들어가기 전
해당 포스트는 프로젝트를 진행하는 중 경험한 문제를 최대한 정리해두는 포스트 입니다. 이 글이 우연히라도 누군가의 도움이 되는 개선책이 담겨 있다면 좋겠습니다.
참고로, 해당 포스트는 트러블 슈팅①(https://duklook.tistory.com/417) 에 이어서 작성됩니다. 전반적으로 빌드나 서버 측 환경에서 경험한 문제들이 모여진 것 같습니다.
[빌드 에러] 실시간 명언 및 오늘의 명언의 정적 빌드 문제
※ 이 부분은 트러블 슈팅 1 에서 다룬 정적 페이지와 동적 페이지 빌드에 대한 부분에 관한 처리를 다루는 이슈 입니다. NextJS 는 개발 환경에서는 정적 페이지를 생성하지 않지만, 배포를 위해 빌드하게 되면, 정적/동적 페이지가 별도로 구분되어 빌드가 되는데, 동적으로 자동 빌드가 되어야 하는 페이지가 일부 옵션으로 인해 정적 페이지로 로드가 되어 발생한 문제였습니다.
문제상황
(개요) 로컬의 개발 환경에서는 정상적으로 실시간 명언 및 오늘의 명언이 새로운 데이터를 받아와서 업데이트 되었으나, 배포 환경에서는 어떠한 조작을 취하더라도 갱신이 이루어지지 않는 문제가 발생 하였습니다.
해결과정
원인분석
NextJS 의 경우 개발 환경에서는 모든 페이지가 정적인 상태가 아니므로 문제가 없었지만, 배포 환경에서는 빌드 이후 정적페이지와 동적페이지로 나뉘어 파일이 빌드 되므로, 실시간 업데이트가 되지 않는 것임을 인지하였습니다.
아래와 같이 빌드 이후에는 λ(람다; 동적) 와 o(정적) 으로 구분되는 것을 볼 수 있는데, 여기서 실시간으로 업데이트가 되어야 하는 popluars 와 today 라는 api 경로는 정적으로 빌드된 것을 확인하였습니다.

따라서 해당 route.ts 파일을 정적이 아닌 동적으로 빌드되도록 하여 클라이언트로 부터 오는 요청에 실시간으로 새데이터를 보내줄 수 있도록 수정해야 합니다.
코드 수정
정적 빌드를 동적 빌드로 바꾸는 방법은 여러 가지가 있습니다. header() 메소드나 cookies() 메소드를 호출하거나, 아니면 직접 Request 객체로 부터 header 프로퍼티를 명시하거나, 아니면 동적 라우팅 경로를 사용하거나 등등 말이죠.
사실 위 방식을 사용하는 경우에는 별도로 조치할 문제는 별로 없습니다. 이들은 모두 NextJS 에서 알아서 동적/정적을 구분하여 빌드해주기 때문이죠. 다만, 제가 언급한 route.ts 파일의 경우에는 header(), cookies(), req, 동적 라우팅 등을 처리하지 않은 파일이지만, 실시간으로 업데이트가 이루어져야 하는 애매한 조건이 붙습니다.
따라서 위 방식을 사용하지 않고, 해당 파일의 빌드 방식을 강제적으로 바꿀 수 있는 옵션이 있는데, 여기서는 그 옵션을 적용하여 정적 빌드를 동적 빌드로 변경 시키도록 할 생각입니다.
즉, 각 정적 빌드가 되는 route.ts 파일의 상단에 const dynamic = 'force-dynamic' 을 명시해주면 됩니다. 저는 아래와 같이 동적 라우팅 경로임을 명시하였습니다.
// route.ts
export const dynamic = 'force-dynamic'
export async function GET() { ... }
그 후 npm run build 를 실행한 결과 정적으로 빌드된 route.ts 파일이 모두 동적으로 빌드된 것을 확인할 수 있습니다.
성과
다행히 정상적으로 변경사항이 반영되는 것을 볼 수 있었습니다.
[빌드 에러] /api/users/route.ts ex [Error]: Dynamic server usage: Page couldn't be rendered statically because it used `headers`
※ 이 부분도 앞서 빌드 에러의 연장선입니다. 서버 구성 요소에서 headers() 나 cookies() 등의 메소드를 사용하면 해당 페이지는 더 이상 정적 페이지로 빌드할 수 없으므로 빌드 시 해당 페이지가 동적인 페이지임을 명시해야 함을 나타냇던 이슈였습니다.
문제상황.
(개요) 프로젝트 배포를 위해 npm run build 를 수행하는 도중 특정 페이지에서 정적 페이지 생성에 실패하였다는 에러가 발생하였습니다.
(선례) 이 문제와 유사한 사례를 트러블 슈팅 1 에서 경험하였으나, 당시 해결 책은 빌드 에러가 발생하는 지점의 api 경로를 중복된 역할을 하는 다른 api 경로와 병합하여 아에 원인이 발생하는 지점 자체를 제거하는 형식으로 해결하였지만, 근본적인 원인을 해결했다고 보기에는 한계가 있었습니다.
(사전 개선 시도 및 실패) 앞서 선례와 스택오버 플로우 등에서 사용된 방법으로 page.tsx 파일 내부에서 const dynamic 변수를 추가하거나, fetch 호출 시 캐싱이 되지 않도록 하는 등의 방법을 활용해 보았지만 이 문제를 개선할 수 없었습니다.
(서두 결론) 따라서, 해당 트러블슈팅은 앞서 도전 이후, 재차 다른 방식을 고안하고, 분석하고, 시도하여 성공한 방법을 정리 하였습니다.
해결과정.
이번에는 공식 문서를 적극 활용하여 해당 문제를 적극 해결하고자 하였습니다. 해당 에러 로그를 보면 해당 문제를 경험하는 경우 참조하라는 링크가 존재하였으므로 이를 참고하여 문제를 개선해 나가기로 하였습니다.

