| 최근 백엔드 학습에도 도전중입니다. 해당 포스트는 아마 프론트엔드 위주의 지식을 정리할 듯하고, 백엔드 개념 공유소는 별도의 포스트를 추가할 것 같습니다. |
해당 포스트는..
제가 정리해서 한 번에 보고 싶은, 혹은 공유해서 사용해보면 좋을 것 같은 도구들을 모아두는 공간입니다. 매번 갱신될 때 마다 최신 날짜로 올라옵니다. 원래 수정 시 날짜를 표기하지 않았는데, 관리 효율성을 위해 새로 추가된 내용은 옆에 날짜를 표기하기 시작했습니다. 여러모로 도움이 되는 글이 되길 바랍니다.
공유하고 싶은 VSCODE 플로그인
- import cost : 모듈이나 라이브러리 import 시에 추가되는 모듈, 라이브러리의 크기를 실시간으로 알려줍니다. 24.8.5
- code spell checker : 영문에 익숙하지 않은 사용자가 흔히 저지를 수 있 철자 오류 등이 있으면 이를 바로 잡아줍니다.
공유하고 싶은 도구 링크
- 입문 부터 대학까지 모든 수학: https://ko.khanacademy.org/math/algebra-basics/alg-basics-algebraic-expressions/alg-basics-combining-like-terms/e/manipulating-linear-expressions-with-rational-coefficients
- Astro : 자바스크립트의 프레임워크 입니다. 보통 리액트, 뷰와 같이 자주사용되는 프레임워크(라이브러리)는 SPA 기반으로 돌아가지만, 해당 프레임워크는 서버 사이트 렌더링에 중점을 둔 MPA 입니다. 빠른 웹 사이트 구축에 필요한 모든 도구를 지원하고, 입문자도 약간의 HTML, CSS 와 어느 정도의 JS 활용능력만 있으면 누구나 쉽게 빠른 웹 개발을 가능하게 해줍니다. 또한 어떤 환경에서도 빠른 웹 사이트 실행을 주요 과제로 보았기에 타 프레임워크 및 라이브러리 보다 렌더링 성능면에서 뛰어난 모습을 보여주기도 했습니다(https://docs.astro.build/ko/getting-started/).
- ky: fetch, axios 로만 HTTP 요청이 가능한게 아닙니다. ky 처럼 패키지명이 짧은 만큼 더 간결한 방식으로 HTTP 요청을 처리할 수 있게 도와주는 라이브러리 입니다(https://www.npmjs.com/package/ky).24.08.07
// ky 를 사용한다면?
import ky from 'ky';
const json = await ky.post('https://example.com', {json: {foo: true}}).json();
console.log(json);
//=> `{data: '🦄'}`// 일반 fetch 를 사용한다면?
const response = await fetch('https://example.com', {
method: 'POST',
body: JSON.stringify({foo: true}),
headers: {
'content-type': 'application/json'
}
});
if (!response.ok) {
throw new HTTPError(`Fetch error: ${response.statusText}`);
}
const json = await response.json();
console.log(json);
//=> `{data: '🦄'}`
- NextUI : 모던하고 심플합니다. UI 를 누구나 쉽게 사용하기 편하도록 문서화가 잘되어 있고, 무엇보다 많은 기능을 제공하면서도 독립적인 패키지 설치를 통해 필요한 도구만 가져와서 사용하면 되는 부분이 마음에 듭니다. 특히 패키지 크기가 생각보다 가볍다는 장점이 돋보입니다. UI 애니메이션의 경우 프레이머를 사용하고, 디자인은 tailwindcss 를 기반으로 되어 있습니다. (24.08.02). https://nextui.org
| 최근 사용을 해봤는데, 생각보다 가볍지는 않은 것 같긴 합니다. tailwind 와 프레이머에 의존하기 때문에 스타일이나 애니메이션을 적용하려면 추가적인 모듈 설치가 필요합니다. |
공유하고 싶은 개념 링크
- (24/08/23 추가) Mastering Next.js: Best Practices for Clean, Scalable, and Type-Safe Development
- (24/08/21 추가) NextJS App Router 에서 10가지 공통된 실수 : https://www.youtube.com/watch?v=RBM03RihZVs
- (24.08/21 추가) 프론트엔드와 솔리드 원칙(카카오팀 기술 블로그): https://fe-developers.kakaoent.com/2023/230330-frontend-solid/
| 카카오 프론트엔드 기술블로그에서 작성한 솔리드 원칙에 관한 포스트입니다. 기존에 많은 블로그에서 잘못 설파되거나 구체적이지 못한 솔리드 원칙을 보다 명확하고 실제 사용 예시를 기반으로 누가봐도 쉽게 이해할 수 있도록 설명한 포스트 입니다. |
- MDN 이벤트 루프: https://developer.mozilla.org/ko/docs/Web/JavaScript/Event_loop
- Pmndrs.docs : https://docs.pmnd.rs/
- 취소 가능한 가져오기 Abort Controller : https://developer.chrome.com/blog/abortable-fetch?hl=ko#large_spec_change
- 알아두면 유용한 '리액트 개념'과 성능 최적화 팁: https://yozm.wishket.com/magazine/detail/2688/?utm_source=stibee&utm_medium=email&utm_campaign=newsletter_yozm&utm_content=contents
- 우아한 기술 블로그 단위테스트 : https://techblog.woowahan.com/17404/
- 자바스크립트 주요 개념 30 가지 : https://medium.com/@javascriptcentric/top-30-javascript-interview-questions-and-answers-for-2024-7f1e2d1d0638
- NextJS 한글화 문서 : https://nextjs-ko.org/docs/app/building-your-application/routing/layouts-and-templates
- 좋은 커밋 컨벤션 블로그 : https://djkeh.github.io/articles/How-to-write-a-git-commit-message-kor/
- KR 개발자를 위한 북마크 모음집(깃허브): https://github.com/currenjin/site-for-developers?utm_source=oneoneone
- tanstack-query/react: Next 서버 환경에서 쿼리 프로바이더를 지정하는 방법에 대한 공식문서입니다(https://tanstack.com/query/latest/docs/framework/react/guides/advanced-ssr)
- Vitest 공식문서: https://vitest.dev/guide/
- 리액트 공식문서(한국어): https://ko.react.dev/
- 리액트 쿼리 관련 팁 tkdodo 기술블로그: 오래된 자료 부터 비교적 최근 자료 까지 리액트 쿼리 작성과 관련한 다양한 팁을 제공합니다. 리액트 쿼리가 릴리즈 되고 바뀐게 많지만 근본적으로 지향하는 개념과 철학은 동일하므로 언제든 참고하여 활용할 수 있다고 봅니다. https://tkdodo.eu/blog/effective-react-query-keys
- 모두가 알아야 하는 자바스크립트 33가지 개념:
https://medium.com/@codingwinner/33-concepts-every-javascript-developer-should-know-ef225a72ed7f
- 프론트엔드 핸드북: https://www.frontendinterviewhandbook.com/kr/javascript-questions
개인 블로그 문서 링크
처음으로돌아가기 시리즈: https://duklook.tistory.com/577
리액트와 클로저: https://duklook.tistory.com/608
다양한 명령어(도커, nginx, psql 등등) : https://duklook.tistory.com/445
VS Code 사용자 코드 조각: https://duklook.tistory.com/508
연관 포스트
[연관 포스트] IT 용어 모음집
[모음집] IT 용어 모음집
오늘의 명언예제 코드가 있다면 자바스크립트/타입스크립트 기준으로 작성되어 있습니다. libuv 라이브러리libuv는 Node.js에서 주로 사용되는 C 라이브러리로, 주로 비동기 이벤트 기반 프
duklook.tistory.com
[연관 포스트] 자바스크립트 활용 모음집
자바스크립트 활용 모음집
해당 포스트는..자바스크립트 활용을 위한 간단한 예제를 정리해두는 모음집입니다. 필요에 따라 추가될 수 있고, 추가되는 경우 해당 날짜를 기준으로 갱신됩니다. 이미지 미리보기 기능을 구
duklook.tistory.com
[연관 포스트] 리액트 활용 모음집
리액트 활용 모음집
해당 포스트는..해당 포스트는 리액트를 사용하면서 알게된 팁이나 주요하다고 판단되는 활용 예제를 정리하여 모아두는 공간입니다. 직접 활용하다가 알게된 것은 출처가 없고, 참고한 자료가
duklook.tistory.com
이 포스트는..
자바스크립트와 연관된 모든 기술 스텍에 대한 활용 개념 등을 모아두는 저장소 입니다. 그 때 그 때 공부한 내용이나 알아야 했던 내용들을 간략하게 정리하는 방식으로 처리되며, 자료의 출처는 GPT 등의 도구를 통해서 얻거나, MDN 과 같은 어느 정도 공신력이 있는 사이트 혹은 실제 도구의 공식문서를 참고해서 정리합니다. 자료가 추가되는 경우에는 해당 날짜를 기준으로 갱신될 수 있습니다. 현재 이 글이 최신 날짜로 올라와 있다고 해도, 실제 포스트가 생성된 날짜는 오래되었을 수 있습니다.
보안과 관련한 개념
MIME 스니핑 | 서버에서 지정한 Content-Type 과 브라우저에서 지정한 Content-Type 간에 불일치하여 예기치 못한 방식으로 파일이 처리되거나 실행되는 것
해당 공격기법은 웹 브라우저가 서버에서 제공한 MIME 타입(Content-type) 헤더를 무시하고, 파일의 실제 콘텐츠를 검사하여 파일의 유형을 추측하는 동작을 의미합니다. 이로 인해 브라우저가 예싱치 못한 방식으로 파일을 처리하거나 실행할 수 있습니다.
예를 들어, 서버가 파일을 text/plain 으로 제공하지만, 브라우저가 파일의 내용을 검사하여 이를 text/html 로 처리하면, 악성 HTML 코드가 포함된 파일이 실행될 수 있습니다.
예방방법
당연히 해당 스니핑을 방지하려면 정확한 MIME 타입을 설정하면 됩니다. 즉, 서버가 올바른 MIME 타입을 설정하여 브라우저가 이를 따르도록 강제해야 합니다.
또한, X-Content-Type-Options 헤더를 nosniff 값으로 설정하여 브라우저가 서버가 제공한 MIME 타입을 무시하지 않도록 합니다.
기본적으로는 MIME 타입이 aplication/json 타입으로 디폴트 되어 있기 때문에 문제는 없지만, 다른 미디어 타입이나 텍스트 타입등 다른 타입을 지정하여 사용하는 경우에는 이를 꼭 일치시켜 주는 것이 중요하다는 사실을 기억해야 합니다.
클릭 하이재킹(Clickjacking) | 사용자 몰래 악의적 버튼이나 링크를 클릭하도록 유도하여 공격자의 의도한 행위를 강제하는 공격기법
사용자가 의도하지 않은 버튼이나 링크를 클릭하도록 유도하여 악의적인 행위를 수행하도록 만드는 공격입니다. 공격자는 투명한 레이어를 사용해 웹 페이지의 버튼이나 링크 위에 악성 요소를 배치하여 사용자가 클릭하면 다른 작업이 실행되도록 만듭니다.
예를 들어, 공격자가 웹 사이트의 버튼요소A 위에 투명한 iframe 을 올려 놓고, 해당 iframe에 악의적인 버튼B 를 배치할 수 있습니다. 사용자는 버튼A 만 보이므로, 이를 클릭하였지만, 실제로는 투명한 iframe 에 숨겨진 버튼B를 클릭하게 되고, 공격자가 의도하는 행위를 강제적으로 수행하게 됩니다.
클릭 하이재킹을 예방하려면?
해당 공격을 예방하려면 CSP 와 X-Frame-Options 헤더를 지정할 필요가 있습니다. CSP 에는 frame-ancestors 라는 옵션이 있는데, 해당 지시어를 사용하면 페이지가 iframe 으로 삽입될 수 있는 출처를 제어할 수 있습니다.
X-Frame-Options 헤더는 다른 페이지에서 자신의 페이지를 iframe 으로 삽입할 수 없도록 지정하는 헤더 입니다. 이는 CSP의 frame-ancestors 와 거의 동일한 동작을 수행하므로 frame-ancestors 를 설정하면, X-Frame-Options 을 적용한 것과 동일하게 브라우저에서 인식하게 됩니다.
XSS | 공격자가 웹 페이지에 악의적 스크립트를 삽입하여 사용자의 브라우저에서 실행되게 하는 공격 기법
웹 보안과 관련한 정보들 중에서 XSS 가 제일 많이 보였던 것 같습니다. 해당 공격 기법은 악의적 제 3자가 사용자로 하여금 특정한 행동을 하게 만드는 CSRF 와 달리 공격자가 직접 악의적인 스크립트를 특정 태그나 요청에 심어서 서버로 보내고, 서버에서는 정상적인 요청이라 판단하고 처리하는 아주 무서운 공격 기법입니다.
웹 앱이 충분한 유효성 검사나 인코딩을 사용하지 않으면 이러한 공격은 성공하게 됩니다. 사용자의 브라우저는 신뢰할 수 없는 악성 스크립트를 탐지할 수 없고, 쿠키, 세션 토큰 또는 기타 민감한 사이트별 정보에 대한 접근 권한을 부여해버리거나 악성 스크립트가 HTML 콘텐츠를 다시 작성할 수 있도록 합니다.
XSS 유형
여기서 몇 가지 대표되는 XSS 유형에 대해 정리해봅니다.
- 반사된 XSS 공격
반사 공격은 오류 메시지, 검색 결과 또는 요청의 일부로 서버에 전송된 입력의 일부 또는 전부를 포함하는 기타 응답과 같이 삽입된 스크립트가 웹 서버 외부에 반사되는 공격입니다. 반
영된 공격은 이메일 메시지나 다른 웹사이트 등 다른 경로를 통해 피해자에게 전달됩니다. 사용자가 속아서 악성 링크를 클릭하거나 특별히 제작된 양식을 제출하거나 심지어 악성 사이트를 탐색하게 되면 주입된 코드가 취약한 웹 사이트로 이동하고, 이는 공격을 사용자의 브라우저에 다시 반영합니다. 그러면 브라우저는 해당 코드가 "신뢰할 수 있는" 서버에서 왔기 때문에 실행합니다. 반사 XSS는 비지속성 또는 Type-I XSS라고도 합니다(공격은 단일 요청/응답 주기를 통해 수행됨).
- 저장된 XSS 공격
저장 공격은 주입된 스크립트가 데이터베이스, 메시지 포럼, 방문자 로그, 댓글 필드 등과 같은 대상 서버에 영구적으로 저장되는 공격입니다. 그런 다음 피해자는 저장된 스크립트를 요청할 때 서버에서 악성 스크립트를 검색합니다. 정보. 저장된 XSS는 영구 또는 Type-II XSS라고도 합니다.
- 블라인드 크로스 사이트 스크립팅
블라인드 크로스 사이트 스크립팅은 지속적인 XSS의 한 형태입니다. 이는 일반적으로 공격자의 페이로드가 서버에 저장되고 백엔드 애플리케이션에서 피해자에게 다시 반영될 때 발생합니다. 예를 들어 피드백 양식에서 공격자는 해당 양식을 사용하여 악성 페이로드를 제출할 수 있으며, 애플리케이션의 백엔드 사용자/관리자가 백엔드 애플리케이션을 통해 공격자가 제출한 양식을 열면 공격자의 페이로드가 실행됩니다. 블라인드 크로스 사이트 스크립팅은 실제 시나리오에서 확인하기 어렵지만 이를 위한 가장 좋은 도구 중 하나는 XSS Hunter입니다.
예방방법
해당 공격을 방지하려면, 사용자의 입력값을 검증하여 필터링하도록 해야 하고, HTML, JS 등에서 악성 스크립트가 실행되지 않도록 적절한 인코딩을 통해 방지할 수 있습니다.
또한, CSP 를 적용함으로써 스크립트 출처를 제한하여 악성 스크립트의 실행 자체를 차단할 수 있습니다.
CSRF | 사용자가 자신의 의지와 무관하게 공격자가 의도한 행동을 하게 만드는 공격 기법
| 2024.06.23 추가 |
CSRF(Cross-Site Request Forgery)는 웹 보안 공격 중 하나로, 사용자가 자신의 의지와는 무관하게 공격자가 의도한 행동을 하게 만드는 공격 기법입니다. 이는 주로 사용자가 신뢰하는 웹 사이트에 대한 권한을 가진 상태에서 발생합니다. 즉, 백엔드 서버 환경에서는 사용자의 자격증명이 된 상태에서 클라이언트로 부터 전달되는 요청을 신뢰하게 되고, 그 요청을 처리하게 되는 것이죠. 즉, 사용자는 자신도 모르게 요청을 보냈지만, 그 요청이 알고보니 제 3 자에 의해서 보내진 것이니 등꼴이 오싹한 순간이 아닐까 싶습니다.
CSRF의 동작 원리
그럼 CSRF 는 어떤 과정을 거쳐서 발생할까요? 간단한 예시를 통해서 살펴보겠습니다.
- 사용자 인증: 사용자가 웹 애플리케이션에 로그인하여 인증된 세션을 얻습니다.
