 생성 및 exp 추적 함수 정의
앞서 ① 에서 준비한 데이터와 함수를 활용하여 Timer.tsx 파일에서 해당 로직을 재사용하게 된다. Timer.tsx 파일은 exp 를 관리하고 추적하는 컴포넌트의 역할을 가지고 있으며, 이를 해당 웹 사이트를 사용하고 있는 사용자에게 알려주는 기능울 수행한다.
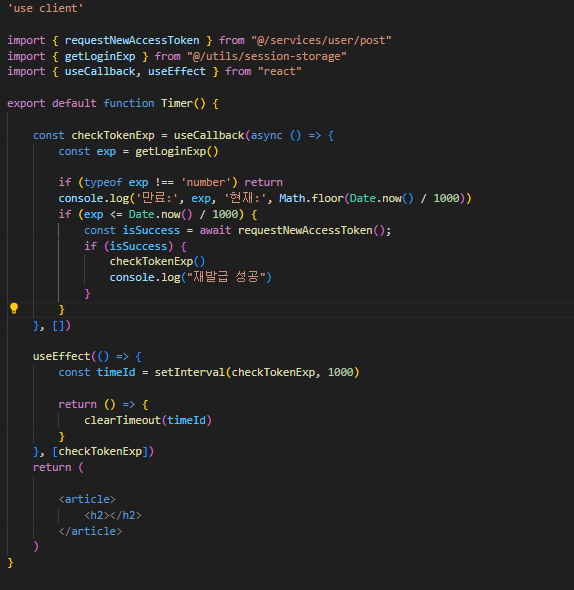
우선 위 컴포넌트는 루트 레이아웃 파일에서 import 되어 사용되므로 서버 컴포넌트로 동작하는 환경에서 재사용하기 위해서는 'use client' 키워드를 상단에 입력하여 해당 컴포넌트가 클라이언트 단에서 동작하는 컴포넌트임을 Next 에게 알려주어야 한다.
그 후 useEffect 를 react 모듈에서 가져와서 관련 로직을 작성하는데, 현재 로직에서는 현재 시간과 토큰의 만료 시간을 비교해서 현재 시간 보다 토큰 만료 시간이 큰 경우 토큰이 만료된 것으로 간주하고, 새로운 accesssToken 을 서버로 부터 발급받아 오도록 로직이 작성되어 있다. 만일 accessToken 발급이 성공했다면 다시 한번 exp 를 체크 하는 함수를 재귀호출하여 세션 스토로지에 저장된 exp 를 다시 받아와서 재사용한다.
[참고 사항 및 최근 개선 사항 개요(2024년 3월 4일 기준 ; 개선은 금일 이전에 이루어짐)]
현재 위에 정리된 코드는 초기 구현에 사용된 코드이므로 몇 가지 문제점 인식 후 개선이 이루어졌다.
앞서 정리한 코드를 보면 checkTokenExp 함수를 setInterval 메서드를 활용하여 1초 마다 실행하도록 하였다. 또한 if 조건에 대한 비교도 토큰이 만료된 이후에 재발급이 이루어지도록 하고 있는데, 이 부분은 필요에 따라서 만료 1분전이나 5분 전 등을 지정하여 응용하면 되는 부분이므로 기존 로직에 60초 전 재발급이 가능하도록 기능을 추가하였다.
[accessToken 만료 60초 전에 재발급이 이루어지며 재발급 간격은 초단위로 400초로 지정]
// 토큰 만료 시간 측정
const checkTokenExp = useCallback(async () => {
const exp = getLoginExp()
if (typeof exp !== 'number') return
const currentTime = Math.floor(Date.now() / 1000)
const expired60SecondsAgo = exp - (currentTime - MINUTE_TO_SEC) // 현재(sec) - 60(sec) = 1분 전 토큰 만료
setTimeScale(Number(expired60SecondsAgo))
if (exp <= currentTime - MINUTE_TO_SEC) {
const isSuccess = await requestNewAccessToken();
if (isSuccess) checkTokenExp()
}
}, [])
useEffect(() => {
const timeId = setInterval(checkTokenExp, 1000)
return () => { clearTimeout(timeId) }
}, [checkTokenExp])구현결과
다행히 정상적으로 60초 간격으로 accessToken 을 재발급 받고 있음을 확인할 수 있다.
추가로 1분 마다 네트워크 요청이 이루어지고 있는 것도 확인할 수 있다.