원인분석
에러가 발생한 route.ts 파일의 공통점은 모두 headers 를 next/headers 에서 import 하여 사용하고 있다는 점, 그리고 해당 headers 객체는 route.ts 파일 자체에서가 아닌 모듈화된 함수 내부에서 req.headers 로 접근하고 있다는 점 입니다.
즉, NextJS 에서는 headers 나 cookies 와 같은 메소드를 route.ts 파일을 분석할 때 발견하면, 해당 파일을 동적 라우팅 대상으로 인식 합니다.
그러나, 해당 메소드들이 route.ts 파일의 최상단이 아니라 비동기적 처리를 하는 별도의 모듈화된 함수 내부에서 호출되면서, NextJS 입장에서는 해당 파일에 대한 정적/동적 페이지 생성에 대한 처리가 지연될 수 밖에 없습니다.
즉, 해당 페이지의 역할을 명확하게 인식하지 못해서 발생하는 문제라고 볼 수 있습니다.
route.ts 파일의 상단에 NextJS 에게 해당 파일이 동적 라우팅 파일임을 알리기 위한 더미 headers 메소드 호출
서론은 길었지만 해결 방법은 매우 단순 합니다.
앞서 문제를 분석해보면서, 결국 NextJS 에서 headers 를 우선적으로 발견하여 해당 파일이 동적 라우팅이 이루어지는 파일임을 인지하기 쉽도록 설정하면 된다고 판단하였고,
다시 말해 실제 사용하지는 않는더미 headers 를 추가 하여 해당문제를 해결할 수 있었습니다.
export async function GET(req: NextRequest) {
req.headers
사실 위와 같은 방식 말고 아래 방식이 권장되는 방식입니다(2024년 3월 26일 자 추가).
사실 위와 같이 req.header 나 header(), cookies 등등의 동적 빌드를 유발하는 메서드나 프로퍼티 말고 제일 단순하면서도 권장되는 방식이 존재합니다.
바로 export const dynamic = 'force-dynamic' 를 route.ts 파일 상단에 export 해두는 것입니다.
해당 옵션을 page.tsx 와 같은 페이지 파일에서만 사용할 수 있는 줄 알았는데, 공식 문서(https://nextjs.org/docs/app/building-your-application/routing/route-handlers#convention)를 살펴보니 route.ts 파일 최상단에서도 사용할 수 있다는 사실을 알게 되었습니다.
따라서 아래와 같이 해당 routet.ts 가 동적인 route 임을 명시해두기만 하면 이 문제를 해결할 수 있습니다.
export const dynamic = 'force-dynamic' //⭕
export async function GET(req: NextRequest) {
//req.headers ❌
성과.
결과적으로 빌드 중 에러가 발생하는 현상이 제거되었습니다. 이를 비교하기 위해서 추가 전과 추가 후에 빌드 결과가 어떻게 달라지는지 시연 이미지를 남깁니다(2024년 3월 26일 이전 내용).
[스크린 리더 오작동] 잘못된 태그의 중첩으로 인한 스크린 리더기 오작동 문제
※ NextJS 에서는 layout.tsx 파일과 error 바운더리는 모두 중첩된 형태로 자식 레이아웃과 에러 바운더리를 감싸는 형태로 구성됩니다. 이 때 상위 레이아웃에서 section 태그로 자식을 감싸게 되면, section 태그가 자식 컴포넌트의 렌더링 시 감싸게 되는데, 이 논리적 흐름을 이해하지 못했던 저의 실수로 section 태그가 상위에서 하위 컴포넌트로 중첩되도록 레이아웃을 설계했던 것이 문제였습니다.
문제상황..
(개요) 스크린 리더기를 사용하여 시각 장애인의 접근성을 높일 수 있도록 코드를 개선하던 중 스크린리더기가 특정 페이지에서 섹션,, 섹션,, 섹션과 같이 동일한 텍스트를 여러 번 읽는 문제가 발생하였습니다.
이 문제는 스크린리더기를 사용하는 시각 장애인에게 혼란을 줄 수 있는 시급한 문제라 판단하였고, 이 문제를 해결하기로 하였습니다.
문제가 되고 있는 페이지(/user-quotes/[category])
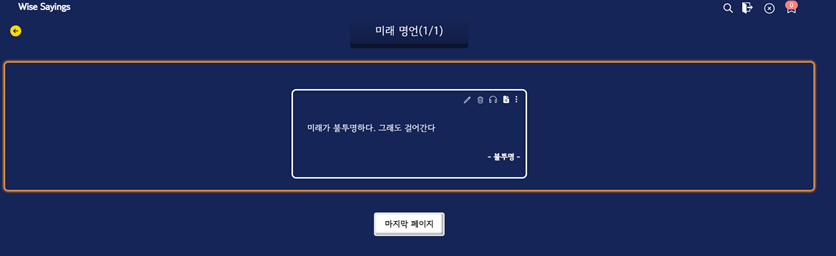
해결과정..
원인분석
(분석) 우선적으로 스크린 리더기가 왜 동일한 텍스트를 여러 번 읽는 것인지 확인하기 위해 우선적으로 [개발자 도구]의 Element 탭을 살펴보기로 하였습니다.
분명 해당 페이지의 section 태그는 하나만 사용했었는데, 여러 개의 section 태그가 중첩되어 사용되고 있는 것을 발견하였습니다.