- 악의적인 요청 생성: 공격자는 사용자를 속여 특정 웹 사이트에 접속토록 유도하고, 인증된 세션이 유지된 상태에서 악의적인 요청을 보냅니다. 이 요청은 사용자가 로그인한 웹 애플리케이션 서버를 대상으로 합니다.
여기서 핵심을 정리하면 자동 전송과 서버 처리 부분입니다.
- 자동 전송: 사용자는 악의적인 링크를 클릭하거나 악성 웹 사이트를 방문하여, 자신도 모르게 요청을 전송합니다.
- 서버 처리: 서버는 요청을 신뢰할 수 있는 사용자로부터 온 것으로 간주하고 정상적으로 처리합니다.
이렇듯, CSRF 는 사용자가 자격증명을 획득한 상태에서 유지되는 세션이 살아 있는 상태로 특정 사이트 접속을 유도하고, 해당 사이트에서 사용자는 자신도 모르게 악의적인 요청을 서버로 전송합니다. 서버는 당연히 증명된 자격을 토대로 보내온 요청으로 판단하고, 그 요청을 처리해서 응답하게 되죠.
동작원리만 보면 이해가 안 될 수 있으니, 조금 더 이해하기 쉬운 예시를 가져와서 살펴봅시다. 우선, 사용자가 로그인된 상태에서 공격자가 조작한 페이지에 접속했을 때, 해당 페이지가 자동으로 아래와 같은 요청을 보낸다고 가정해봅시다:
<img src="http://trusted-website.com/transfer?amount=1000&to=attacker_account" style="display:none;">
사용자는 아무런 의심 없이 해당 페이지를 방문했고, img 태그에 적힌 src 주소의 서버로 특정 요청을 보냅니다. 이 때, 서버는 해당 요청(transfer?amount=1000&to=attacker_account)을 정상적인 사용자 요청으로 받아들이고, 결과적으로 공격자의 계정으로 돈이 이체됩니다.
아주 단순하고, 있을 수 없을 것 같은 사례처럼 보이지만, CSRF 는 교묘하게 동작하기 때문에, 조금이라도 소홀할 수 있는 보안의 허점을 노리는 만큼 그 여파는 무시하지 못할 정도로 큽니다.
CSRF 방지 방법
그럼 이를 방지하기 위해서는 어떤 조치를 취해야 할까요? 몇 가지는 정리해 봤습니다.
- CSRF 토큰 사용: 각 요청에 대해 고유한 토큰을 발행하고, 서버는 요청 시 이 토큰을 확인하여 유효성을 검증합니다. 즉, 서버에서 클라이언트가 자격 증명을 얻을 때, CSRF 토큰을 같이 보내고, 클라이언트에서는 요청을 보낼 때 해당 CSRF 토큰을 같이 보냄으로서 서버는 해당 토큰이 처음 발급된 토큰이 맞는지 검증하고, 통과를 하는 경우 요청을 처리하고 응답하게 됩니다. 활용 사례는 Auth.js 를 사용해보시면 소셜 로그인 시 CSRF 가 스토로지에 저장되어 있는 걸 볼 수 있습니다.
- Referer 헤더 검사: 요청의 출처를 확인하여 신뢰할 수 있는 출처에서 온 요청인지 확인합니다. 이는 악의적인 웹 사이트로 사용자의 방문을 유도하고, 해당 사이트에서 유저가 로그인한 사이트의 백엔드로 요청을 보내게 됩니다. 이 때, Referer 헤더에는 요청을 보낸 사이트의 도메인 주소를 포함하고 있기 때문에, 서버에서는 해당 헤더를 검사해서 CSRF 를 방지할 수 있습니다. 참고로 CSP(컨텐츠 보안 정책) 헤더 설정을 통해서도 방지할 수 있습니다.
- SameSite 속성 설정: 쿠키의 SameSite 속성을 설정하여 크로스 사이트에서의 쿠키 전송을 제한합니다.
- 정확한 CORS 설정: 적절한 Cross-Origin Resource Sharing (CORS) 설정을 통해 신뢰할 수 있는 도메인에서만 요청을 허용합니다. 이는 요청을 보내는 주소의 Origin 을 명확히 해서 프로토콜, 도메인, 포트가 서버에서 요구하는 주소 체계와 동일하지 않으면 해당 HTTP 요청을 차단하는 것입니다.
예를 들어, 백엔드 서버에서 https://www.example.com 이라는 주소의 출처만 허용 했다고 가정해봅시다. 이 떄, http://www.example.com 이라는 주소로 서버에 요청을 보내면, 어떻게 될까요?
정답)
정답은 차단한다 입니다. 왜 그럴까요? 바로 https 와 http 라는 프로토콜이 서로 다르기 때문입니다.
오늘은 CSRF 에 대해서 정리해보는 시간을 가졌습니다. 위에서 언급한 예시와 대처법은 극히 일부에 불과하고, 정말 악의적으로 접근하는 CSRF 는 저리 단순한 형태가 아닐겁니다. 그 만큼 갈수록 수법은 고도화되고 있고, 서버에서 보안과 관련한 처리를 엄격하게 해야하는 이유이기도 하겠죠. 이 글을 정리하고 있는 시점에도 본인의 사이트에는 그러한 처리가 되어 있는가 물어본다면 허점이 많지 않을까 생각이 듭니다. 한 번 살펴보면서 심각한 문제가 없을지 찾아보는 시간을 가져봐야 겠네요.
테스트 관련 개념
테스트를 왜 하세요?
우리는 인간이고 인간은 실수를 합니다. 테스트는 이러한 실수를 발견하고 코드가 작동하는지 확인하는 데 도움이 되기 때문에 중요합니다. 아마도 더 중요한 것은 테스트를 통해 향후 새로운 기능을 추가하거나 기존 기능을 리팩터링하거나 프로젝트의 주요 종속성을 업그레이드할 때 코드가 계속 작동하는지 확인하는 것입니다.
테스트에는 생각보다 더 많은 가치가 있습니다. 코드의 버그를 수정하는 가장 좋은 방법 중 하나는 이를 노출하는 실패한 테스트를 작성하는 것입니다. 그런 다음 버그를 수정하고 테스트를 다시 실행할 때 통과하면 버그가 수정되었으며 코드 베이스에 다시 도입되지 않음을 의미합니다.
테스트는 팀에 합류하는 새로운 사람들을 위한 문서 역할을 할 수도 있습니다. 이전에 코드베이스를 본 적이 없는 사람들의 경우 테스트를 읽으면 기존 코드가 어떻게 작동하는지 이해하는 데 도움이 될 수 있습니다.
마지막으로, 자동화된 테스트는 수동 QA 에 소요되는 시간을 줄여 귀중한 시간을 확보할 수 있다는 것을 의미합니다.
정적 분석
코드 품질을 향상시키는 첫 번째 단계는 정적 분석 도구를 사용하는 것입니다. 정적 분석은 코드를 작성할 때 코드에 오류가 있는지 확인하지만 해당 코드를 실행하지는 않습니다.
Linter는 코드를 분석하여 사용되지 않는 코드와 같은 일반적인 오류를 포착하고 함정을 피하는 데 도움을 주며, 공백 대신 탭을 사용하는 것과 같은 스타일 가이드 no-nos에 플래그를 지정합니다(또는 구성에 따라 그 반대).
타입 검사(ex. 타입스크립트 )는 함수에 전달하는 구문이 함수가 허용하도록 설계된 구문과 일치하는지 확인하여 예를 들어 숫자를 기대하는 계산 함수에 문자열이 전달되는 것을 방지합니다.
테스트 가능한 코드를 만드는 것
테스트를 시작하려면 먼저 테스트 가능한 코드를 작성해야 합니다. 항공기 제조 공정을 생각해 보세요. 모든 복잡한 시스템이 서로 잘 작동하는지 보여주기 위해 모델이 처음 이륙하기 전에 개별 부품을 테스트하여 안전하고 올바르게 작동하는지 확인합니다. 예를 들어, 날개는 극심한 하중 하에서 구부려 테스트됩니다. 엔진 부품의 내구성 테스트를 거쳤습니다. 앞유리는 시뮬레이션된 새 충격에 대해 테스트되었습니다.
소프트웨어도 비슷합니다. 여러 줄의 코드가 포함된 하나의 거대한 파일에 전체 프로그램을 작성하는 대신, 전체를 테스트하는 것보다 더 철저하게 테스트할 수 있는 여러 개의 작은 모듈에 코드를 작성합니다. 이러한 방식으로 테스트 가능한 코드를 작성하는 것은 깔끔한 모듈식 코드 작성과 얽혀 있습니다.
앱을 더욱 테스트 가능하게 만들려면 앱의 보기 부분(React 구성요소)을 비즈니스 로직 및 앱 상태(Redux, MobX 또는 기타 솔루션 사용 여부에 관계없이)에서 분리하는 것부터 시작하세요. 이렇게 하면 React 구성 요소에 의존해서는 안 되는 비즈니스 로직 테스트를 주로 앱의 UI를 렌더링하는 구성 요소 자체와 독립적으로 유지할 수 있습니다!
이론적으로는 구성 요소에서 가져오는 모든 논리와 데이터를 이동할 수도 있습니다. 이렇게 하면 구성 요소가 렌더링에만 전념하게 됩니다. 귀하의 상태는 귀하의 구성 요소와 완전히 독립적입니다. 앱의 로직은 React 구성 요소 없이도 작동합니다!
| 이 부분은 이렇게 생각해볼 수 있습니다. 예를 들어 FoodList 컴포넌트가 있고, 그 상위에는 FoodPage 라는 컴포넌트가 있다고 해봅시다 즉, FoodPage 내에 FoodList 가 자식 구성 요소로 있는 것이죠. 이 떄 FoodList 는 부모 컴포넌트인 FoodPage 로 부터 데이터를 props 으로 전달 받는다면 어떨까요? 이렇게 되면 props 으로 전달된 데이터를 FoodList 는 받아서 렌더링하기만 하면 되므로 View 로서 역할만 수행하면 됩니다. |
CSS / HTML 관련 개념
px, em, rem 의 차이
px 는 고정 단위로서 화면의 해상도와 상관없이 항상 동일한 크기를 가집니다. 주로 정확한 크기를 지정할 떄 하죠.
반면 em 와 rem은 상대적인 단위입니다. 그 중 em 은 부모 요소의 font-size 에 따라서 계산되는 값이 달라지는데, 예를 들어, 부모 요소의 font-size 가 16px 라면, 2em 은 32px 가 됩니다.
rem 의 경우에는 em과 유사하지만, 상위 부모 요소가 아니라 최상위 HTML 요소를 기준으로 결과가 달라집니다. 즉, html 태그를 기준으로 만일 font-size 가 16px 라면 2rem 은 32px 로 계산이 됩니다.
반응형 웹을 구현하는 경우 px, em, rem 중 무엇을 주로 사용하면 좋을까요?
이는 정답은 없다고 봅니다. 다만, px 의 경우에는 절대적인 단위이므로 화면의 해상도가 넓든 좁든 동일한 크기로 계산되므로 반응형 웹을 구현할 때 제약사항이 많습니다. 따라서 em 과 rem 중에서 사용하면 좋은데, 이 때 중요한 것은 em 단위로 지정한 요소의 부모 font-size 가 자주 변동되어 레이아웃의 일관성을 유지하는데 방해가 된다면, em 보다는 rem을 사용하여 전체적인 레이아웃의 일관성을 가져가는 편이 좋다고 봅니다.
vw 과 vh 의 차이
보통 height 과 width 의 최대 넓이를 고정할 때 사용하는 상대적인 단위인데 여기서 v 는 viewport 의 약자입니다. 즉, 뷰포트의 상대적인 width와 height에 따라 값이 결정되는데, 1vw 는 뷰포트 width가 100% 라면 그 중 1%에 해당하는 값이 되며, 1vh 도 뷰포트의 height가 100% 일 때 그 중 1%의 비율을 나타냅니다. 이러한 특징으로 인해 100vw 를 하게 되면 브라우저의 전체 가로 길이를 가득 채우는 형태로 요소가 배치되는 것 이죠.
이 외에도 앞서 단위를 포함해서 다양한 단위가 있습니다. 글로만 보기에는 제한이 따르기 때문에, 스니펫 형태로 준비해 보았습니다.
/* 절대적 단위 */
.absolute-example {
width: 1in; /* 1 인치 */
height: 2.54cm; /* 2.54 센티미터 */
margin: 10mm; /* 10 밀리미터 */
font-size: 12pt; /* 12 포인트 */
}
/* 상대적 단위 */
.relative-example {
width: 50%; /* 부모 요소 너비의 50% */
height: 2em; /* 부모 요소 폰트 크기의 2배 */
padding: 1rem; /* 루트 요소 폰트 크기의 1배 */
margin: 10vw; /* 뷰포트 너비의 10% */
font-size: 3vh; /* 뷰포트 높이의 3% */
line-height: 1.5lh; /* 요소의 줄 높이의 1.5배 */
}
반응형 브레이크 포인트
보통 반응형 레이아웃을 구성할 때, 다양한 장치 크기에 맞춘 레이아웃을 지정하기 위해 브레이크 포인트를 지정하게 됩니다. 일반적으로 다음과 같은 기준에 따라서 선택하죠.
320px: 작은 모바일 장치
480px: 작은 모바일 장치(세로)
768px: 태블릿
1024px: 작은 데스크탑 및 큰 태블릿(가로)
1200px: 데스크탑
1440px: 큰 데스크탑
물론 이는 프로젝트 상황에 따라서 위와 다르게 세밀하게 조정될 수도 있습니다.
CSS 선택자 우선순위
CSS 는 상속 구조로 부모의 프로퍼티를 자식에게 상속하는 방식으로 구현이 되는데요. 보통 다음과 같이 우선순위가 계산 됩니다.
인라인 스타일 : <div style ='color:red'/> (우선순위: 1000)
-> ID 선택자 : #id (우선순위: 100)
-> 클래스 선택자 = 속성 선택자 = 가상 클래스 : .container, [type="text"], :hover (우선순위: 10)
-> 요소 선택자 및 가상 요소: div, p, ::before, ::after 등 (우선순위: 1)
-> 전체 선택자: * { color:black; }
페이지가 변해도 항상 같은 비율을 유지하는 요소를 만드려면
페이지가 변해도 항상 같은 비율을 유지하게 만드려면 padding-top 혹은 padding-bottom 을 이용하거나 최근에 자주 사용되는 aspect-ratio 에 직접 종횡비를 지정해주면 됩니다.
해당 ratio 속성이 없을 때는 padding-top 을 사용하였는데, 아래와 같이 사용할 수 있습니다. aspect-ratio 를 적용하는 컨테이너 요소에 padding-top 을 지정하여 종횡비를 계산하고, 그 자식 요소가 부모 영역의 전체를 가득차도록 해서 비율을 유지하게 만들 수 있습니다.
.aspect-ratio-16-9 {
position: relative;
width: 100%;
padding-top: 56.25%; /* 9 / 16 * 100 */
}
.aspect-ratio-16-9 > * {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
앞서 복잡한 계산 보다는 아래와 같이 aspect-ratio 속성을 추가해주기만 해도 깔끔하게 유지할 수 있겠습니다.
.container {
width: 100%;
aspect-ratio: 16 / 9; /* 16:9 비율 */
background-color: lightblue;
}
해당 속성의 경우에는 이전에 봤을 때만 해도 일부 브라우저에서 지원을 안 해준 것으로 아는데, 이제는 모든 브라우저에서 지원을 해주네요.

Flex 박스 | 1차원 레이아웃 모델로서, 요소들을 행이나 열 형태로 배치 시 사용
1차원 레이아웃 모델로, 아이템의 정렬과 배치를 쉽게 만들어 줍니다. 보통 요소들을 행이나 열 형태로 배치할 때 사용하고, 주로 다음과 같은 속성들을 지니고 있습니다.
컨테이너 속성
- display: flex 또는 inline-flex
- flex-direction: row 혹은 column
- flex-wrap: 자식 요소의 줄 바꿈 설정
- justify-content: 주 축 정렬(flex-start 혹은 end, center, space-between 등이 있음(모양: ㅡ )
- align-items: 교차 축 정렬(stretch, center, flex-start 등)( 모양: | )
- align-content: 여러 줄의 교차 축 정렬
아이템 속성
- order: 요소의 순서 변경
- flex-grow: 남은 공간을 어떻게 나눌지 설정
- flex-shrink: 공간이 부족할 때 요소가 어떻게 줄어들지 설정
- flex-basis: 요소의 기본 크기 설정
- align-self: 특정 요소의 교차 축 정렬
float 의 동작원리
요즘에는 flex 와 grid 를 사용해서 잘 사용되지 않지만, float는 그 전 까지만 해도 자주 사용되는 속성 중 하나였습니다. float는 요소를 왼쪽 또는 오른쪽으로 띄우고, 요소를 다른 텍스트나 인라인 요소들이 주위에 감싸도록 만드는 기능을 합니다.
float는 기본적으로 띄워진 요소 주위에 감싸는 요소들이 생기기 때문에, 약간의 레이아웃 왜곡이 발생할 수 있습니다. 따라서 해당 문제를 해결하기 위해 clear 속성을 별도로 적용해주는데, both 로 지정하면, left, right 값이 지정한 float 의 영향을 받은 다음 요소가 영향을 미치지 못하도록 방지해주는 역할을 합니다.