[마무리] 기능 구현시 어려웠던 점과 추가로 개선된 점
미묘한 시간 간격이 만들어낸 기능 고장
해당 기능의 요지는 사용자가 매번 일정 시간이 지나면 로그아웃이 되는 문제가 사용자 경험에 악영향을 줄 수 있을 것이라 생각하여 추가한 편의성 기능이었다. 다만 해당 기능을 구현할 때 만료시간과 현재 시간의 간격을 지정하고 이를 정확한 타이밍에 발급이 되도록 하는 것이 생각 보다 까다로웠다.
이 부분은 글로 표현하기가 어려운 미묘한 차이로 인해 발생하였는데,
사용자가 현재 브라우저에 포커스를 잃고 다른 화면에 포커스를 맞춘 상태에서는 토큰 재발급을 위한 로직이 실행되지 않고 있다가, 다시 포커스를 브라우저에 맞추면 그 전 까지 멈춰있던 시간 만큼 계산이 되어 렌더링이 되기 때문에, 그 약간의 지연 시간이 토큰을 재발급하는 것에 문제를 일으켰다.
위 문제를 해결하기 위한 고뇌와 해결책
따라서 해당 문제를 개선하기 위한 방법으로 사용한 것이 사용자가 해당 브라우저에 포커스를 맞출 때 accessToken 을 재발급하도록 추가적인 로직을 구성하는 것이었고, 해당 문제를 해결할 수 있었다.
다만, 사용자가 해당 브라우저에 일부러 포커스를 잃고 맞추고 하는 장난을 할 수도 있기에 그 간격에 디바운싱을 걸어서 해결하도록 했었다. 이 부분은 현재 트러블 슈팅 부분에 정리해 두지 않아서 향후 정리해둘 생각이다.
[다음 연관 포스트 ] 기능 구현 모음집 ②
[나만의 명언집 프로젝트] 기능 구현 정리본②
[이전글] 기능구현 정리본 ① [나만의 명언집 만들기 프로젝트] 기능 구현 정리본 ① 오늘의 명언 [기능구현] 좋아요 기능 좋아요 로직 - 사용자가 [좋아요] 아이콘 혹은 버튼을 클릭하면 사용자
duklook.tistory.com
[참고용] 쿼리 정리
기존 테이블에서 복합키를 추가하는 쿼리
ADD_CONSTRAINT 제약조건명 PRIMARY KEY (컬럼1, 컬럼2)
지정한 컬럼의 수 만큼 해당 키를 복합키로 지정한다. 복합키는 두 컬럼이 모였을 때 각 로우를 구분하는 식별자가 되는 키를 의미한다.
ALTER TABLE quote_likes
ADD CONSTRAINT pk_quote_likes_user_id_quote_id PRIMARY KEY(user_id, quote_id)
기존 테이블에서 외래키 제약조건을 추가하는 쿼리
아래 쿼리는 quote_likes 테이블의 참조 외래키로서 user_id 컬럼의 참조 대상을 users 테이블의 user_id 컬럼으로 지정한다. 이 때 users 테이블에서 유저 정보가 사라진다면 , 해당 user_id 를 참조하고 있는 quote_likes 의 데이터(행)도 연쇄적으로 삭제된다.
ALTER TABLE quote_likes
ADD CONSTRAINT quote_likes_user_id_fkey FOREIGN KEY (user_id)
REFERENCES users(user_id)
ON DELETE CASCADE
기존 컬럼의 이름을 수정하는 쿼리
ALTER TABLE table_name
RENAME COLUMN column_name TO new_column_name;
기존 제약 조건을 삭제하는 쿼리
quote_likes 테이블에 걸려있는 외래키 제약조건을 제거한다. 만일, 기존 외래키 제약조건에 추가적인 옵션을 지정하려면 기존 외래키 제약조건을 제거하고나서 ADD CONSTRAINT 를 사용하여 새로 제약조건을 추가해야 한다.
ALTER TABLE quote_likes DROP CONSTRAINT quote_likes_user_id_fkey'프로젝트 > 나만의명언집' 카테고리의 다른 글
| [나만의 명언집 프로젝트] 테스트 코드 적용 정리본(일부) (0) | 2024.03.05 |
|---|---|
| [나만의 명언집 프로젝트] 기능 구현 정리본② (0) | 2024.03.04 |
| [나만의 명언집 프로젝트] 트러블 슈팅 모음집 ② | 7 ~ 13 (0) | 2024.03.02 |
| [나만의명언집 프로젝트] 트리블 슈팅 모음집 ① | 1 ~ 6 (0) | 2024.02.24 |
| [나만의 명언집 프로젝트] NextJS(^14.1) 에서 적용한 accessToken 을 이용한 토큰 인증에서 refresh + access 방식으로 수정 (0) | 2024.02.08 |