이 구조를 보고 나서, 현재 페이지가 렌더링되고 있는 경로 내에서 section 태그를 사용하고 있는 페이지를 살펴보았고, 동일한 section 태그를 layout.tsx 파일 내에서 <section>{children} </section> 형태로 코드가 작성된 것을 확인 하였습니다.
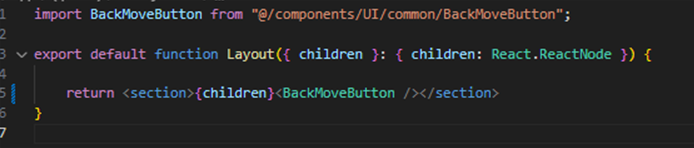
발생원인 및 해결
불필요한 section 태그를 사용함에 따라 layout 의 구조가 자식 세그먼트로 상속되고, 그 내부에도 동일한 구조로 layout.tsx 가 설정되어 있음에 따라 중첩된 section 이 형성된 것 이었습니다.
결국 이 문제는 NextJS의 레이아웃의 상속 구조를 이해하지 못한 저의 실수였기에 이후 section 의 중복 구조를 제거하는 작업을 수행하였습니다.
성과..
- 개발자 실수로 발생한 문제였으나, 결과적으로 스크린리더기 사용자의 접근성을 향상 시킬 수 있었습니다.
- 불필요한 태그의 중첩사용은 브라우저가 렌더링되는데 불필요한 리소스를 낭비하게 되므로 이 문제를 개선할 수 있었습니다.
- (배운점) 잘못 사용된 태그가 사용자의 접근성에 얼마나 악영향을 미치는지 알 수 있는 대목이었고, 보다 개발 시 신중한 태그 사용을 고민하게 되었습니다.
[배포 에러] AWS EC2 npm install 멈춤 문제와 swap 적용
※ 이는 배포 시에 ec2 를 구동하는 CPU 와 메모리의 크기가 작아서 npm install 시 사용되는 CPU 와 메모리 공간 부족으로 작업이 멈추는 문제가 발생했던 겁니다. 이 때 swap이라는 기법을 적용하면 부족한 메모리 공간을 하드디스크의 일부 공간으로 대체할 수 있는데, 그 공간을 만들고 활성화하는 과정을 담은 이슈입니다.
문제상황...
AWS EC2 의 프리티어 버전으로 사용가능한, t2.mirco 를 사용하여 사이트를 배포하던 중 npm install 명령어를 실행 시 다운로드가 무한 지연되는 문제가 발생하였습니다.