CSS 에서 Cacading
캐스캐이딩은 여러 CSS 규칙이 동일한 요소에 적용될 때, 어떤 규칙이 최종적으로 적용될지를 결정하는 메커니즘 입니다. 보통 다음 3 가지 주요 원칙을 따라 진행됩니다.
- 우선순위: 선택자의 우선순위에 따라 결정
- 출처: 브라우저 기본 스타일 < 사용자 스타일 시트 < 작성자 스타일 시트 순으로 우선순위가 적용됩니다.
- 명시도: 동일한 우선순위와 출처의 규칙 중 나중에 선언된 규칙이 우선합니다.
SCSS
Sassy CSS 라고 불리는 SCSS 는 SASS 의 확장된 문법 입니다. CSS 와 유사한 구문을 사용하는 CSS 전처리 프레임워크로서 일반적으로 다음과 같은 기능을 제공합니다.
- 변수: 스타일 속성에 사용할 값을 변수로 저장
- 중첩: CSS 선택자를 중첩하여 구조적으로 작성(CSS 에서도 이제 지원해줍니다.)
- 파셜: 여러 파일로 코드를 분할하고, @import 를 통해서 불러올 수 있습니다.
- 믹스인: 재사용 가능한 코드를 분리하여 @incloud 를 통해 사용할 수 있습니다.
- 확장: 기존 클래스의 스타일을 상속합니다.
- 함수: 복잡한 계산을 수행하고 값을 반환할 수 있습니다.
아래는 위 개념을 일부 적용한 간단한 예시 입니다. 한 번 참고해보세요.
$primary-color: #333; // 변수 선언
body {
font-family: Arial, sans-serif;
color: $primary-color; // 변수 사용
.container { // 중첩 사용
margin: 0 auto;
padding: 1rem;
width: 100%;
}
}
@mixin box-shadow($shadow) { // 재사용 가능한 코드 블록 생성
-webkit-box-shadow: $shadow;
-moz-box-shadow: $shadow;
box-shadow: $shadow;
}
.box {
@include box-shadow(0 4px 8px rgba(0, 0, 0, 0.1)); // 코드 블록 사용
}
position 속성에 대한 정리
position 속성은 요소의 배치 방법을 지정하는데 사용 합니다. 기본적으로 아래와 같은 값을 가질 수 있습니다.
- static: 기본값으로 요소가 문서 흐름에 따라 배치됩니다.
- relative: 요소를 원래 위치를 기준으로 이동 합니다. 즉, 위 아래로 이동 시킬 수는 없으나 좌우로는 left와 right 를 통해 이동할 수 있습니다.
- absolute: 요소를 DOM 트리의 루트와 가장 가까운 조상 요소를 기준으로 이동 합니다. 만일 조상 요소가 relative, absolute, fixed 가 지정된 경우에 해당 조상 요소를 기준으로 배치됩니다.
- fixed: 뷰포트를 기준으로 고정이 되며, 스크롤 해도 그 자리에 고정됩니다.
- sticky: 스크롤 위치에 따라 'relative', 'fixed' 를 전환 합니다.
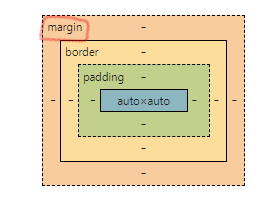
margin 과 padding | (전자) 요소 경계 바깥 공간, (후자) 요소 경계 안쪽 공간
margin 은 요소의 경계 바깥에 있는 공간을 지정할 때 사용합니다. padding 요소의 경계 안쪽에 있는 공간을 지정합니다.
HTML 렌더링 시 자바스크립트가 실행되면 렌더링이 멈추는 이유
자바스크립트 코드는DOM 을 조작하고 스타일을 변경할 수 있기 때문에, 브라우저는 불필요한 레이아웃 재계산을 피하기 위해 자바스크립트를 먼저 실행하고, 렌더링을 이어 갑니다. 이 과정에서 렌더링이 잠시 중단될 수 있습니다.
CSS 박스 모델
앞서 margin 과 padding 부분에서 첨부한 박스가 CSS 박스 모델입니다. margin, border, padding, content 로 구성되고, 보통 요소의 가로 넓이를 계산할 때 앞서 속성에 지정된 px 값을 모두 포함시킵니다. 즉, 실제로 width:100px 으로 지정했음에도 margin, padding, border 에 지정된 px 크기 만큼 100px+ 알파 가 됩니다.
만일 width:100px 로 지정 시 요소의 크기가 100px 에 딱 맞추고자 한다면, 해당 요소에 box-sizing:border-box 로 지정해주면 됩니다. 이렇게 되면 콘텐츠의 width 를 계산 시 100px 에 맞춰 그 공간을 나눠 가지게 됩니다.
Attribute 와 Property 의 차이 | (전자) HTML 요소의 속성, (후자) 그 속성을 JS의 . 표기법으로 접근한 것
Attribute 는 HTML 태그 내에서 지정하는 값입니다. 문자열 형태로 저장이 되는데, <input type="text"/> 에서 type 이 Attribute 입니다.
Property 는 DOM 객체의 속성입니다. 자바스크립트로 접근할 수 있습니다. 예를 들어 <input value="감자"/> 라는 HTML 태그가 있다고 가정해봅시다. 여기서 HTML 태그 내에 지정된 value 은 Attribute 이지만 자바스크립트를 통해서 input.value 으로 접근 시의 value은 Property 가 됩니다. 점 표기법을 통해 접근한 속성들은 모두 프로퍼티라고 이해하면 쉽습니다.
<input id="myInput" type="text" value="Hello">
<script>
const input = document.getElementById('myInput');
console.log(input.getAttribute('value')); // "Hello" (attribute)
console.log(input.value); // "Hello" (property)
</script>
display 속성에 대한 설명 | 요소의 박스 생성 방식 지정
display 는 요소의 박스를 생성하는 방식을 지정합니다. 보통 다음과 같은 속성들을 지니고 있습니다. 그 중에서 grid, flex, block, inline-block 이 자주 사용되지요.
- block: 요소를 블록 레벨 요소로 지정하고, 전체 넓이를 차지하도록 합니다.
- inline: 요소를 인라인 레벨 요소로 지정하고, 콘텐츠 넓이 만큼만 너비를 차지합니다.
- inline-block: 인라인 레벨 요소처럼 콘텐츠 넓이를 차지하지만, block 속성으로 지정된 요소가 가질 수 있는 모든 속성을 가질 수 있습니다.
- flex: 요소를 플렉스 컨테이너로 지정합니다.
- grid: 요소를 그리드 컨테이너로 지정합니다.
- inline-flex 과 inline-grid: 기존 flex 와 grid 는 블랙 레벨 요소 처럼 동작하지만, 이들은 인라인 레벨 요소처럼 컨테이너를 지정합니다.
- table: 테이블 레이아웃을 지정합니다. 거의 사용되지 않습니다.
CSS 애니메이션과 JS 애니메이션
CSS 애니메이션은 @keyframes 와 애니메이션 속성을 사용하여 정의합니다. 간단한 애니메이션에 적합했으나, 최근에는 복잡한 애니메이션도 생성이 가능하도록 영역이 확장되는 중입니다. 브라우저의 하드웨어 가속을 사용하기 때문에 성능이 우수한 편입니다.
JS 애니메이션은 자바스크립트를 사용하여 애니메이션을 조작하므로 CSS 만을 사용한 것 보다 정교하고 복잡한 애니메이션을 만들 수 있습니다. 보통 .animate 메소드를 사용하여 첫 번째 인자에는 키프레임을 두 번째 인자에는 애니메이션 실행에 필요한 옵션을 지정하여 간단펴하게 사용할 수 있습니다.
document.getElementById("alice").animate(
[
{ transform: "rotate(0) translate3D(-50%, -50%, 0)", color: "#000" },
{ color: "#431236", offset: 0.3 },
{ transform: "rotate(360deg) translate3D(-50%, -50%, 0)", color: "#000" },
],
{
duration: 3000,
iterations: Infinity,
},
);
CSS in JS 의 장점과 단점 | JS를 동적으로 적용해서 편하지만, 코드 길어지면 오히려 복잡
JS 와 함꼐 CSS 를 작성하여 관리할 수 있으므로 컴포넌트 기반 스타일링을 통한 코드베이스의 일관성과 글로벌 네임 스페이스 오염을 방지하는 장점이 있습니다. JS 를 사용해서 동적으로 스타일을 변경할 수 있으므로 보다 유연한 코드를 작성할 수도 있습니다.
하지만, 런타임 시 스타일 생성이 이루어지므로 이로 인한 성능 저하가 발생할 수 있습니다 .CSS 와 JS 가 결합한 형태이므로 코드가 길어질 경우 코드 복잡성이 커지고, 오히려 코드와 CSS 를 구분하기 어려워 코드 가독성을 저해할 수 있습니다.
BEM 방법론(Block Element Modifier) | 클래스 네이밍 규칙에 대한 방법론 중 하나
BEM은 클래스 네이밍 규칙으로, 블록(block), 요소(element), 수정자(modifier)를 결합하여 CSS 구조를 명확하고 유지보수하기 쉽게 만듭니다. .button__icon--large. 와 같이 클래스를 네이밍 합니다.
반응형 웹 디자인 | 다양한 디바이스 환경에 호환되는 방식으로 디자인 하는 것
반응형 웹 디자인은 다양한 디바이스와 화면 크기에 맞춰 웹 페이지가 자동으로 레이아웃을 조정하는 기술로, 주로 미디어 쿼리(@media)와 유연한 그리드 레이아웃을 사용해 구현됩니다.
미디어 쿼리(Media Queries)
설명: 화면 크기, 해상도, 방향(가로/세로) 등에 따라 스타일을 다르게 적용하는 CSS 규칙입니다.
@media (max-width: 768px) {
body {
background-color: lightblue;
}
.container {
padding: 10px;
}
}
유연한 그리드 레이아웃(Flexible Grid Layout)
설명: 비율 기반의 그리드 시스템을 사용하여 콘텐츠가 다양한 화면 크기에 맞게 조정됩니다. 상대적인 단위인 퍼센트(%)를 사용해 레이아웃을 구성합니다. 아래 예제에서 auto-fill 속성을 사용하면, 자동으로 빈 그리드 영역 만큼 각 셀의 크기를 조절합니다.
.container {
display: grid;
grid-template-columns: repeat(auto-fill, minmax(200px, 1fr));
}
유연한 이미지 및 미디어(Flexible Images and Media)
설명: 이미지와 비디오가 화면 크기에 맞게 자동으로 조정되도록 설정합니다. max-width: 100%를 사용하여 이미지가 부모 요소의 너비를 초과하지 않도록 합니다.
img {
max-width: 100%;
height: auto;
}
모바일 우선 디자인(Mobile-First Design)
설명: 모바일 디바이스를 기준으로 기본 스타일을 설정하고, 더 큰 화면을 위한 추가 스타일을 미디어 쿼리를 사용해 적용하는 접근 방식입니다.
/* 기본 모바일 스타일 */
body {
font-size: 14px;
}
@media (min-width: 768px) {
/* 태블릿 및 데스크톱 스타일 */
body {
font-size: 16px;
}
}
유연한 타이포그래피(Flexible Typography)
설명: 텍스트의 크기와 레이아웃이 화면 크기에 맞춰 조정되도록 합니다. 상대 단위(em, rem, %)를 사용하여 텍스트 크기를 설정합니다.
/* 모바일에서는 기본 폰트 크기로 */
body {
font-size: 1rem; /* 기본 폰트 크기 */
}
/* 태블릿 및 데스크톱에서 더 큰 폰트 크기 */
@media (min-width: 768px) {
body {
font-size: 1.25rem; /* rem은 루트 요소의 폰트 크기의 상대적 배수 단위: 14px*1.25 */
}
}
뷰포트(Viewport) 설정
설명: 브라우저의 뷰포트를 설정하여 페이지가 다양한 화면에서 올바르게 표시되도록 합니다. <meta> 태그를 사용하여 뷰포트 설정을 적용합니다.
<meta name="viewport" content="width=device-width, initial-scale=1.0">
시멘틱 마크업 | HTML 요소를 그 의미에 맞게 사용하는 것
HTML 요소가 그 의미에 맞게 사용되는 것을 의미합니다. 시멘틱 마크업에 따라 요소를 배치하면 크롤링 봇이 사이트의 구조를 파악하는 데 도움을 주므로 SEO 에도 도움이 되됩니다. 명확한 의미에 따라 구조가 설계되면, 코드의 가독성이 높아질 수 있습니다. 또한 스크린 리더기를 사용하는 사용자에게 보다 명확한 구조 설명이 가능하여 정보 접근성을 향상시킬 수 있습니다.
- header: 문서나 섹션의 머리말
- nav: 네비게이션 링크
- main: 문서의 주요 콘텐츠
- section: 콘텐츠의 주제별 섹션
- article: 독립적으로 구분된 콘텐츠
- aside: 부가적인 콘텐츠
- footer: 문서나 섹션의 바닥글
offsetWidth 와 offsetHeight | margin 을 제외하고 border 을 포함한 요소의 높이와 가로 길이를 알고 싶을 때

clientWidth 와 clientHeight | margin 과 border 을 제외한 padding 까지만 포함한 요소의 높이와 가로 넓이를 알고 싶을 때
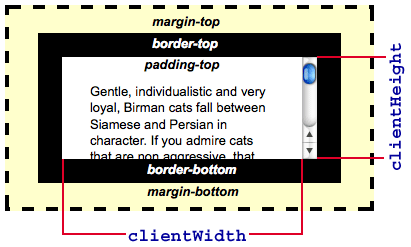
scrollWidth 와 scrollHeight | 보여지는 크기가 아닌 실제 요소의 높이와 가로 길이를 알고 싶을 때.
해당 속성들은 실제 요소가 브라우저에서 차지는 픽셀 사이즈를 측정하여 반환해줍니다. 예를 들어, 600x400(px) 이 되는 요소가 있다고 할 때, 사용자는 화면상에서 300x300(px) 을 보고 있습니다. 즉, 요소 전체를 보려면 스크롤해야 볼 수 있게 되는데, scrollWidth와 scrollHeight 는 사용자에게 현재 보여지는 요소의 크기가 아니라, 실제 해당 요소의 전체 크기를 측정하여 반환해줍니다.
CSSOM(CSS 객체모델) | JS 에서 CSS를 조작할 수 있도록 해주는 API 집합
CSS Object Model 은 JavaScript에서 CSS를 조작할 수 있는 API 집합입니다. HTML 대신 CSS가 대상인 DOM이라고 생각할 수 있으며, 사용자가 CSS 스타일을 동적으로 읽고 수정할 수 있는 방법입니다.
블록 레벨 콘텐츠(요소) | 블록 레이아웃(각 행 마다 세로로 공간을 차지하는 레이아웃)을 구성하는 요소
블록 레벨 요소는 일반적으로 새로운 줄에서 시작되며, 기본적으로 가로 전체의 너비를 차지합니다. 블록 레벨 요소는 다른 블록 레벨 요소 또는 인라인 요소를 포함할 수 있습니다.
일반적으로 사용되는 블록 레벨 요소들은 다음과 같습니다
| <div>: 가장 일반적인 블록 레벨 요소로, 별도의 의미를 가지지 않고 구획을 나누거나 스타일을 적용하기 위해 사용됩니다. <p>: 단락을 나타내는 요소로, 텍스트 블록을 구성합니다. 제목 요소(<h1>부터 <h6>): 문서의 제목을 나타내는 요소로, 중요도에 따라 제목의 수준을 지정합니다. 목록 요소(<ul>, <ol>, <dl>): 항목들을 나열하는 목록을 만들기 위해 사용됩니다. <ul>은 순서 없는 목록, <ol>은 순서 있는 목록, <dl>은 설명 목록을 나타냅니다. <blockquote>: 인용문을 나타내는 요소로, 텍스트를 들여쓰기하여 인용 부분을 구분합니다. <pre>: 사전 서식화된 텍스트를 나타내는 요소로, 텍스트를 그대로 표시하며 공백과 줄 바꿈을 유지합니다. |
이외에도 무수히 많은 블록 레벨 요소들이 있지만, 글이 길어질 것 같아서 여기서 마무리 합니다.
script 태그에서 async 와 defer 의 차이
두 속성 다 비동기적으로 스크립트를 다운로드 하는 것은 동일하지만 실행하는 타이밍에는 차이가 존재합니다.
async 는 스크립트를 비동기적으로 로드하고 실행합니다. HTML 파싱과 스크립트 실행이 병렬로 이루어지며, 스크립트 로드가 완료되는 즉시 실행 됩니다(HTML 파싱 이전 실행 가능).
defer 는 스크립트를 비동기적으로 로드하지만, HTML 파싱이 완료된 후 스크립트를 실행합니다. 따라서 스크립트가 HTML 파싱을 방해하지 않고, 실행 순서가 HTML 문서에 나타나는 순서를 따릅니다(HTML 파싱 후 순차 실행).