해당 문제의 경우. 2024년 3월 15일 자로 경험하였으나, 네트워크 문제로만 판단하여 2024년 3월 16일 경에 다시 시도하였지만, 똑같은 문제를 경험하였습니다. 하드웨어적 용량 제한이 높지 않은 가상 컴퓨터라서 많은 메모리와 CPU 사용률을 보였는데, 가용 가능한 공간이 부족하여 이러한 문제가 발생한 것으로 판단됩니다.
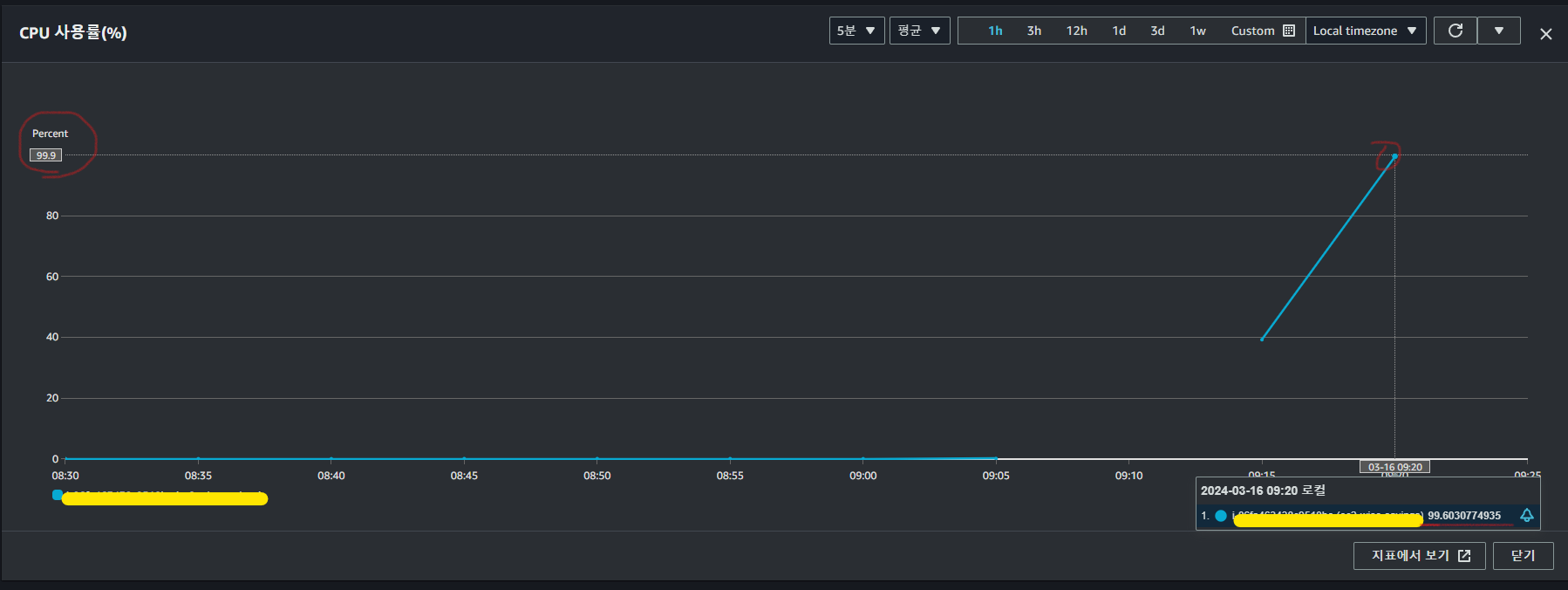
해결과정...
사실 아주 간단한 해결방법이면서, 옳은 방향은 t2.mirco 보다 더 높은 용량을 가진 인스턴스를 선택하는 것이겠지만, 프리티어를 벗어나 24시간동안 비용을 감당할 여력이 없었기에 보류 하였습니다
[중요❗] 방법 적용에 앞서 당부할 점
| (방법 적용에 앞서) 만일 본인이 올리고자 하는 프로젝트 파일의 크기가 엄청 크다면, 장기적으로도 안정적으로 운영하고자 계획하고 있는 프로젝트라면 제가 설명하는 방법은 테스트용도를 위한 임시적이어야 하며, 인스턴스의 사양을 확장하는 것(이를 수직 스케일링 이라 하네요) 이 매우매우 옳은 방식입니다. 이 방식은 디스크를 RAM 대신 사용하여 시스템의 자원을 효율적으로 사용한다는 장점이 있지만, 그 만큼 크기가 클수록 디스크에 대한 입출력 빈도에 대한 부하를 높이기 때문에, 부하가 큰 작업의 경우 반대로 시스템 성능을 저하시킬 수 있습니다. 즉, RAM 보다 느리므로 예상치 못한 단계에서 많은 부하를 발생시킬 수 있습니다. 임시방편으로 단기간 운영하거나 테스트 배포를 위해 활용 시에는 매우 좋으나, 그 이상의 규모나 목적, 확장성 등을 염두에 둔다면 조심스럽게 접근하여야 합니다. npm install 과 같은 의존성 모듈을 설치하는 명령어의 경우에도 단시간에 매우 많은 CPU 부하와 메모리 사용을 높이기 때문에, 사실상 t2.mirco 같은 저사양 컴퓨터가 감당하기에는 매우 벅찬 작업이기도 합니다. 그런데 의존성 모듈이 정말 정말 많은 프로젝트라면 그 부담은 상상을 초월 하겠죠. |
이 때, 저와 같은 문제를 경험한 사례를 스택오버플로우에서 발견 하게 되었고, 해당 방법을 적용하여 문제를 해결하기로 결정하였습니다(해결한 지금 다시 보면 스택오버플로우뿐만 아니라 많은 분들이 블로그에 해결방안을 올려주셨네요).
fallocate -l 4G /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
swapon --show
free -h
스왑 파일을 생성하여 가용 가능한 메모리 공간을 확보하는 기법
해당 방법이 어떤 방법인지 자세히는 몰랐기에 각 명령어가 어떤 동작을 하는지 검색해보았습니다. 알지 못하고 그냥 적용하는 것은 향후 어떠한 부수효과를 발생시킬지 모르기 때문 입니다.
fallocate -l 4G /swapfile
# fallocate : 리눅스에서 파일을 생성하거나 파일 크기를 변경하는 명령어
# -l : 파일 크기를 결정하는 옵션으로 -l 4G 는 4기가 짜리의 파일을 뜻합니다.
# 즉, 위 명령어는 4G 짜리의 빈 파일을 /swapfile 경로에 생성한다는 의미입니다.chmod 600 /swapfile
# chmod : 지정한 파일에 대한 권한을 부여할 때 사용하는 명령어
# 600 : 순차적으로 소유자(Owner), 사용자(User), 기타 사용자(Other)로 권한 부여 범위를 지정합니다.
# → 6은 : 4(읽기), 2(쓰기) 를 의미하는 것으로 소유자가 읽고 쓰기가 가능하다는 의미입니다.
# → 0은 : 아무런 권한이 없다는 의미로 사용자와 기타 사용자는 아무런 권한이 없다는 의미입니다.
# 즉, 위 명령어는 /swapfile 에 대해서 소유자만 읽고 쓰기가 가능하다는 의미이죠.mkswap /swapfile
# mkswap : 스왑 파일을 스왑이 가능한 영역으로 지정하는 명령어 입니다.
# 여기서는 /swapfile 을 스왑이 이루어지는 영역으로 지정하고 있습니다.swapon /swapfile
# 생성했던 /swapfile 을 활성화 합니다. 이제 부터 메모리 부족 문제가 발생하면
# 해당 경로의 스왑 파일을 임시 메모리 공간 처럼 활용합니다.swapon --show
# swapon: 현재 활성화된 스왑 영역을 보여주는(--show) 명령어 입니다.free -h
# 시스템의 스왑 상황 및 메모리 정보를 요약해서 보여줍니다.
| 즉, 여기 까지 정리해봤을 때, 스왑이라는 것은 시스템이 메모리를 사용하여 특정 명령을 수행할 때, 메모리 공간(흔히, RAM)이 부족한 문제로 성능이 저하되거나, 시스템이 종료되는 등의 문제를 해결하기 위한 방법 이었습니다. 쉽게 말해, 부족한 메모리 공간을 임의로 시스템의 디스크를 활용하여 마치 임시 메모리 공간인 것과 같이 활용하는 것입니다. AWS EC2로 따지면 GP2나 GP3 와 같은 스토로지(EBS)에 임시적으로 메모리에 올려지는 데이터를 보관하여 메모리 부족 문제를 개선하는 것입니다. |
단, 앞서 언급했듯이 디스크 입출력에 대한 부하도 문제이지만, RAM에 비해 속도가 느리기 때문에, 이 방식은 장기적으로 확장 가능성 있는 프로젝트의 경우에는 임시적으로 활용되어야 하며, 규모가 있는 경우에는 더더욱 제한적으로 사용되어야 합니다.
저는 이를 염두에 두고, 적용하기로 하였습니다.
EC2 인스턴스에 적용하기
해당 명령어는 리눅스 커맨드로 적용되므로 SSH 클라이언트(저의 경우, Putty)를 통해 접속한 아마존 리눅스 환경에서 해당 명령어를 적용하였습니다.
관리자 권한으로 swapfile 생성
우선 해당 명령어는 관리자의 권한으로 사용 가능하기 때문에 sudo 를 꼭 붙여 주어야 합니다. 따라서 이를 염두에 두고 하나씩 명령어를 실행해 나가겠습니다.
우선 swapfile 을 생성합니다.
sudo fallocate -l 4G /swapfile
생성하더라도 아무런 변화가 보이지 않습니다. 이는 정상이니 넘어가시면 됩니다.
swapfile 에 대한 권한을 소유자로 제한
그 다음 swapfile 을 읽고 쓸 수 있는 권한을 소유자(Owner) 로 제한하는 명령어를 입력합니다.
sudo chmod 600 /swapfile