가상 클래스 | 특정 상태에 따른 요소 스타일을 적용 시 사용(ex. :hover, :active 등)
CSS 가상 클래스는 특정 상태에 따라 요소에 스타일을 적용하는 데 사용 됩니다. 주요 가상 클래스를 나열해보면 아래와 같습니다.
- :hover: 요소에 마우스 포인터가 올라갔을 때,
- :active: 요소가 활성화 되었을 때(클릭 시)
- :focus: 요소가 포커스를 받았을 때,
- :visited: 방문한 링크
- :nth-child(n) : 특정 자식 요소
margin 병합 | 상하 인접한 블록 요소의 마진이 합쳐지는 현상(더 큰 margin 으로 적용)
마진 병합은 상하 인접한 블록 요소의 마진이 합쳐지는 현상을 의미합니다. 두 요소의 마진이 만나면, 두 마진 중 큰 값이 적용됩니다. 아래의 경우 p 태그의 30px 를 기준으로 div 와 p 태그 사이에 여백이 생성됩니다.
div {
margin: 20px 0;
}
p {
margin: 30px 0;
}자바스크립트
이벤트 위임 | 이벤트를 자식 요소에 직접 바인딩하는 대신, 공통된 상위 요소에 이벤트를 바인딩
이벤트 위임(Event Delegation)은 웹 개발에서 DOM 이벤트를 효율적으로 처리하는 기법입니다. 기본적으로 이벤트를 자식 요소에 직접 바인딩하는 대신, 공통된 상위 요소에 이벤트를 바인딩하여 자식 요소의 이벤트를 처리하는 방식입니다.
어떻게 동작하는가?
- 이벤트 버블링(Event Bubbling): DOM 트리에서 이벤트가 발생하면, 그 이벤트는 해당 요소에서 시작하여 상위 요소로 전파됩니다. 예를 들어, li 요소에 클릭 이벤트가 발생하면, 그 이벤트는 상위 요소인 ul을 거쳐 body까지 전파됩니다.
- 이벤트 위임: 이벤트 위임은 이 이벤트 버블링을 활용하는 방법입니다. 여러 자식 요소에 개별적으로 이벤트 리스너를 붙이는 대신, 부모 요소에 하나의 이벤트 리스너를 붙입니다. 이후 이벤트가 버블링되면 부모 요소에서 이벤트를 처리합니다. 이때 이벤트가 발생한 자식 요소를 식별하여 해당 요소에 대해 특정 작업을 수행할 수 있습니다.
장점
- 효율성: 많은 자식 요소가 있을 때, 각각의 자식 요소에 이벤트 리스너를 부착하는 대신 하나의 리스너만 사용하기 때문에 메모리와 성능 측면에서 효율적입니다.
- 동적 요소 처리: 동적으로 추가된 자식 요소도 별도로 리스너를 추가할 필요 없이 상위 요소에서 이벤트를 처리할 수 있습니다.
<ul id="parent-list">
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<script>
document.getElementById('parent-list').addEventListener('click', function(event) {
if(event.target.tagName === 'LI') {
alert('You clicked on ' + event.target.innerText);
}
});
</script>
위의 코드에서 ul 요소에만 이벤트 리스너를 추가했지만, 각 li 요소에 대한 클릭 이벤트를 모두 처리할 수 있습니다. 이런 방식이 바로 이벤트 위임입니다.
브라우저에서 화면은 어떻게 그려지는가
자바스크립트는 역사적으로 브라우저에서 실행되는 코드 이므로 브라우저에서 화면이 어떻게 그려지는지에 대해서 아는 것은 매우 중요합니다. 이번 시간에는 해당 원리에 대해서 정리해봅니다.
HTML 파싱 및 DOM 트리 구성
- HTML 파싱: 브라우저가 HTML 문서를 읽으면, 이를 파싱(구문 분석)하여 DOM 트리(Document Object Model)를 구성합니다. DOM 트리는 HTML 문서의 구조를 트리 형태로 표현한 것으로, 각 HTML 요소는 DOM 트리의 노드로 변환됩니다.
- DOM 트리 구성: 이 트리는 HTML의 요소와 그 관계(부모-자식 관계)를 나타내며, 웹 페이지의 구조를 나타냅니다.
<body>
<div>
<h1>Hello, World!</h1>
</div>
</body>
위 HTML은 다음과 같은 DOM 트리로 변환됩니다.
Document
└── <html>
└── <body>
└── <div>
└── <h1>
└── "Hello, World!"CSS 파싱 및 스타일 계산
- CSS 파싱: CSS는 브라우저에 의해 파싱되어 CSSOM(CSS Object Model) 트리를 생성합니다. 이 트리는 CSS 규칙과 그 규칙이 적용될 요소를 나타냅니다.
- 스타일 계산: 브라우저는 DOM 트리와 CSSOM 트리를 결합하여 각 요소에 적용될 최종 스타일을 계산합니다. 이 단계에서는 상속된 스타일, 기본값, 그리고 CSS의 우선순위 규칙들이 적용됩니다.
렌더 트리 생성렌더 트리 구성
브라우저는 DOM 트리와 CSSOM 트리를 사용해 렌더 트리를 생성합니다. 렌더 트리는 시각적으로 표시될 요소들만 포함하며, 각 노드는 화면에 어떻게 그려질지를 나타냅니다.
| 렌더 트리는 실제 화면에 그려질 요소들만 포함하며, display: none으로 숨겨진 요소들은 포함되지 않습니다. 렌더 트리에는 각 요소의 위치와 크기(레이아웃) 정보도 포함됩니다. |
레이아웃 계산 | 각 요소의 정확한 위치와 크기 계산
- 레이아웃 단계: 렌더 트리가 생성되면, 각 요소의 정확한 위치와 크기를 계산합니다. 이 단계는 레이아웃 또는 리플로우라고 불리며, 브라우저가 요소들의 위치를 결정하는 과정입니다.
- 박스 모델: 이 과정에서 요소들은 박스 모델을 기반으로 배치되며, 마진, 패딩, 보더, 콘텐츠 영역을 고려해 계산됩니다.
페인팅 (Painting) | 배경색, 텍스트, 이미지 등의 모든 시각적 요소가 픽셀로 변환되어 화면에 그려짐
- 페인팅: 레이아웃 단계에서 계산된 위치와 스타일 정보를 바탕으로, 브라우저는 각 요소를 화면에 그리기 시작합니다. 이 과정에서는 배경색, 텍스트, 이미지 등 모든 시각적 요소가 픽셀로 변환됩니다.
컴포지팅 | 페인팅 동안 여러 레이어를 합성하여 최종적으로 사용자에게 표시될 화면을 생성
페이지의 각 요소들이 그려지면서, 브라우저는 여러 레이어를 합성하여 최종적으로 사용자에게 표시될 화면을 만듭니다. 이 과정은 컴포지팅(Compositing) 이라고 불립니다.
리플로우와 리페인트
- 리플로우(Reflow): DOM이나 CSSOM이 변경되어 레이아웃을 다시 계산해야 하는 경우(예: 요소의 크기나 위치 변경), 브라우저는 리플로우 과정을 거칩니다. 리플로우는 성능에 큰 영향을 미칠 수 있습니다.
- 리페인트(Repaint): 요소의 레이아웃에는 변화가 없고, 스타일만 변경되는 경우(예: 색상 변경), 리페인트가 발생합니다. 리페인트는 리플로우보다 비용이 덜 듭니다.
JavaScript와 이벤트 루프
JavaScript는 DOM과 CSSOM을 동적으로 조작할 수 있으며, 이로 인해 리플로우나 리페인트가 발생할 수 있습니다. 브라우저의 이벤트 루프는 JavaScript가 DOM 조작을 요청할 때 이를 처리하고, 필요한 경우 다시 렌더링을 트리거합니다.
요약
1. 브라우저는 HTML을 파싱해 DOM 트리를 만들고, CSS를 파싱해 CSSOM 트리를 생성합니다.
2. 이 두 트리를 결합해 렌더 트리를 생성한 후, 레이아웃 계산을 통해 요소들의 위치와 크기를 정합니다.
3. 마지막으로 화면에 그리는 페인팅 과정을 통해 사용자에게 웹 페이지를 보여줍니다.
4. JavaScript의 동적 조작에 따라 리플로우와 리페인트가 발생할 수 있습니다.
이러한 과정이 매우 빠르게 진행되어 사용자는 웹 페이지가 즉시 렌더링되는 것처럼 느끼게 됩니다.
Blob
Blob 는 뭘까요?
들어가는 말오늘은 Blob 에 대해서 알아보는 시간을 가져볼까 합니다. 이번에 보고서 정보를 CSV 파일로 변환하는 함수를 작성하게 되었는데, 해당 함수에서 Blob 를 사용했습니다. 사용하는 것과
duklook.tistory.com
함수 스코프와 블록 스코프
여기서 스코프는 유효범위를 의미합니다. 따라서 함수 스코프는 함수의 유효범위, 블록 스코프는 블록의 유효범위를 의미합니다.
함수 스코프를 가지는 키워드는 var 입니다. var 는 if(){ } while(){ } 와 같이 블록 스코프 내에 var 키워드가 있다고 해도, 블록 스코프에 영향을 받지 않기 때문에 전역 변수로서 인식 됩니다. 즉, 외부에서 해당 스코프 내에 있는 var 변수에 접근할 수 있습니다.
반면 function(){ } 와 같이 함수 내부에서 var 키워드가 존재한다면, 외부에서 해당 var 키워드로 선언된 변수에 접근할 수 없습니다.
블록스코프는 let, const 가 이에 따릅니다. 즉, if() { } 내부에서 let 과 const 키워드로 생생된 변수가 있는 경우 외부에서는 이에 접근할 수 없습니다.
자바스크립트는 단일 스레드 기반의 동기적인 언어인데 왜 비동기적으로 실행이 가능함?
자바스크립트가 브라우저든 NodeJS 에서든 비동기적으로 동작할 수 있도록 하는 것에는 이벤트 루프가 핵심적인 역할을 담당합니다. 아래는 이벤트 루프와 관련한 주요 개념과 예시를 정리한 것입니다.
이벤트 루프(Event Loop)
자바스크립트는 싱글 스레드(single-threaded)로 동작하지만, 이벤트 루프를 통해 비동기 작업을 처리합니다. 이벤트 루프는 호출 스택(call stack)과 태스크 큐(task queue) 또는 작업 큐(task queue) 사이에서 작업을 조정하는 역할을 합니다. 동기적인 작업이 호출 스택에서 처리되는 동안, 비동기 작업은 태스크 큐에서 대기하다가 호출 스택이 비워지면 처리됩니다.
콜백 함수(Callback Functions)
비동기 작업을 처리하기 위해 자바스크립트는 콜백 함수를 사용합니다. 예를 들어, setTimeout 함수는 특정 시간 후에 콜백 함수를 호출합니다. 이 콜백 함수는 호출 스택이 비워진 후 이벤트 루프에 의해 실행됩니다.
프로미스(Promises) | 비동기적 작업결과를 처리하는 객체로 처리된 작업의 결과는 큐에 저장합니다.
프로미스는 비동기 작업의 결과를 다루기 위해 제공되는 객체입니다. 프로미스는 비동기 작업이 완료될 때 결과를 반환하고, .then()과 .catch() 메서드를 통해 성공이나 실패를 처리할 수 있습니다. 프로미스는 내부적으로 비동기 작업을 처리하고 그 결과는 큐에 추가되어 호출 스택이 빌 때 까지 대기하게 됩니다.
async와 await | async는 프로미스를 반환하고, await 는 프로미스가 보류 -> 이행 or 거부 까지 대기
async와 await는 프로미스를 더욱 직관적으로 다루기 위한 문법입니다. 즉, 프로미스의 처리를 보다 단순화시킨 문법적 설탕이라 할 수 있습니다. async 함수는 항상 프로미스를 반환하며, await 키워드는 프로미스가 해결될 때까지 기다립니다. 이 방식은 비동기 코드를 동기 코드처럼 작성할 수 있게 해줍니다.
웹 API(Web APIs) | 비동기적 작업을 처리 합니다. 여기서 처리된 작업은 태스크 큐로 이동 합니다.
브라우저나 Node.js 환경에서는 웹 API가 비동기 작업을 처리할 수 있습니다. 예를 들어, 브라우저의 XMLHttpRequest나 fetch API는 네트워크 요청을 비동기적으로 처리합니다. 이러한 API는 자바스크립트가 직접적으로 비동기 작업을 다루지 않고, 결과를 콜백 함수나 프로미스를 통해 받을 수 있게 해줍니다.
이벤트 루프와 관련해서 아래 문서를 추가적으로 살펴보세요!
https://developer.mozilla.org/ko/docs/Web/JavaScript/Event_loop
이벤트 루프 - JavaScript | MDN
JavaScript의 런타임 모델은 코드의 실행, 이벤트의 수집과 처리, 큐에 대기 중인 하위 작업을 처리하는 이벤트 루프에 기반하고 있으며, C 또는 Java 등 다른 언어가 가진 모델과는 상당히 다릅니다.
developer.mozilla.org
이벤트 루프 | 자바스크립트가 비동기적인 것 처럼 동작할 수 있게 해주는 핵심 개념
이벤트 루프(Event Loop)는 JavaScript의 비동기 동작을 처리하는 메커니즘입니다. JavaScript는 싱글 스레드 언어로, 하나의 작업만을 순차적으로 처리합니다. 이벤트 루프는 콜 스택(Call Stack)과 태스크 큐(Task Queue)를 관리하여 비동기 코드(예: 콜백 함수, Promise)가 실행될 수 있도록 합니다.
- 콜 스택: 함수 호출이 쌓이고 실행되는 곳입니다.
- 태스크 큐: 비동기 작업이 완료되면 해당 콜백 함수가 대기하는 곳입니다.
- 이벤트 루프: 콜 스택이 비어 있으면 태스크 큐에서 대기 중인 콜백 함수를 가져와 실행합니다.
이벤트 루프 덕분에 메인 스레드는 블로킹 되지 않을 수 있습니다. 즉, 논 블로킹 방식으로 동작하게 하는 핵심적인 개념이라 할 수 있습니다.
태스크 큐도 사실 유형이 여러가지 라는 사실
매크로 태스크 큐 (Macro Task Queue)
매크로 태스크 큐는 일반적인 비동기 작업(예: setTimeout, setInterval, I/O 작업, UI 렌더링)을 처리합니다.
예) setTimeout, setInterval, I/O 이벤트, message event
마이크로 태스크 큐 (Micro Task Queue)
마이크로 태스크 큐는 더 높은 우선순위를 가지며, 매크로 태스크가 완료된 후 바로 실행됩니다. 보통 프로미스의 처리(Promise.then, Promise.catch)와 같은 작업이 이 큐에 포함됩니다.
예) Promise 콜백, MutationObserver, process.nextTick(Node.js에서).
동작 순서
- 콜 스택이 비어 있는지 확인: 이벤트 루프는 먼저 현재 콜 스택이 비어 있는지 확인합니다. 비어 있다면 다음 단계로 넘어갑니다.
- 마이크로 태스크 큐 확인: 콜 스택이 비어 있으면, 먼저 마이크로 태스크 큐를 확인하고, 그 안에 작업이 있으면 모든 마이크로 태스크를 실행합니다. 마이크로 태스크 큐가 비어 있을 때까지 반복합니다.
- 매크로 태스크 큐 실행: 마이크로 태스크 큐가 비어 있으면, 이벤트 루프는 매크로 태스크 큐에서 하나의 태스크를 가져와 실행합니다.
자바스크립트에서 onClick 이벤트가 등록되고 실행되는 원리
JavaScript에서 onClick과 같은 이벤트가 등록되고 사용되는 원리는 이벤트 리스너(Event Listener)를 통해 이루어집니다. 이 과정은 크게 두 단계로 나뉩니다
이벤트 등록 (Event Registration)
이벤트 리스너 추가: onClick과 같은 이벤트는 특정 DOM 요소에 이벤트 리스너를 추가함으로써 등록됩니다. 이를 위해 addEventListener 메서드나 HTML 속성 방식으로 이벤트를 등록할 수 있습니다.
이때, 브라우저는 이 요소에 특정 이벤트가 발생했을 때 호출할 함수를 기억하게 됩니다. 이 함수는 이벤트 리스너로, 해당 이벤트가 발생하면 실행됩니다.
이벤트 처리 (Event Handling)
이벤트 발생: 사용자가 버튼을 클릭하면 브라우저는 클릭 이벤트를 감지합니다. 이때 클릭 이벤트가 발생한 요소와 그 요소에 등록된 이벤트 리스너를 확인합니다.
이벤트 전달 (Event Propagation): 이벤트는 발생한 요소에서 시작하여 부모 요소로 전파됩니다. 이 과정을 이벤트 전파라고 하며, 크게 캡처링(Capturing) 단계와 버블링(Bubbling) 단계로 나뉩니다.
캡처링: 이벤트가 최상위 부모 요소에서부터 목표 요소까지 전달되는 과정.
버블링: 이벤트가 목표 요소에서부터 다시 최상위 부모 요소로 전파되는 과정.
기본적으로 이벤트 리스너는 버블링 단계에서 실행됩니다. 하지만 캡처링 단계에서 실행되도록 설정할 수도 있습니다.