이 또한 마찬가지로 시각적인 변화가 없으므로 넘어 갑니다.
생성한 swapfile 을 스왑 영역으로 지정
이번 명령어를 통해 앞서 생성한 빈 파일에 불과했던 swapfile 을 실제 swap 영역으로 지정하게 됩니다. 즉, 메모리 부족 문제가 발생하면 해당 공간을 알아서 가용 공간으로 활용하게 됩니다(물론 영역 지정만 한 것일 뿐 이를 사용하려면 추가 명령어가 필요합니다).
mkswap /swapfile

해당 명령어를 실행하면 4GiB 크기의 스왑 공간을 설정했다고 나오며 이를 식별하는 UUID 가 표시되는 것을 볼 수 있습니다.
swap 공간을 활성화
앞서 지정한 공간을 활성화시키려면 다음 명령어를 입력해야 합니다.

여기서도 별도의 언급은 없네요. 다음으로 넘어 갑시다.
나머지는 로깅을 위한 명령어
앞서 명령어 까지만 실행하면, swap 은 정상적으로 동작합니다. 이후에 적용하는 두 가지 명령어는 해당 swap 이 정상적으로 동작하는지, 어느 정도 크기를 사용하고 있는지를 로깅하는 명령어 입니다.
swapon --show
free -h
swapon --show 를 입력하면, 현재 스왑파일의 크기와 사용되고 있는 크기를 확인할 수 있습니다.

그리고 free -h 를 사용하면 전체 시스템에서 사용되고 있는 메모리, 사용 가능한 메모리, 총 메모리, 임시 버퍼(임시 메모리) 등의 정보를 개괄적으로 확인할 수 있습니다.

참고로 -h 옵션은 사람이 읽기 쉬운 형태로 시각화 해서 보여달라는 의미입니다.
성과...
도중에 멈추지 않고, 정상적으로 설치가 되었습니다.

여기서 끝나면 좀 아쉬우니까 앞서 로깅 명령어를 입력해서 어떤 변화가 생겨났는지 살펴보고 마무리 하겠습니다.
보이시나요? 사용된 메모리에서 추가되는 부분인 49MiB 가 swap 파일에서 저장되어 사용된 것을 볼 수 있습니다.

마무리하면서
ec2 환경에서의 빌드에러는 해결하였지만, 다음에 이어지는 배포 후 502 나쁜 게이트웨이 문제가 발목을 잡았습니다.
[데이터베이스 인증] 데이터베이스 접속 불가 문제
※ 해당 문제는 데이터베이스에 대한 접근 권한 문제로 EC2 내에서 접근이 불가능하여 발생한 문제였습니다. 당연히 해결책도 권한부여를 통해서 해결됩니다.
문제상황....
AWS EC2 에 프로젝트를 배포한 이후, 데이터베이스의 복원 작업 까지 마무리 하였습니다. 그러나 해당 데이터베이스에 대한 접근이 실패하였는다는 에러가 뜨고 있던 상황입니다.

개선과정(및 결과)
해당 문제는 크게 작성할 내용이 없어서 짧게 정리 해봅니다.
해당 문제의 원인은 postgresql 의 암호화 관련 구성 파일인 pg_hba.conf 에서 사용자 계정 접근 시 인증 방법을 ident 로 설정하였기 때문입니다.
ident는 ec2 인스턴스 내의 운영체제인 아마존 리눅스의 관리자 계정을 인증하는 방식이므로 보안 문제로 승인 거부가 발생한 것이었습니다.
따라서 인증 방법을 데이터베이스 접속 시 사용한 계정의 비밀번호로 인증하는 해시암호화 방식인 md5 로 지정하여, 비밀번호 인증을 통해 데이터베이스 접근이 가능하도록 설정을 변경하였습니다.
이를 통해 결과적으로 해당 문제를 해결할 수 있었습니다.
[렌더링 이슈] 명언 목록 재조회 실패 문제
※ 이 문제는 결론적으로 PostgreSQL 의 인스턴스를 중첩해서 호출하여 허용 가능한 범위를 초과하여 데이터베이스 접근이 불가능함으로써 발생한 문제였습니다. 사소한 문제였지만, 잘 되던 서버가 갑자기 오작동하여 당혹스러웠던 기억이 납니다.
문제상황.....
topic 별로 명언을 조회하는 페이지가 있습니다. 해당 페이지에 접속하고, 명언 목록을 무한 스크롤 형태로 조회 시 500번대 에러가 클라이언트에서 발생하는 문제가 발생하였습니다. 또한, 조회시 문제가 없더라도 이전 페이지로 이동 후 다시 현재 페이지로 이동하는 경우에도 동일한 문제가 발생하는 것을 확인하였습니다.
해결과정.....
원인분석 | 들어오는 사람은 많은데, 나가는 사람이 없으면 생기는 문제
사실 클라이언트에서는 서버에서 데이터를 받아와서 렌더링하는 것이 전부 이기 때문에, 해당 문제의 발생원인은 서버 측에서 찾아야 맞겠죠. 따라서 해당 에러가 서버 측에서 어떤 로그로 표시되는지 확인하였습니다.
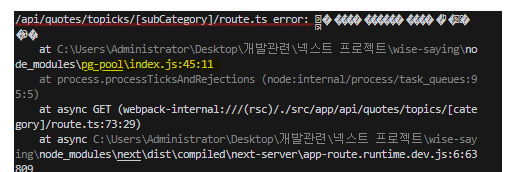
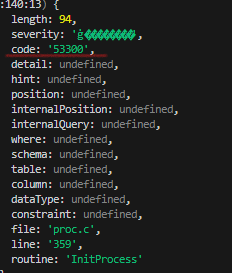
로그를 살펴보니 에러가 발생한 경로가 보이네요. 에러 메시지 부분은 인코딩이 깨져서 보이지는 않지만, 해당 에러가 발생한 지점은 pg-pool/index.js:45.11 이라고 명시되어 있습니다.
사실 pg-pool 만 봐도 아.. 이거는 메모리 누수 문제 였구나 짐작이 되었습니다. 무엇보다 에러 코드가 53300 인데, 이것을 구글링 해보니 과도한 연결 문제로 발생하는 에러라고 했습니다. 이 쯤 되니 한 가지 명확한 원인이 생각 났습니다. 데이터베이스 연결 요청만 보내고, 닫지를 않았구나 라고요.
데이터베이스 연결을 닫는 로직 추가
저는 해당 프로젝트에서 postgres 라는 데이터베이스를 순수하게만 사용하였습니다. 즉, 타입ORM 이라는 도구를 사용하지 않고 직접 쿼리를 작성하는 방식으로 사용했는데요. 이러다 보니 모든 쿼리 마다 마지막에는 직접 db.end() 를 명시해줘야 했습니다. 결국 이 부분은 제가 신경쓰지 못한 문제로 발생했기에 다음과 같이 db.end() 를 쿼리 실행 후 명시하도록 로직을 추가하였습니다.

성과.....
이 문제의 성과라고 언급할 내용은 딱히 없는 것 같습니다. 저의 실수로 시작된 문제였으니, 더 이상 과도한 풀 연결로 인한 메모리 누수가 발생하지 않게 되었고, 해당 에러가 발생하여 사용자 입장에서 500번대 에러를 볼 일이 없어졌다는 점이 전부 인 것 같네요.
[DB 인코딩] postgreSQL DB 백업 후 복원 시 클라이언트와 서버 간의 인코딩 불일치 문제
※ 이는 명령어를 잘못 입력하여 제대로 인코딩 변환이 안 되어서 발생한 문제였습니다.
문제상황......
로컬에 있는 데이터베이스의 정보를 백업하여, AWS EC2 에서 해당 파일을 복원하려고 하니 다음 문제가 발생하였습니다.

해결과정......
원인분석
해당 문제는 에러 메시지에 나와 있듯이 UTF8 인코딩 형식에 대한 유효하지 않은 바이트 시퀸스가 포함되어 있어서 발생한 문제입니다. 쉽게 말해 현재 복원 대상이 되고 있는 데이터베이스 서버의 인코딩 형식과 복원을 시도하는 데이터베이스 파일(클라이언트 환경)의 인코딩 형식이 서로 불일치하여 발생한 문제였습니다.
참고로 클라이언트 인코딩 정보는 평문으로 백업한 데이터베이스 파일인 경우(.sql)에는 해당 파일을 vscode 등의 에디터를 사용해서 열어보면 상단에 set client_encoding 이라는 키-값 형태로 나와 있습니다.
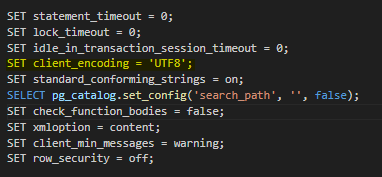
저 같은 경우에는 해당 문제를 경험하기 전에 위와 같이 UTF8 이 명시되어 있음에도 문제가 발생하였었는데요. 왜 그런문제가 발생하였는지 ec2 클라이언트에서 직접 해당 파일이 어떻게 인코딩 되어 전달되었는지 확인 해보았습니다.
file -i 파일명.sql 형태로 명령어를 입력하면 아래와 같이 현재 파일의 요약정보와 함께 인코딩 형식을 확인할 수 있습니다. 그런데 분명 파일 내에서는 UTF8 이 포맷이었는데, 여기서는 다른 인코딩 형식으로 되어 있는 것을 확인하였습니다.

클라이언트 인코딩 변경
앞서 문제를 확인했으니, ec2 로 파일이 넘어갔을 때도 정상적으로 UFT8 로 인코딩될 수 있도록 해줄 필요가 생겼습니다.
여러 방법을 모색해보니 데이터베이스 파일을 백업할 때, -E 이라는 옵션을 사용하면 인코딩 형식을 사용자가 명시적으로 지정할 수 있다고 합니다.
따라서 다음과 같이 백업 시 UTF8 로 인코딩할 것이라는 사실을 명시한 후 백업을 실시하였습니다.
pg_dump -E UTF-8 -U username -d dbname -f backup_file_name.sql
인코딩 변경점 확인
그 후 EC2 클라이언트를 통해 ec2 로 db 파일을 전송 한 후 해당 파일에 지정된 인코딩 형식을 확인하면 정상적으로 UTF8로 지정된 것을 확인할 수 있습니다.