이벤트 리스너 실행: 이벤트가 발생하고 이벤트가 전파되면, 브라우저는 해당 요소에 등록된 이벤트 리스너(예: handleClick)를 호출합니다. 이 함수는 이벤트 객체를 매개변수로 받아, 이벤트에 대한 세부 정보(예: 클릭 위치, 발생한 요소 등)를 확인하고, 필요한 동작을 수행합니다.
function handleClick(event) {
console.log('Button clicked!', event);
}
종합적인 동작 과정
- 이벤트 리스너가 DOM 요소에 등록됩니다.
- 사용자가 특정 이벤트(예: 클릭)를 발생시킵니다.
- 브라우저는 이벤트가 발생한 요소를 확인하고, 해당 요소에 등록된 리스너를 찾아 실행합니다.
- 이벤트는 요소에서 부모 요소로 전파되며, 전파 과정에서 이벤트 리스너가 실행될 수 있습니다. 이 부분은 부모 요소에 이벤트 리스너를 등록해두고, 자식 요소에도 이벤트 리스너를 등록 후 호출하게 되면, 부모 요소에 등록된 이벤트 리스너도 호출되는 것을 확인할 수 있습니다.
이러한 이벤트 등록과 처리는 JavaScript의 비동기 특성 덕분에 사용자 인터페이스와 상호작용할 때 효율적으로 동작합니다.
이벤트 리스너의 실제
이벤트 리스너는 키-값 구조로 된 목록 형태로 DOM 을 구성하는 모든 요소가 개별적으로 가지고 있습니다. 예를 들어, span, div, li, ul, h1, h2 button 등의 모든 요소는 각각 이벤트 리스너를 등록하고 관리할 수 있는 키-값 데이터 구조의 저장소를 보유하고 있습니다. 따라서 해당 요소를 타겟으로 이벤트 리스너를 등록하면 이를 호출할 때 까지 보관하고 있는 것입니다.
이해를 돕기 위해 의사코드를 한 번 만들어 보았습니다. 예를 들어, click 이벤트를 등록하면, 해당 이벤트 리스너인 anotherClickHandler, handleClick 이 배열 형태의 값으로 저장되는 방식입니다.
// 각 DOM 요소는 이벤트 리스너를 관리하는 객체를 가질 수 있음
element.eventListeners = {
"click": [handleClick, anotherClickHandler],
"mouseover": [handleMouseOver]
}
더 이해하기쉽게 실제 이벤트 리스너 등록 로직과 의사 코드를 하나로 합쳐보았습니다.
// 이벤트 리스너 추가
const button = document.querySelector('button');
button.addEventListener('click', handleClick);
button.addEventListener('click', anotherClickHandler);
// 내부적으로 관리되는 구조
button.eventListeners = {
"click": [handleClick, anotherClickHandler]
}
Object.prototype.hasOwnProperty() | 접근한 객체에 인자로 받은 속성이 존재하는지 체크
nst object1 = {};
object1.property1 = 42;
console.log(object1.hasOwnProperty('property1'));
// Expected output: true
console.log(object1.hasOwnProperty('toString'));
// Expected output: false
console.log(object1.hasOwnProperty('hasOwnProperty'));
// Expected output: false
Object.hasOwn() | 전달 받은 객체에 지정한 속성을 가지고 있으면 true 아니면 false
두 가지 인자를 전달받을 떄, 첫 번째 인자의 객체가 두 번째 인자의 프로퍼티나 메소드를 가지고 있는지 검사하여 있다면 true 아니면 false 를 반환합니다.
const object1 = {
prop: 'exists',
};
console.log(Object.hasOwn(object1, 'prop'));
// Expected output: true
console.log(Object.hasOwn(object1, 'toString'));
// Expected output: false
console.log(Object.hasOwn(object1, 'undeclaredPropertyValue'));
// Expected output: falseObject.is() 는 == 과 같을 까요? === 과 같을까요?
Object.is()는 == 연산자와 같지 않습니다. == 연산자는 같음을 테스트하기 전에 양 쪽(이 같은 형이 아니라면)에 다양한 강제(coercion)를 적용하지만("" == false가 true가 되는 것과 같은 행동을 초래), Object.is는 어느 값도 강제하지 않습니다.
Object.is()는 === 연산자와도 같지 않습니다. Object.is()와 ===의 유일한 차이는 부호 있는 0과 NaN 값들의 처리입니다. === 연산자(및 == 연산자)는 숫자값 -0과 +0을 같게 처리하지만, NaN은 서로 같지 않게 처리합니다.
// Case 1: 평가 결과는 ===을 사용한 것과 동일합니다
Object.is(25, 25); // true
Object.is("foo", "foo"); // true
Object.is("foo", "bar"); // false
Object.is(null, null); // true
Object.is(undefined, undefined); // true
Object.is(window, window); // true
Object.is([], []); // false
const foo = { a: 1 };
const bar = { a: 1 };
const sameFoo = foo;
Object.is(foo, foo); // true
Object.is(foo, bar); // false
Object.is(foo, sameFoo); // true
// Case 2: 부호 있는 0
// ==, === 이었다면 3 가지 모두 true 로 취급합니다.
Object.is(0, -0); // false
Object.is(+0, -0); // false
Object.is(-0, -0); // true
// Case 3: NaN
// ==, === 이었다면 2 가지 모두 false 로 취급합니다.
Object.is(NaN, 0 / 0); // true
Object.is(NaN, Number.NaN); // true
객체 얼리기
자바스크립트에서 객체의 수정과 변경, 삭제 등을 막는 여러 가지 방법이 존재합니다. 이에 대해 한 번 정리해볼까 합니다.
Object.freeze() | 속성 추가, 삭제, 수정을 모두 막음
Object.freeze() 메서드는 객체를 "동결"하여 속성을 추가, 삭제, 수정하는 것을 모두 막습니다. 이 메서드를 사용하면 객체는 변경 불가능한 상태가 됩니다.
let obj = {
prop: 42
};
Object.freeze(obj);
obj.prop = 33; // 무시됨, 변경되지 않음
obj.newProp = 123; // 무시됨, 추가되지 않음
delete obj.prop; // 무시됨, 삭제되지 않음
console.log(obj); // { prop: 42 }
Object.seal() | 속성 추가, 삭제 불가, 수정은 가능
Object.seal() 메서드는 객체를 "밀봉"하여 속성을 추가하거나 삭제하는 것을 막습니다. 그러나 기존 속성의 값은 변경할 수 있습니다.
let obj = {
prop: 42
};
Object.seal(obj);
obj.prop = 33; // 변경 가능
obj.newProp = 123; // 무시됨, 추가되지 않음
delete obj.prop; // 무시됨, 삭제되지 않음
console.log(obj); // { prop: 33 }
Object.preventExtensions() | 속성 추가 불가, 기존 속성 삭제 및 수정은 가능
Object.preventExtensions() 메서드는 객체가 더 이상 확장되지 않도록 합니다. 즉, 새로운 속성을 추가할 수 없지만, 기존 속성의 삭제나 수정은 가능합니다.
let obj = {
prop: 42
};
Object.preventExtensions(obj);
obj.prop = 33; // 변경 가능
obj.newProp = 123; // 무시됨, 추가되지 않음
delete obj.prop; // 삭제 가능
console.log(obj); // {}
속성 정의를 통한 속성 변경 방지
개별 속성에 대해 writable 및 configurable 속성을 설정하여 해당 속성의 변경을 방지할 수 있습니다.
let obj = {};
Object.defineProperty(obj, 'prop', {
value: 42,
writable: false, // 값 변경 불가
configurable: false // 속성 삭제 및 재정의 불가
});
obj.prop = 33; // 무시됨, 변경되지 않음
delete obj.prop; // 무시됨, 삭제되지 않음
console.log(obj); // { prop: 42 }
타입 변환 방법
// 원본 값들
let num = 123;
let str = "456";
let bool = true;
let floatStr = "789.01";
let falsyValue = 0;
// 숫자를 문자열로 변환
let numToStr1 = String(num); // "123"
let numToStr2 = num.toString(); // "123"
let numToStr3 = `${num}`; // "123"
let numToStr4 = num + ""; // "123"
// 문자열을 불린으로 변환
let strToBool1 = Boolean(str); // true
let strToBool2 = !!str; // true
// 숫자를 불린으로 변환
let numToBool1 = Boolean(num); // true
let numToBool2 = !!num; // true
// 문자열을 숫자로 변환
let strToNum1 = Number(str); // 456
let strToNum2 = parseInt(str, 10); // 456
let floatStrToNum = parseFloat(floatStr); // 789.01
let strToNum3 = +str; // 456
// 숫자를 정수로 변환
let floatStrToInt = Math.floor(Number(floatStr)); // 789
// 불린을 숫자로 변환
let boolToNum1 = Number(bool); // 1
let boolToNum2 = +bool; // 1
// 불린을 문자열로 변환
let boolToStr1 = String(bool); // "true"
let boolToStr2 = bool.toString(); // "true"
// Falsy 값을 불린으로 변환
let falsyToBool1 = Boolean(falsyValue); // false
let falsyToBool2 = !!falsyValue; // falseFalsy 와 Truthy
자바스크립트에는 거짓으로 평가되는 값과 참으로 평가되는 값이 있습니다.
if (1) { console.log("1은 참입니다."); }
if ("hello") { console.log("문자열 'hello'는 참입니다."); }
if ({}) { console.log("빈 객체는 참입니다."); }
if ([]) { console.log("빈 배열은 참입니다."); }
if (function() {}) { console.log("함수는 참입니다."); }
if (false) { console.log("이 메시지는 출력되지 않습니다."); }
if (0) { console.log("0은 거짓입니다."); }
if (-0) { console.log("-0은 거짓입니다."); }
if (0n) { console.log("BigInt 0은 거짓입니다."); }
if ("") { console.log("빈 문자열은 거짓입니다."); }
if (null) { console.log("null은 거짓입니다."); }
if (undefined) { console.log("undefined는 거짓입니다."); }
if (NaN) { console.log("NaN은 거짓입니다."); }
이터러블 | 반복 가능한 객체로서 [Symbol.Iterator] 를 필수적으로 가져야 함.
이터러블은 반복 가능한 객체를 의미합니다. 즉, 이터러블 객체는 내부의 요소를 하나씩 순회할 수 있습니다. 이터러블 객체의 예로는 배열, 문자열, Map, Set 등이 있습니다.
이터러블 객체는 Symbol.iterator 메서드를 가지고 있어야 합니다. 이 메서드는 이터레이터를 반환 합니다.
const array = [1, 2, 3];
const iterator = array[Symbol.iterator]();
console.log(typeof iterator); // "object"
이렇듯 이터러블은 배열, 문자열, Map, Set 같은 객체들이 순회 가능하게 해주는 객체로서 이터러블이 정의되어 있지 않은 숫자, 불린과 같은 원시 데이터의 경우에는 순회가 불가능 하다는 사실도 알 수 있습니다.
이터레이터(Iterator) | [Symbol.Iterator] 를 호출하면, 반환하는 next 메서드를 가진 객체
[Symbol.Iterator] 를 호출하면, 반환하는 이터레이터(Iterator)는 next 메서드를 가지고 있는 객체입니다. next 메서드는 호출될 때마다 이터러블 객체의 다음 값을 반환합니다. 반환되는 값은 { value: 값, done: 불리언 } 형태의 객체입니다. 여기서 done이 true가 될 때까지 next 메서드를 계속 호출할 수 있습니다.
const array = [1, 2, 3];
const iterator = array[Symbol.iterator]();
console.log(iterator.next()); // { value: 1, done: false }
console.log(iterator.next()); // { value: 2, done: false }
console.log(iterator.next()); // { value: 3, done: false }
console.log(iterator.next()); // { value: undefined, done: true }
아래는 while 문을 사용하여 done 이 true 가 될 때 까지 반복한 예시 입니다.
const iterable = [10, 20, 30];
const iterator = iterable[Symbol.iterator]();
let result = iterator.next();
while (!result.done) {
console.log(result.value); // 10, 20, 30
result = iterator.next();
}
또한 for...of 를 통해서도 이터러블을 쉽게 순회할 수 있습니다.
const iterable = [10, 20, 30];
for (const value of iterable) {
console.log(value); // 10, 20, 30
}
고차함수 | 다른 함수를 인자로 받거나 함수를 반환하는 함수
고차 함수는 다음 두 가지 중 하나 이상을 수행하는 함수입니다.
함수를 인자로 받는다
고차 함수는 하나 이상의 함수를 인자로 받을 수 있습니다.
function repeat(n, action) {
for (let i = 0; i < n; i++) {
action(i);
}
}
repeat(3, console.log);
// 출력: 0
// 출력: 1
// 출력: 2
함수를 반환한다
고차 함수는 함수를 반환할 수 있습니다.
function createMultiplier(multiplier) {
return function(x) {
return x * multiplier;
};
}
const double = createMultiplier(2);
console.log(double(5)); // 10
일급 객체와 일급 함수
자바스크립트에서 함수는 일급 객체의 모든 특징을 가지고 있습니다(애초에 함수는 객체 입니다). 여기서 정리하는 것은 일급 객체(또는 일급함수)의 특징 별로 어떻게 자바스크립트에서 이것이 적용되는지 정리한 것입니다.
변수에 할당할 수 있다
객체(또는 함수)를 변수에 할당할 수 있습니다.
const a = 42;
const func = function() { return "Hello"; };
함수의 인자로 전달할 수있다
객체(또는 함수)를 함수의 인자로 전달할 수 있습니다.
function greet(callback) {
console.log(callback());
}
greet(function() { return "Hello"; });
함수의 반환값으로 사용할 수 있다
객체(또는 함수)를 함수의 반환값으로 사용할 수 있습니다.
javascript
코드 복사
function getGreeter() {
return function() { return "Hello"; };
}
const greeter = getGreeter();
console.log(greeter()); // "Hello"
자료구조에 저장할 수 있다
객체(또는 함수)를 배열이나 객체와 같은 자료구조에 저장할 수 있습니다.
const functions = [function() { return "Hello"; }, function() { return "World"; }];
console.log(functions[0]()); // "Hello"
Selectionchange 이벤트 | 사용자가 텍스트를 선택하는 순간 발생하는 이벤트
이는 사용자가 텍스트를 선택하는 순간 발생하는 이벤트을 나타냅니다. 이 때 document 객체의 메소드인 getSelection() 을 호출하게 되면 사용자가 선택하여 드래그한 텍스트를 반환하게 됩니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Selection Example</title>
</head>
<body>
<p>이 텍스트를 선택해 보세요.</p>
<script>
document.addEventListener("selectionchange", () => {
const selection = document.getSelection();
console.log("선택된 텍스트:", selection.toString());
});
</script>
</body>
</html>
이대로는 이해가 쉽지 않기 때문에, 실제 체험할 수 있도록 에디터를 가져와 봤습니다. 한 번 실습해보세요.
this바인딩 | 함수가 호출되는 방식에 따라서 this 에 묶이는(바인딩 되는) 객체가 달라지진다.
참고로 this 는 현재 실행 컨텍스트를 가리키는 키워드 입니다. this 바인딩은 실행 컨텍스트에 대한 참조를 this 에 할당하는 과정이라 이해하면 좋을 듯 합니다.
함수선언문(function (){ }) 에서 this | 함수가 호출된 시점에 함수를 감싸고 있는 컨텍스트를 가리킴
일반적으로 다음과 같은 함수선언문에서 this 는 전역 객체인 Window 객체에 바인딩(즉, 전역 실행 컨텍스트의 참조를 담고 있습니다) 됩니다. 이는 현재 func 함수를 감싸고 있는 컨텍스트가 전역 실행 컨텍스트 이기 때문입니다. 다만, 'use strict'를 함수의 유효범위(함수 스코프) 최상단에 입력하시면, this 는 undefined 가 됩니다.
function func(){
console.log(this) // 전역 객체인 Window 가 this 에 묶임
}
func()
외부 함수 내에 내부 함수를 또 다시 선언하여 호출하는 아래와 같은 경우도 동일합니다. 왜냐 하면, 내부함수가 호출되는 시점이 전역 실행 컨텍스트가 있는 위치에서 이루어지기 때문입니다. 예를 들어, func()() 은 func 함수의 내부에서 return 된 innerFunc 함수를 전역 실행 컨텍스트에서 호출하고 있는 것과 같습니다.
function func(){
console.log(this) // 전역 객체인 Window 가 this 에 묶임 1
return function innerFunc(){
console.log(this) // 전역 객체인 Window 가 this 에 묶임 2
}
}
func()()
심지어 객체 리터럴 내에서 생성된 메소드 내에서 함수선언문(내부함수)을 선언한 경우에도 동일하게 WIndow 객체를 가리킵니다. 여기서 객체 내부 메소드에서 호출된 함수가 obj 가 아닌 window 를 가리키는 동작이 발생하는 이유는 해당 내부 함수가 호출되는 시점이 return 을 통해 반환된 독립된 환경 즉, 전역 환경에서 호출되기 때문입니다. 즉, 앞서 살펴본 고차함수의 예시와 동일한 이유입니다.
const obj = {
func:function(){
console.log(this) // 변수 obj 객체를 가리킴
return function inner(){
console.log(this) // window 객체
}
}
}
obj.func()()
객체 리터럴 내에서 함수선언문의 this
앞서 작성한 코드를 다시 가져왔습니다. 객체 내에서는 메소드로 호출되는 함수는 this 가 obj 에 묶이게 됩니다. func() 함수를 호출하는 시점에 함수를 감싸고 있는 컨텍스트는 obj 이므로 해당 obj를 this 가 가리키고 있습니다.
const obj = {
func:function(){
console.log(this) // 변수 obj 객체를 가리킴
}
}
obj.func()
생성자 함수 내에서의 this | 초기에는 빈 객체를 가리키고, 생성자 함수 호출 시 새로 생성된 인스턴스를 가리킴
생성자 함수 내에서의 this는 새로 생성된 인스턴스를 가리키게 됩니다. 이 또한 앞서 객체 리터럴과 유사한 이유로 생성자 함수가 호출되는 시점에 해당 함수를 감싸고 있는 컨텍스트가 새로 생성된 인스턴스가 되기 때문입니다.
예를 들어 다음 코드를 살펴봅시다. 여기서 this 는 { } 빈 객체를 가리키고 있기 때문에, this.name = name 은 사실상 빈 객체에 점 표기법(.) 을 이용하여 값을 추가하는 것과 같게 됩니다.
function Person(name, age) {
// 1. 새로운 빈 객체가 생성됨
// var this = { } --> 사용자에게 안 보임
// 2. this는 새로 생성된 객체를 가리킴
this.name = name;
this.age = age;
// 3. 생성자 함수의 prototype이 새 객체의 [[Prototype]]으로 설정됨
// 4. 함수 코드가 실행됨
// 5. 새 객체가 반환됨 (명시적 반환이 없을 경우)
// return this --> 사용자에게 안 보임
}
const alice = new Person('Alice', 30);
console.log(alice.name); // Alice
console.log(alice.age); // 30
화살표 함수( ( )=>{ }) 에서의 this | 상위 렉시컬 스코프의 this 를 상속 받음
화살표 함수는 function(){ } 과는 다르게 this 를 상위 렉시컬 스코프로 부터 상속 받아서 사용합니다. 즉, 화살표 함수 자체적으로는 this 를 가지지 않습니다.
예를 들어, 다음 함수가 있다고 가정해봅시다. 여기서 serInterval 내의 콜백함수는 화살표 함수 입니다.
function Person() {
this.age = 0;
setInterval(() => {
this.age++; // 이 경우의 `this`는 `Person` 객체를 가리킵니다.
console.log(this.age);
}, 1000);
}
const p = new Person();
화살표 함수의 경우 앞서 언급했듯이 상위 렉시컬 스코프의 this 를 상속 받기 때문에, 해당 콜백함수의 상위 스코프인 Person 생성자 함수 내에서 { } 빈객체를 가리키는 this 를 상속 받습니다. 따라서 this.age 는 사실상 this = {age :0} 로 활당된 this 객체에 접근하는 것과 같습니다.
스코프란?
스코프는 변수와 매개변수의 접근성과 생존 기간을 정의 합니다. 즉, 코드의 어느 부분에서 변수에 접근할 수 있고, 해당 변수의 값이 얼마나 오랫동안 유지되는지를 결정합니다.
렉시컬스코프 | 함수가 선언(정의)된 위치에 따라 해당 함수의 스코프와 상위 스코프를 결정하는 방식
렉시컬 스코프(lexical scope)는 변수 및 함수의 유효 범위를 결정하는 방식 중 하나입니다. 이는 코드를 작성할 때 변수 및 함수가 어디에서 참조될 수 있는지를 결정합니다.
렉시컬 스코프는 함수가 어디에 호출되는지가 아니라, 함수가 어디서 정의되는지에 따라 스코프가 결정되는 개념임을 명심합시다.
렉시컬 스코프의 원리는 다음과 같습니다
정적 스코프 (Static Scope)
렉시컬 스코프는 함수가 선언된 위치에 따라 해당 함수의 스코프가 결정됩니다. 이를 정적 스코프라고도 합니다. 함수가 선언된 위치에서부터 함수가 중첩된 범위까지 스코프가 유지됩니다. 이를 렉시컬 스코프 체인이라 부릅니다.
함수의 중첩 (Function Nesting)
함수가 다른 함수 내에 중첩되어 있는 경우, 내부 함수는 외부 함수의 변수에 접근할 수 있습니다. 이때 내부 함수의 스코프는 외부 함수의 스코프와 중첩된 관계를 가지며, 이를 렉시컬 스코프 체인(lexical scope chain)이라고 합니다.
렉시컬 스코프는 코드를 읽을 때 함수가 어디에 정의되었는지를 보고 해당 함수의 스코프를 결정합니다. 이것은 코드의 구조를 보고 변수나 함수의 스코프를 추론할 수 있다는 장점을 제공합니다. 따라서 코드의 동적인 실행 순서에 의해 스코프가 변경되지 않습니다.
간단한 JavaScript 예시로 렉시컬 스코프를 설명하겠습니다:
function outerFunction() {
let outerVariable = 'Outer';
function innerFunction() {
console.log(outerVariable); // 내부 함수에서 외부 변수에 접근
}
innerFunction();
}
outerFunction(); // "Outer"를 출력
이 예시에서 innerFunction은 외부 함수 outerFunction 내에서 정의되었으며, 내부에서 outerVariable에 접근합니다. 렉시컬 스코프의 원리에 따라 innerFunction은 outerVariable에 접근할 수 있습니다.
클로저 | 함수가 속한 렉시컬스코프를 기억하여, 함수가 렉시컬 스코프 밖에서 실행될 때도 그 스코프에 접근할 수 있게 하는 기능
클로저(Closure)는 프로그래밍에서 중요한 개념 중 하나로, 함수와 그 함수가 만들어진 환경(lexical environment) 사이의 관계를 나타냅니다. 클로저는 함수가 다른 함수 내부에서 정의되고 반환되는 경우에 자주 발생합니다.
클로저는 세 가지 주요 구성 요소로 이루어집니다
함수 (Function)
클로저를 만드는 주체입니다. 함수 내부에서 다른 함수를 정의하고 반환할 수 있습니다.
외부 함수의 변수 (Variables in the Outer Function)
클로저에 의해 포착되는 외부 함수 내의 변수입니다. 내부 함수가 외부 함수의 변수를 사용하거나 변경할 수 있습니다.
함수와 외부 변수 간의 관계 (Relationship between the Function and Outer Variables)
내부 함수가 반환되고 외부 변수를 포착하여 그 값을 유지하는 메커니즘입니다. 이 관계는 클로저의 핵심이며, 내부 함수는 외부 변수에 대한 참조를 유지하고, 해당 변수는 함수가 반환되더라도 계속해서 사용될 수 있습니다.
클로저는 다양한 상황에서 유용하게 활용될 수 있습니다. 예를 들어, 클로저를 사용하여 함수 팩토리를 구현할 수 있으며, 이를 통해 매개변수화된 함수를 생성할 수 있습니다. 또한 비동기 작업에서 클로저를 사용하여 상태를 유지하고 콜백 함수에 전달할 수 있습니다.
간단한 JavaScript 예시로 클로저를 살펴보겠습니다
function outerFunction() {
let outerVariable = 'I am outer';
function innerFunction() {
console.log(outerVariable); // 외부 변수에 접근
}
return innerFunction; // 내부 함수를 반환
}
const closure = outerFunction(); // 내부 함수가 반환되고, 외부 변수가 포착됨
closure(); // "I am outer"를 출력
이 예시에서 innerFunction은 외부 함수 outerFunction 내에서 정의되었고, outerVariable을 참조합니다. 그러나 outerFunction이 실행을 마쳤더라도 innerFunction은 여전히 outerVariable에 접근할 수 있습니다. 이것이 바로 클로저의 동작 원리입니다.
브라우저 렌더링 원리
문서 파싱(Parsing)
브라우저는 웹페이지의 HTML 및 CSS를 읽어들입니다. 이 과정에서 HTML 문서를 파싱하여 DOM(Document Object Model) 트리를 만들고, CSS를 파싱하여 CSS 객체 모델(CSS Object Model)을 생성합니다.
렌더 트리 구축(Render Tree Construction) | DOM + CSSOM 트리를 결합한 화면에 표시될 요소의 구조 생성
DOM 트리와 CSS 객체 모델을 결합하여 렌더 트리를 구축합니다. 렌더 트리는 화면에 표시될 요소들의 구조를 나타내며, 각 요소의 스타일 정보도 포함합니다.
레이아웃(Layout) | 렌더트리 기반의 각 요소의 위치와 크기를 계산 후 브라우저 내 정확한 배치에 사용
렌더 트리를 기반으로 각 요소의 위치와 크기를 계산하여 브라우저 창 내에서의 정확한 배치를 결정합니다. 이 단계에서는 요소의 크기, 위치, 여백 등의 정보를 결정합니다.
페인팅(Painting) | 레이아웃 과정을 통해 결정된 위치에 각 노드에 대한 실제 픽셀을 그리는 작업 수행
레이아웃 단계에서 계산된 위치와 크기에 따라 렌더 트리의 각 노드에 대해 실제로 화면에 픽셀을 그립니다. 이 단계에서는 픽셀 단위로 요소의 내용, 색상, 텍스트 등을 브라우저 화면에 그립니다.
리액트 관련 개념
컴포넌트 기반 아키텍처
컴포넌트 기반 아키텍처는 애플리케이션을 독립적이고 재사용 가능한 컴포넌트 단위로 나누어 구성하는 소프트웨어 설게 방법론 중 하나 입니다.
컴포넌트 기반 아키텍처의 특징은 다음 4가지 로 정리할 수 있습니다.
-독립성: 컴포넌트는 독립적으로 설계되어, 다른 컴포넌트에 영향을 주지 않고, 독립적으로 동작하며 유지보수가 향상됩니다.
- 재사용성: 동일한 컴포넌트를 애플리케이션 내 여러 곳에서 재사용 가능 하므로 개발 효율성이 증가합니다.
- 모듈화: 코드를 논리적인 단위로 분리하여 관리하므로 각 컴포넌트는 특정 기능이나 UI의 한 부분을 담당하게 됩니다. 이 때 변경이 필요한 경우는 해당 컴포넌트만 수정하면 됩니다.
- 캡슐화: 컴포넌트는 내부 로직과 데이터를 캡슐화하여 외부에서는 오직 필요한 인터페이스(props)를 통해서만 접근할 수 있습니다.
프레젠테이셔널 컴포넌트와 컨테이너 컴포넌트
프레젠테이셔널 컴포넌트
UI 를 표시하는 역할만 수행하는 컴포넌트로 데이터를 props 으로 전달 받아 렌더링하는데 중점을 두는 컴포넌트 입니다. 데이터와 상태관리에 일절 관여하지 않습니다.
function UserProfile({ user }) {
return <div>{user.name}</div>;
}
컨테이너 컴포넌트
상태를 관리하고, 데이터 페칭을 수행하여 프레젠테이셔널 컴포넌트에 데이터를 전달하는 역할에 중점을 둡니다.
import { useState, useEffect } from 'react';
import UserProfile from './UserProfile';
function UserProfileContainer() {
const [user, setUser] = useState(null);
useEffect(() => {
fetch('/api/user')
.then(response => response.json())
.then(data => setUser(data));
}, []);
return user ? <UserProfile user={user} /> : <div>Loading...</div>;
}
고차 컴포넌트(Higher-Order Components, HOCs)
다른 컴포넌트를 인자로 받아 새로운 컴포넌트를 반환하는 함수 입니다. 재사용 가능한 컴포넌트 로직을 구현할 때 유용합니다.
function withLoading(Component) {
return function WithLoadingComponent({ isLoading, ...props }) {
if (isLoading) {
return <div>Loading...</div>;
}
return <Component {...props} />;
};
}
UI 조합을 통합 컴포지션
Button , Card 등의 UI 컴포넌트를 조합하여 새로운 컴포넌트를 만들어 내는 컴포지션 패턴입니다.
function Button({ children, onClick }) {
return <button onClick={onClick}>{children}</button>;
}
function Card({ title, children }) {
return (
<div className="card">
<h1>{title}</h1>
<div className="card-content">
{children}
</div>
</div>
);
}
function App() {
return (
<Card title="My Card">
<p>This is some card content.</p>
<Button onClick={() => alert('Button clicked!')}>Click Me</Button>
</Card>
);
}
컴포넌트 컴포지션
여러 컴포넌트를 부모-자식 관계로 구성하여 기능을 결합하는 방식입니다. 자식 컴포넌트는 부모 컴포넌트의 프로퍼티나 상태를 기반으로 렌더링 됩니다.
function Layout({ header, content, footer }) {
return (
<div>
<header>{header}</header>
<main>{content}</main>
<footer>{footer}</footer>
</div>
);
}
function App() {
return (
<Layout
header={<h1>Header Section</h1>}
content={<p>Main Content</p>}
footer={<p>Footer Section</p>}
/>
);
}
슬릇 컴포지션
자식 컴포넌트에 특정 콘텐츠를 삽입 할 수 있는 방법입니다. 슬릇은 자식 컴포넌트에서 부모 컴포넌트가 제공한 콘텐츠를 렌더링 합니다.
function Modal({ children }) {
return (
<div className="modal">
<div className="modal-content">
{children}
</div>
</div>
);
}
function App() {
return (
<Modal>
<h2>Modal Title</h2>
<p>Some modal content goes here.</p>
</Modal>
);
}
왜 렌더링 중에는 변수를 변경 하면 안 되는거죠?
이 부분은 크게 아래 세 가지 이유로 설명이 가능할 것 같습니다.
- 무한 루프와 성능 문제: 변수를 변경하면 해당 변경이 다시 렌더링을 유발할 수 있습니다. 이로 인해 렌더링이 반복적으로 발생하거나, 무한 루프에 빠질 수 있습니다.
- 예측 불가능한 동작: 리액트는 상태(state) 또는 props의 변경을 감지하고 UI를 업데이트하는데, 렌더링 중에 변수를 변경하면 이러한 감지 과정을 방해할 수 있습니다.
- 단일 소스 오류: 코드가 복잡해지고 유지보수가 어려워질 수 있습니다. 특히 대규모 애플리케이션에서는 예측 가능한 상태 관리가 필요합니다.
결론적으로 예측 가능한 상태를 통해 UI 업데이트를 수행하는 리액트의 예측 가능한 상태관리 원칙에 위배되는 행동이라는 것입니다. 즉, 함수 컴포넌트 외부에 let, var 변수를 선언하고, 이를 컴포넌트 내부에서 수정하게 되면, 리액트는 이를 변경된 것으로 파악하고 리렌더링을 유발하게 됩니다. 문제는 컴포넌트 자체의 라이프사이클과 외부에 있는 변수의 라이프사이클이 다르기 때문에 예기치 못한 문제가 발생할 수 있다는 것이죠.
리액트에서 배열에 Key 속성을 변하지 않는 고유한 식별자로 지정하는 것을 권장하는 이유
리액트에서 key prop의 순서가 중요한 이유는 주로 성능 최적화와 안정적인 상태 관리를 위해서입니다. 리액트는 각 컴포넌트의 업데이트를 효율적으로 처리하기 위해 key prop을 사용하여 리스트 아이템을 식별합니다. 이는 특히 동적인 리스트를 렌더링할 때 중요합니다. 다음은 key prop의 순서가 중요한 이유를 자세히 설명합니다.
효율적인 재조정 (Reconciliation)
리액트는 가상 DOM(Virtual DOM)을 사용하여 실제 DOM과의 차이를 비교하고 최소한의 변경만 실제 DOM에 적용합니다. 이를 효율적으로 수행하기 위해 key를 사용하여 각 리스트 아이템을 고유하게 식별합니다. key는 리스트의 각 요소를 구분하고, 요소의 순서와 일치하도록 유지됩니다.
변경 감지: key를 사용하여 리액트는 요소가 추가되었는지, 제거되었는지, 아니면 순서가 바뀌었는지를 정확하게 감지할 수 있습니다. 만약 key가 없다면, 리액트는 매 렌더링마다 모든 요소를 다시 그리게 되어 비효율적입니다.
최소한의 업데이트: key를 통해 리액트는 변경된 요소만 업데이트합니다. 이는 성능을 최적화하고, 불필요한 DOM 조작을 최소화합니다.
안정적인 상태 유지
컴포넌트는 상태(state)를 가질 수 있으며, 리스트 아이템의 상태는 key에 의해 추적됩니다. key가 변경되면 리액트는 해당 컴포넌트를 새롭게 생성된 것으로 간주합니다. 이는 상태가 초기화되는 결과를 초래합니다.
일관된 상태: key가 일정하면, 리액트는 각 리스트 아이템의 상태를 올바르게 유지합니다. key가 일관되지 않으면 상태가 예상치 못하게 초기화될 수 있습니다.
정확한 업데이트: 동일한 key를 가진 요소는 상태와 props가 그대로 유지되며, 위치만 변경됩니다. 이는 리스트 아이템의 상태를 안정적으로 관리할 수 있게 합니다.