복원 시도하기
이제 실제 데이터베이스에 복원을 시도 해보겠습니다. 저 같은 경우에는 백업 시 평문 sql 파일을 복원하므로 psql 을 사용하여 복원시도 하였습니다.
결과적으로 에러가 뜨지 않고 복원이 진행되는 것을 확인할 수 있었습니다.

.성과(혹은 소감)
이 부분도 크게 성과라고 할 것은 없는 것 같습니다. 다만, 이번 문제를 해결한 소감? 같은 것을 적어보자면, 해당 문제를 경험하기 전에 사용했던 백업과 복원 방식은 변동이 없었음에도 불구하고, 서버 인코딩과 클라이언트 인코딩 간에 불일치하는 문제가 발생하였다는 점이 스스로에게 경각심을 심어주는 계기가 되었던 것 같습니다.
물론 서툰 제가 잘못된 명령어를 입력하여 서로 다른 결과가 나왔던 것일 가능성이 높겠지만요. 그럼에도 어떤 환경에서든 동일한 입력이 동일한 출력을 보일 것이라고 여기는 것은 조심하자는 사실을 각인시키고 가는 시간이었습니다.
[나가는 말] 트러블 슈팅 2 작성 후기
이번 트러블 슈팅2 포스트에서 작성된 문제는 백엔드 환경에서 발생한 문제들을 정리하고 나열해보는 시간이 되었습니다. 뭔가 트러블 슈팅 1 에 비해서 미흡한 정리가 아니었나 싶기도 하고, 문제해결이 검색을 통해서 쉽게 나오는 문제라면 배제하는게 좋지 않았나 등 부수적인 생각과 동일하거나 유사한 실수가 배경이 되는 여러 트러블 슈팅을 살펴보면서, 너무 안일한 태도로 개발을 하고 있는게 아닌가 라는 경각심을 느끼는 시간이 되었습니다.
| 특히, 빌드에서 정적과 동적 페이지 빌드 이슈가 여러 차례 반복적으로 등장하는데, 공식문서를 다시 살펴보면서 사이사이 부족한 지식을 채워나가야 겠습니다. 여러가지로 반성하게 되네요. |
또한, 프로젝트를 하면서 기술적으로 해결하기 힘들었던 문제가 존재합니다. 애초에 트러블 슈팅이 모든 이슈를 정리하라고 있는게 아니긴 하지만, 정작 기록해둘 필요가 있는 문제의 개선 과정을 남기지 못한 것 같아서 아쉽게 다가오기도 했습니다
이번 트러블슈팅 2 포스트도 이렇게 작성하는 시간을 가져보았습니다. 감사합니다.
이전/이후 트러블 슈팅
[나만의명언집 프로젝트] 트리블 슈팅 모음집 ① | 1 ~ 6
들어가기 전아주 사소한 문제일지도 모르나 개인적으로 해결하기에 고민을 많이 했던 이슈들을 하나씩 정리한 포스트 입니다. NextJS 를 사용했기에 프론트엔드와 백엔드 간의 구분이 모호하여
duklook.tistory.com
[나만의 명언집] 트러블 슈팅 모음집 ③ | 14
[링크] 이전 트러블 슈팅 [나만의명언집 프로젝트] 트리블 슈팅 모음집 ① | 1 ~ 6오늘의 명언 참고) 정리 방식은 1) 문제상황 → 2) 해결과정 → 3) 성과/소감/결과시연 흐름으로 정리합니다.
duklook.tistory.com
[나만의 명언집] GithubActions 을 통한 CI 와 AWS CodePipeline (CodeDeploy)을 통한 CD 구축 | NextJS 프로젝트를
들어가기 전아마 두 CI/CD 도구를 혼합해서 사용하는 경우는 많이 없을 것 같긴 합니다(현장마다 어떻게 활용하고 있을지 자세히 모르니, 추측일 뿐입니다). 보통 Github Actions + AWS CodeDeploy 만 같이
duklook.tistory.com
'프로젝트 > 나만의명언집' 카테고리의 다른 글
| [나만의 명언집 프로젝트] 테스트 코드 적용 정리본(일부) (4) | 2024.03.05 |
|---|---|
| [나만의 명언집 프로젝트] 기능 구현 정리본② (0) | 2024.03.04 |
| [나만의 명언집 만들기 프로젝트] 기능 구현 모음집 ① (0) | 2024.03.04 |
| [나만의명언집 프로젝트] 트리블 슈팅 모음집 ① | 1 ~ 6 (1) | 2024.02.24 |
| [나만의 명언집 프로젝트] NextJS(^14.1) 에서 적용한 accessToken 을 이용한 토큰 인증에서 refresh + access 방식으로 수정 (1) | 2024.02.08 |