안정된 상태를 유지하기 위한 key는 다음과 같이 리스트 내에서 각 아이템을 고유하게 식별할 수 있는 값이어야 합니다. 일반적으로 데이터베이스의 고유 ID를 사용합니다.
// 올바른 사용법: key prop이 있는 경우
function ListWithKey({ items }) {
return (
<ul>
{items.map((item) => (
<li key={item.id}>{item.text}</li>
))}
</ul>
);
}
리액트의 JSX 요소가 DOM 트리의 요소로 변환하는 과정
리액트의 JSX 요소가 실제 DOM 트리의 요소로 변환되는 과정은 몇 가지 주요 단계로 이루어집니다. 이 과정을 이해하면 리액트가 어떻게 효율적으로 UI를 업데이트하는지 알 수 있습니다.
JSX 변환
JSX는 자바스크립트의 확장 문법으로, HTML과 유사하게 작성할 수 있습니다. 그러나 브라우저가 JSX를 직접 이해할 수 없기 때문에, 이를 자바스크립트로 변환하는 과정이 필요합니다. 바벨(Babel)과 같은 트랜스파일러가 이 역할을 수행합니다.
예를 들어, 다음과 같은 JSX 코드가 있다고 가정해봅시다:
const element = <h1 className="greeting">Hello, world!</h1>;
이 코드는 바벨에 의해 다음과 같은 자바스크립트 코드로 변환됩니다:
const element = React.createElement(
'h1',
{ className: 'greeting' },
'Hello, world!'
);Virtual DOM 생성
리액트는 변환된 자바스크립트 코드를 사용하여 가상 DOM(Virtual DOM)을 생성합니다. 가상 DOM은 실제 DOM을 추상화한 자바스크립트 객체 트리로, UI의 상태를 메모리에 저장합니다.
위의 React.createElement 호출은 다음과 같은 가상 DOM 요소를 생성합니다.
const element = {
type: 'h1',
props: {
className: 'greeting',
children: 'Hello, world!'
}
};
실제 DOM에 렌더링
가상 DOM이 생성되면, 리액트는 이를 실제 DOM에 렌더링합니다. 이 과정은 다음 단계를 포함합니다:
Initial Rendering: 초기 렌더링 시, 리액트는 가상 DOM 트리를 순회하며 실제 DOM 요소를 생성하고, 이를 브라우저의 DOM 트리에 추가합니다.
ReactDOM.render(element, document.getElementById('root'));
ReactDOM.render는 가상 DOM 트리를 실제 DOM 트리로 변환하고, 지정된 DOM 노드에 추가합니다. 이 과정에서 각 가상 DOM 요소는 실제 DOM 요소로 변환되어 브라우저에 나타납니다.
업데이트 과정
리액트의 주요 장점 중 하나는 효율적인 업데이트입니다. 컴포넌트의 상태나 props가 변경되면, 리액트는 새로운 가상 DOM 트리를 생성하고, 이전 가상 DOM 트리와 비교하여 변경된 부분만 실제 DOM에 반영합니다. 이 과정을 리콘실리에이션(reconciliation; 조정) 이라고 합니다.
| 참고로 회계에서 조정은 두 레코드 세트가 일치하는지 확인하는 프로세스라고 합니다. 이 정의를 리액트에 가져와서 생각해보면, 새 가상돔과 이전 가상돔 간의 구조가 일치하는지 확인하는 프로세스라고 이해할 수 있겠습니다. |
- 새 가상 DOM 생성: 상태나 props의 변경으로 인해 새로운 가상 DOM 트리가 생성됩니다.
- 변경 사항 비교: 리액트는 새로운 가상 DOM 트리와 이전 가상 DOM 트리를 비교(diffing)하여 변경된 부분을 찾습니다.
- 실제 DOM 업데이트: 변경된 부분만 실제 DOM에 반영하여, 최소한의 연산으로 UI를 업데이트합니다.
예를 들어, 컴포넌트의 상태가 변경되어 className이 변경된다고 가정합시다.
this.setState({ className: 'farewell' });
리액트는 새로운 가상 DOM 트리를 생성하고, 이전 트리와 비교하여 className 속성이 변경되었음을 감지합니다. 그런 다음, 해당 DOM 노드의 className 속성만 업데이트합니다.
컴포넌트 언마운트 및 정리
컴포넌트가 더 이상 필요하지 않게 되면, 리액트는 이를 DOM 트리에서 제거하고, 관련된 이벤트 핸들러나 메모리 자원을 정리합니다. 이는 componentWillUnmount 생명주기 메서드 또는 useEffect 훅의 클린업 함수를 통해 수행됩니다.
요약
- JSX 변환: 바벨이 JSX를 React.createElement 호출로 변환.
- Virtual DOM 생성: 변환된 자바스크립트 코드를 기반으로 가상 DOM 트리 생성.
- 초기 렌더링: 가상 DOM 트리를 실제 DOM으로 변환하여 브라우저에 렌더링.
- 업데이트 과정: 상태나 props 변경 시 새로운 가상 DOM 생성, 이전 트리와 비교하여 실제 DOM 업데이트.
- 언마운트 및 정리: 필요 없는 컴포넌트를 DOM에서 제거하고 자원 정리.
리액트에서 변이가 허용되는 경우와 피해야 하는 경우
이 경우에는 로컬에서 변이가 이루어지기 때문에, 괜찮습니다. 즉, FriendList 컴포넌트가 살아있는 동안(렌더링 동안)에만 유효하기 때문에, 렌더링 마다 새롭게 생성되므로, 컴포넌트는 부수효과에 영향을 받지 않고, 동일한 출력을 반환하게 됩니다.
function FriendList({ friends }) {
const items = []; // ✅ Good: locally created
for (let i = 0; i < friends.length; i++) {
const friend = friends[i];
items.push(
<Friend key={friend.id} friend={friend} />
); // ✅ Good: local mutation is okay
}
return <section>{items}</section>;
}
반면, 컴포넌트의 외부에 선언된 변수는 컴포넌트가 렌더링 되더라도 메모리에 남아 있기 때문에, 컴포넌트는 렌더링 된 이후에도 해당 변수를 참조하게 되고, 이는 결국 중복된 데이터가 쌓이게 되며 메모리 누수 문제로도 이어질 수 있습니다.
const items = []; // 🔴 Bad: created outside of the component
function FriendList({ friends }) {
for (let i = 0; i < friends.length; i++) {
const friend = friends[i];
items.push(
<Friend key={friend.id} friend={friend} />
); // 🔴 Bad: mutates a value created outside of render
}
return <section>{items}</section>;
}
만일 이렇게 작성하는 경우 문제점을 요약해면 다음과 같습니다(이 부분은 GPT4o 의 도움을 받았습니다).
| 상태 관리 문제 |
| items 배열은 컴포넌트 외부에 정의되어 있어, 컴포넌트의 상태나 라이프사이클과 연관되지 않습니다. 이는 리액트의 상태 관리 원칙을 위반하며, 컴포넌트의 상태가 예측 불가능하게 됩니다. 여러 번 렌더링될 때마다 items 배열이 계속 누적되기 때문에, 메모리 누수 및 불필요한 리렌더링 문제를 일으킬 수 있습니다. |
| 불변성 원칙 위반 |
| 리액트에서는 상태나 props를 직접 변이하지 않는 것이 원칙입니다. items 배열을 컴포넌트 외부에 정의하고 이를 변이시키는 것은 이 원칙을 위반합니다. |
| 리렌더링 문제 |
| 리액트 컴포넌트는 상태나 props가 변경될 때 자동으로 리렌더링됩니다. 그러나 items 배열이 외부에서 관리되면, 리액트는 이 배열의 변경을 감지하지 못하고 필요할 때 제대로 리렌더링되지 않을 수 있습니다. 또한, items 배열이 한 번만 초기화되고 이후 계속해서 누적되기 때문에, 컴포넌트가 리렌더링될 때마다 동일한 항목이 중복되어 렌더링됩니다. |
Fragment
JSX 가 여러 개인 경우 이를 그룹화 활 때 사용되는 리액트의 특수한 타입의 컴포넌트 입니다. 보통 표기는 <Fragment/> 혹은 </> 형태로 작성하며, 이렇게 감싸진 컴포넌트는 실제 DOM 에 그려질 때는 DOM 트리에 반영되지 않습니다. 즉, 보이지는 않지만 JSX 가 두 개인 것을 하나의 자바스크립트 객체로 묶어주는 역할을 해주기 때문에, 불가피하게 두 개의 JSX 태그는 처리해야 하는 경우에 해당 컴포넌트를 감싸주는 방식으로 사용할 수 있습니다.
JSX 태그를 하나로 감싸줘야 하는 이유
JSX 는 언뜻보면 일반적인 HTML과 별차이가 없기 때문에, 간과할 수 있지만, 리액트의 컴포넌트는 함수입니다. 함수로서 반환(return) 되는 JSX 태그는 리액트 createElement 를 통해 하나의 자바스크립트 객체로 변환되는데, JSX 태그가 여러 개 병렬적으로 나열된 경우에는 이를 하나의 자바스크립트 객체로 반환할 수 없기 때문입니다. 즉, 내부 연산의 순서에 문제를 일으키게 됩니다.
코드분할 | 앱의 번들을 더 작은 청크(chunk)로 분할하여 필요할 때 (lazy) 로드 할 수 있는 기술
리액트는 코드분할을 다음과 같은 Lazy 함수와 Suspense 컴포넌트를 사용하여 구현할 수 있습니다.
const MyComponent = React.lazy(() => import('./MyComponent'));
function App() {
return (
<Suspense fallback={<div>Loading...</div>}>
<MyComponent />
</Suspense>
);
}
State | 컴포넌트 내부에서 관리되는 데이터로서 컴포넌트 렌더링 유무에 관여하는 값
리액트에서의 "상태"는 컴포넌트 내부에서 관리되는 데이터를 의미합니다. 여기서 데이터는 컴포넌트의 렌더링 결과물에 영향을 주는 값으로, 컴포넌트가 변경될 때마다 변하게 됩니다.
리액트의 함수 컴포넌트에서는 useState 훅을 사용하여 상태를 관리합니다. 상태는 사용자 인터랙션, 외부 데이터 로딩, 시간에 따른 변화 등 여러 요인에 따라 변경될 수 있습니다.
상태는 컴포넌트의 렌더링 결과를 결정하는 주요 요소 중 하나이며, 상태가 변경될 때마다 리액트는 해당 컴포넌트를 다시 렌더링하여 업데이트된 상태를 반영합니다. 이를 통해 동적인 UI를 만들고 사용자와의 상호작용을 제어할 수 있습니다.
리액트에서 리렌더링을 유발하는 트리거
상태(State) 변경
useState 훅을 사용하여 관리되는 상태(state)가 변경될 때마다 함수 컴포넌트가 다시 호출되어 리렌더링됩니다.
const [count, setCount] = useState(0);
// 상태 변경 후
setCount(count + 1); // 리렌더링 유발
속성(Props) 변경
부모 컴포넌트로부터 전달받은 속성(props)이 변경될 때마다 함수 컴포넌트가 다시 호출되어 리렌더링됩니다.
function ParentComponent() {
const [value, setValue] = useState(0);
return <ChildComponent prop={value} />;
}
// 부모 컴포넌트에서 속성 변경 후
setValue(newValue); // ChildComponent 재렌더링 유발
useContext 훅을 통한 전역 상태 변경
useContext 훅을 사용하여 전역 상태가 변경될 때마다 함수 컴포넌트가 다시 호출되어 리렌더링됩니다.
const MyContext = React.createContext();
function MyComponent() {
const value = useContext(MyContext);
// 전역 상태 변경 후
// MyComponent 재렌더링 유발
}
useEffect 훅의 의존성 배열
useEffect 훅에서 관리하는 상태나 props가 변경될 때마다 함수 컴포넌트가 다시 호출되어 리렌더링됩니다.
useEffect(() => {
// 이펙트 코드
}, [dependency]); // dependency가 변경될 때마다 재렌더링 유발리액트에서 리렌더링의 동작 원리
함수 컴포넌트에서의 리렌더링은 상태(state)나 속성(props)이 변경될 때 발생합니다. 이러한 변경이 발생하면 리액트는 해당 함수 컴포넌트를 다시 호출하여 반환된 JSX를 기반으로 화면을 업데이트합니다.
리렌더링의 동작 방식은 다음과 같습니다
상태(State) 또는 속성(Props)의 변경
함수 컴포넌트가 소유한 상태(state)나 부모 컴포넌트로부터 전달받은 속성(props)이 변경될 때 리렌더링이 발생합니다.
함수 컴포넌트 재호출
리액트는 해당 함수 컴포넌트를 재호출하여 반환된 JSX를 생성합니다.
가상 DOM 비교
이전 가상 DOM과 새로운 가상 DOM을 비교하여 변경된 부분을 찾습니다.
변경된 부분의 실제 DOM 업데이트
변경된 부분만을 실제 DOM에 반영하여 화면을 업데이트합니다. 이때, 실제 DOM을 직접 조작하는 것이 아니라 가상 DOM을 이용하여 최소한의 변경만을 적용합니다. 이 때 변경된 부분만을 효율적으로 찾는 알고리즘은 디핑(diffing) 이라 부르며, 변경된 사항들을 한 번에 업데이트 하는 기법을 배치 업데이트라고 부릅니다.
리액트에서 제어 컴포넌트(Controlled Component) | React의 상태(state)를 사용하여 폼 요소의 값을 제어
제어 컴포넌트는 React의 상태(state)를 사용하여 폼 요소의 값을 제어합니다. 폼 요소의 값이 React의 상태로 저장되며, 이 상태가 변경될 때마다 리렌더링됩니다. 따라서, 사용자 입력에 대한 변화를 실시간으로 감지하고 반응할 수 있습니다.
주로 input의 value prop을 사용하여 React의 상태와 폼 요소를 연결합니다.
function ControlledComponent() {
const [value, setValue] = useState('');
const handleChange = (e) => {
setValue(e.target.value);
};
return (
<input type="text" value={value} onChange={handleChange} />
);
}
리액트에서 비제어 컴포넌트(Uncontrolled Component) | React의 상태(state)를 사용하지 않고, 폼 요소의 DOM을 직접 조작하여 값을 관리
비제어 컴포넌트는 React의 상태(state)를 사용하지 않고, 폼 요소의 DOM을 직접 조작하여 값을 관리합니다. 컴포넌트가 렌더링된 후에는 React는 해당 요소를 더 이상 제어하지 않습니다. 주로 ref를 사용하여 폼 요소의 DOM에 직접 접근합니다.
function UncontrolledComponent() {
const inputRef = useRef(null);
const handleClick = () => {
console.log(inputRef.current.value);
};
return (
<div>
<input type="text" ref={inputRef} />
<button onClick={handleClick}>Submit</button>
</div>
);
}
제어 컴포넌트는 React의 강력한 상태 관리 기능을 활용하여 폼 요소를 다루는 데 유용하며, 비제어 컴포넌트는 외부 라이브러리나 기존의 DOM 조작과의 통합 등 특정 상황에서 유용할 수 있습니다.
리액트에서 상태 끌어 올리기 | 상태를 끌어올려서 상위 컴포넌트에서 하위 컴포넌트로 데이터를 전달하고 setState 를 통해 부모 상태를 관리하는 것
리액트에서 상태(state) 끌어올리기란 여러 하위 컴포넌트에서 공유되는 상태를 부모 컴포넌트로 끌어올리는 것을 말합니다. 이를 통해 상위 컴포넌트에서 하위 컴포넌트로 상태를 전달하고 변경할 수 있습니다. 주로 상위 컴포넌트에서 상태를 관리하고 하위 컴포넌트에서는 이 상태를 props로 전달받아 사용합니다. 이러한 방식은 컴포넌트 간의 데이터 흐름을 명확하게 만들어 주고, 상태 관리를 더욱 효율적으로 할 수 있습니다.
상태를 끌어올리는 예시를 살펴보겠습니다.
// ParentComponent.js
import React, { useState } from 'react';
import ChildComponent from './ChildComponent';
function ParentComponent() {
const [count, setCount] = useState(0);
const incrementCount = () => {
setCount(count + 1);
};
return (
<div>
<h2>Parent Component</h2>
<p>Count: {count}</p>
<ChildComponent count={count} onIncrement={incrementCount} />
</div>
);
}
export default ParentComponent;
// ChildComponent.js
import React from 'react';
function ChildComponent({ count, onIncrement }) {
return (
<div>
<h3>Child Component</h3>
<p>Count from Parent: {count}</p>
<button onClick={onIncrement}>Increment Count</button>
</div>
);
}
export default ChildComponent;
위 예시에서 ParentComponent는 count라는 상태를 가지고 있고, incrementCount 함수를 통해 이 상태를 변경할 수 있습니다. ChildComponent는 count 상태를 props로 받아와서 사용하고, onIncrement 함수를 호출하여 상위 컴포넌트의 상태를 변경할 수 있습니다. 이처럼 상태를 끌어올려서 상위 컴포넌트에서 하위 컴포넌트로 데이터를 전달하고 상태를 관리하는 것이 상태 끌어올리기입니다.
리액트 컴포넌트는 언제나 멱등성이 중요함
리액트에서 컴포넌트는 입력(state, prop, content) 와 관련해서 항상 동일한 출력을 반환해야 하는데, 이를 멱등성이라고 합니다. 다만, 이는 멱등성을 위배하는 함수를 사용하지 말아야 한다는 것이 아니라, 리액트가 렌더링 되는 동안에는 그러한 동작이 실행되어서는 안 된다는 점입니다.
즉, new Date 와 같이 매번 결과가 바뀌는 비멱등성을 가지는 함수를 매번 호출 해야 하는 경우, useEffect 훅을 사용하여 컴포넌트의 렌더링 시간과 해당 함수가 실행되는 시점을 동기화하여 처리하는 것이 좋습니다.
Components and Hooks must be pure – React
The library for web and native user interfaces
react-ko.dev
window 객체의 devicePixelRatio | 사용자의 디스플레이 픽셀 밀도를 나타내는 속성
window.devicePixelRatio는 웹 브라우저에서 사용자의 디스플레이의 픽셀 밀도를 나타내는 JavaScript 속성입니다. 이 속성은 현재 사용 중인 디스플레이의 실제 픽셀 수와 CSS 픽셀 수 사이의 비율을 나타냅니다.
예를 들어, Retina 디스플레이를 가진 장치는 일반 디스플레이보다 더 높은 픽셀 밀도를 가질 것입니다. 이 경우 window.devicePixelRatio 값은 2를 반환할 것입니다. 이는 Retina 디스플레이에서 CSS 1에 해당하는 픽셀이 실제로는 2픽셀에 매핑될 수 있음을 의미합니다.
음.. 이대로는 설명이 빈약한 것으니까 조금 풀어서 설명해보겠습니다
Retina 디스플레이는 일반적으로 고해상도 디스플레이를 가리킵니다. 또한, 픽셀 밀도가 높아서 더 많은 픽셀을 한정된 영역에 채워 넣어 선명한 화면을 제공합니다.
실제로, Retina 디스플레이에서는 CSS 픽셀과 실제 픽셀 사이의 매핑이 복잡하게 이루어지는데, 하나의 CSS 픽셀은 여러 개의 실제 픽셀로 매핑될 수 있습니다. 이러한 특징은 더 높은 해상도(고화질)를 제공하면서도 동일한 크기의 요소를 더 선명하게 보이게 할 수 있습니다.
즉, Retina 디스플레이에서는 1개의 CSS 픽셀이 2개 또는 그 이상의 실제 픽셀로 매핑될 수 있습니다(이것이 동일한 사이즈의 이미지임에도 고화질 디스플레이 환경에서는 더 선명하게 보일 수 있는 이유입니다).
이를 통해 웹 개발자는 디바이스의 픽셀 밀도에 따라 레티나 또는 고해상도 디스플레이에 적합한 이미지를 선택하거나 다른 디바이스에 맞게 레이아웃을 조정할 수 있습니다.
리액트와 클로저
한 번쯤 상기해보는, 클로저의 개념 & 일반적인 리액트 사례
들어가기 전 | 리액트와 클로저의 관계?어찌보면 당연한 것일지도 모릅니다. 그런데, 평소에 신경쓰지 않고 있다가 클로저라는 개념에 대해서 잠시 상기해보는 시간을 가지게 되었는데, 리액트
duklook.tistory.com
리액트 쿼리에 대한 개념
리액트 쿼리는 서버에서 데이터를 가져오고, 캐싱하고, 동기화하고, 서버 상태를 관리하는 데 사용되는 라이브러리입니다. 이를 통해 React 애플리케이션에서 비동기 데이터 패칭을 간편하게 처리할 수 있습니다.
Query | 서버에서 데이터를 가져오고 캐싱하는 것
Query는 서버에서 데이터를 가져오고 캐싱하는 것을 의미합니다. useQuery 훅을 사용하여 쿼리를 수행하고, 로딩 상태, 에러 상태, 데이터 등을 관리할 수 있습니다.
import { useQuery } from 'react-query';
const { data, error, isPending, isFetching } = useQuery(queryKey:['todos'], queryFunc: fetchTodos);
Mutation | 서버에 데이터 생성, 수정, 삭제 작업을 수행하도록 함
Mutation은 서버에 데이터를 생성, 수정, 삭제하는 작업을 수행합니다. useMutation 훅을 사용하여 이러한 작업을 수행하고, 성공 및 실패 상태를 관리할 수 있습니다.
Query Key | Query 의 고유 식별를 위해 사용하는 프로퍼티로 문자열이나 배열을 받음
Query Key는 쿼리를 고유하게 식별하는 데 사용되는 문자열이나 배열입니다. 이를 통해 리액트 쿼리는 어떤 데이터가 캐시에 저장되어 있는지 구분할 수 있습니다. 여기서 고유 식별키로 등록된 요소 중 하나가 변경되면, 쿼리 함수는 서버로 부터 새로운 데이터를 요청하여 받아옵니다.
Query Func | 비동기적 서버 페칭함수로 데이터를 서버로 부터 가져오는 함수
쿼리 함수는 Promise을 반환하는 모든 함수일 수 있습니다. 반환된 Promise는 데이터를 해결(resolve)하거나 오류를 발생시켜야(throw error) 합니다.
선언적 데이터 패칭
리액트 쿼리는 데이터 패칭을 선언적으로 처리합니다. 컴포넌트에서 데이터를 가져오기 위해 useQuery 훅을 사용하면, 리액트 쿼리가 데이터 로딩, 에러 처리, 캐싱 등을 자동으로 관리합니다. 이를 통해 코드의 가독성과 유지보수성을 높일 수 있습니다.
자동 캐싱 및 동기화 | 서버에서 가져온 데이터 자동 캐싱 및, 캐시된 데이터와 서버 데이터 동기화
리액트 쿼리는 서버에서 가져온 데이터를 자동으로 캐싱하고, 캐시된 데이터와 서버 데이터를 동기화합니다. 이를 통해 불필요한 네트워크 요청을 줄이고 애플리케이션 성능을 최적화할 수 있습니다. Query Key를 사용하여 캐시된 데이터를 고유하게 식별하고 관리합니다.
쿼리 무효화와 재요청
리액트 쿼리는 쿼리 무효화 기능을 통해 특정 조건이 만족될 때 캐시된 데이터를 무효화하고, 최신 데이터를 다시 가져올 수 있습니다. useQueryClient 훅을 사용하여 쿼리를 무효화하거나 재요청할 수 있습니다.
서버 상태 관리
리액트 쿼리는 클라이언트 상태와는 별도로 서버 상태를 관리합니다. 서버 상태는 서버에서 데이터를 가져와 클라이언트에서 사용하는 데이터를 의미합니다. 리액트 쿼리는 서버 상태를 효율적으로 관리하고, 서버와 클라이언트 간의 데이터 동기화를 간편하게 처리할 수 있습니다.
Hydration 지원
리액트 쿼리는 서버 사이드 렌더링(SSR)과 정적 사이트 생성(SSG)을 지원하는 Hydration 기능을 제공합니다. 초기 데이터를 서버에서 가져와 클라이언트로 전달하고, 클라이언트에서 이를 재사용하여 초기 로딩 성능을 개선할 수 있습니다.
글로벌 설정과 QueryClient
내용: 리액트 쿼리는 전역 설정과 QueryClient를 통해 쿼리 동작을 커스터마이징할 수 있습니다. QueryClient를 사용하여 기본 설정을 정의하고, 전역적으로 쿼리와 뮤테이션의 동작 방식을 제어할 수 있습니다.
타입스크립트 관련 개념
인덱스 시그니쳐 | 객체의 프로퍼티가 사전 정의되지 않은 경우 동적으로 프로퍼티를 추가 시 적용하는 방법
객체 리터럴
아래 예시에 따르면 객체에 접근 시 key 의 경우는 string 타입이고, 접근하는 값(value)의 타입은 number 임을 명시하고 있습니다.
interface MyObject {
[key: string]: number;
}
let obj: MyObject = { a: 1, b: 2, c: 3 };
let valueA: number = obj['a']; // 속성 'a'에 접근
이 경우 obj['a'] 에서 키에 해당하는 a 는 string 타입이고, 그에 접근하는 1 이라는 값은 number 타입임을 알 수 있습니다.
유니온 타입을 사용 시
추가로 유니온 타입을 사용하여, 여러 타입의 값에 인덱싱하도록 처리할 수도 있습니다.
interface MyObject {
[key: string]: number | string;
}
let obj: MyObject = { a: 1, b: 'two', c: 3 };
let valueA: number | string = obj['a']; // 속성 'a'에 접근
타입(Type) | 변수, 매개변수, 함수의 반환값 등의 데이터의 형태를 나타내는 것
변수, 매개변수, 함수의 반환값 등의 데이터의 형태를 나타내는 것으로, 변수에 할당되는 값의 종류를 의미합니다. TypeScript에서는 변수와 함수에 대한 타입을 명시할 수 있습니다.
let age: number = 30;
인터페이스(Interface) | 객체의 구조(속성 및 메서드)를 정의하는 방법으로, 객체가 반드시 가져야 하는 속성과 메서드를 명시하여 구조를 정의
객체의 구조(속성 및 메서드)를 정의하는 방법으로, 객체가 반드시 가져야 하는 속성과 메서드를 명시하여 구조를 정의합니다. 타입스크립트에서 재사용 가능한 코드를 작성하고 코드의 가독성을 높이기 위해 인터페이스를 사용합니다.
interface Person {
name: string;
age: number;
greet: () => void;
}
제네릭(Generic) | 타입 또는 함수를 정의할 때 타입을 매개변수로 사용하는 방법
타입 또는 함수를 정의할 때 타입을 매개변수로 사용하는 방법으로, 재사용 가능한 코드를 작성할 때 타입에 관한 유연성을 제공합니다.
function identity<T>(arg: T): T {
return arg;
}
타입 별칭(Type Alias) | 기존 타입에 대한 별칭을 지정하는 것
기존 타입에 대한 별칭을 지정하는 것으로, 복잡한 타입을 간단하게 표현하거나 유지보수성을 높이기 위해 사용됩니다.
type Coordinates = [number, number];
타입 가드(Type Guard) | 런타임에 어떤 타입이 사용되는지를 체크하여 해당 타입에 맞는 코드 블록을 실행하는 방법
런타임에 어떤 타입이 사용되는지를 체크하여 해당 타입에 맞는 코드 블록을 실행하는 방법으로, 타입 안전성을 확보하기 위해 사용됩니다.
function isNumber(value: any): value is number {
return typeof value === 'number';
}
여기서 value is number 는 타입 가드 시에 조건문이 true 인 경우 value 의 타입이 number 임을 타입스크립트 컴파일러에 알려주는 역할을 합니다.
타입 추론(Type Inference) | TypeScript 컴파일러가 코드를 분석하여 변수 또는 함수의 타입을 추론하는 기능
TypeScript 컴파일러가 코드를 분석하여 변수 또는 함수의 타입을 추론하는 기능으로, 타입을 명시하지 않아도 TypeScript가 코드를 이해하고 타입을 추론할 수 있습니다.
let name = "John"; (name 변수의 타입은 자동으로 문자열로 추론됨)
타입 단언(Type Assertion) | 개발자가 컴파일러에게 변수의 타입을 강제로 지정하는 것
개발자가 컴파일러에게 변수의 타입을 강제로 지정하는 것으로, 컴파일러가 변수의 타입을 추론하지 못할 때 사용됩니다.
let value: any = "hello"; let length = (value as string).length;
타입 단언은 any 타입과 마찬가지로 너무 남용하게 되면 타입스크립트 정적 타이핑의 이점을 살리지 못하고, 컴파일이 예기치 못한 문제를 발생시킬 수 있으므로 이를 염두에 두고 해당 타입을 확신할 수 있는 경우에만 사용해야 합니다.
조건부 타입
자바스크립트의 삼항연산식은 조건에 따라 값을 반환합니다. 반면 타입스크립트에서 조건부 타입은 삼항연산자와 동일한 형태이지만, 값이 아닌 타입을 반환합니다.
// T 가 string 타입의 부분 집합이라면 string[], 그게 아니면 number[]
type T1<T> = T extends string ? string[] : number[]
const arr:T1<string> = ["5","2"];
위 예시에 따른다면, T 라는 제네릭 타입이 string 타입의 부분집합이라면 string[] 을 반환하고, 아니면 number[] 타입을 반환하도록 하고 있습니다. 즉, 현재 arr 에 할당된 값은 문자형의 배열이므로 string의 부분집합이기 때문에, string[] 타입으로추론됩니다.
배열 요소의 타입 추출
여기서 infer 는 조건부 타입과 함께 사용되는데, 타입 정보를 추론하는데 도움을 주는 키워드 입니다.
type ElementType<T> = T extends (infer U)[] ? U : T;
type Str = ElementType<string[]>; // string
type Num = ElementType<number[]>; // number
Mapped Types | 기존 타입을 변형하여 새로운 타입을 생성한다.
다른 타입을 기반으로 새로운 타입을 만드는 방법입니다. 또한 효과적으로 타입을 변환할 수 있습니다.
// 매핑된 타입은 다른 타입을 기반으로 새로운 타입을 만드는 방법입니다. 또한 효과적으로 타입을 변환할 수 있습니다.
// 매핑된 타입을 사용하는 일반적인 케이스는 기존 타입의 부분적인 하위집합을 다루는 것입니다.
// 예를 들어 다음 API는 Artist를 반환할 수 있습니다:
interface Artist {
id: number;
name: string;
bio: string;
}
// 그러나, Artist의 하위집합만 변경하기 위해 API를 수정해야 한다면
// 일반적으로 타입을 추가로 만들어야 했습니다.
interface ArtistForEdit {
id: number;
name?: string;
bio?: string;
}
// 위에 Artist 타입과 같지 않을 수도 있습니다. 매핑된 타입은 기존 타입에서
// 변화를 만들어 낼 수 있습니다.
type MyPartialType<Type> = {
// 모든 기존 타입의 키에 해당하는 프로퍼티에 대해서 Type의 타입 내부는 ?: 버전으로 변환합니다
[Property in keyof Type]?: Type[Property];
};
// 이제 수정하는 인터페이스를 추가로 만드는 대신에 매핑된 타입을 사용할 수 있습니다:
type MappedArtistForEdit = MyPartialType<Artist>;
// 완벽해 보이지만, id 값이 null 이 되는 상황을 방지할 수 없습니다.
// 그래서 교차 타입을 사용하여 빠르게 하나를 개선해 봅시다.
// (예시를 살펴보세요:union-and-intersection-types)
type MyPartialTypeForEdit<Type> = {
[Property in keyof Type]?: Type[Property];
} & { id: number };
// 매핑된 타입의 부분적인 결과를 가지며 id: number set를 가진 객체와 병합합니다.
// 효과적으로 id를 강제로 타입 안에 넣어줍니다.
type CorrectMappedArtistForEdit = MyPartialTypeForEdit<Artist>;
// 매핑된 타입이 어떻게 동작하는지에 대한 매우 간단한 예시입니다만, 기초 대부분을 다룹니다.
// 더 깊게 살펴보고 싶다면, 핸드북을 참고하세요:
//
// https://www.typescriptlang.org/docs/handbook/advanced-types.html#mapped-types
as const | 변수 또는 표현식의 타입을 리터럴 타입으로 강제 변환 시 사용
| https://highjoon-dev.vercel.app/blogs/8-effective-react-query-keys |
as const 키워드에 대한 상세 설명
as const 키워드는 타입스크립트에서 변수 또는 표현식의 타입을 리터럴 타입으로 강제 변환하는 데 사용됩니다. 즉, 변수의 값이 변경되지 않고 현재 값 그대로 유지된다는 것을 컴파일러에게 명시적으로 알려주는 역할을 합니다
왜 as const를 사용해야 할까요?
- 타입 안정성 향상: 컴파일러가 더 정확한 타입 추론을 수행하여 예기치 않은 오류를 방지할 수 있습니다.
- 코드 가독성 향상: 코드의 의도를 명확하게 드러내어 다른 개발자들이 코드를 이해하기 쉽도록 도와줍니다.
- 불변성 보장: 데이터의 불변성을 강조하여 예상치 못한 값의 변경으로 인한 버그를 줄일 수 있습니다.
as const 사용 예시
let person = { name: 'Alice', age: 30 };
// as const를 사용하여 리터럴 타입으로 변환
const personConst = person as const;
// personConst.name = 'Bob'; // 오류: 읽기 전용 속성입니다.
// personConst.age = 31; // 오류: 읽기 전용 속성입니다.
// 배열도 마찬가지로 리터럴 타입으로 변환 가능
const numbers = [1, 2, 3] as const;
// numbers.push(4); // 오류: 읽기 전용 배열입니다.NextJS
서버 렌더링의 이점(24.08.12 add)
데이터 페칭 | 데이터를 서버에서 페칭하므로 데이터 조회 속도가 빠르고, 클라이언트 요청 횟수 감소
Server Components를 사용하면 데이터 소스에 더 가까운 서버에서 데이터 페칭을 수행할 수 있습니다. 이는 렌더링에 필요한 데이터를 가져오는 시간을 줄이고 클라이언트에서 요청해야 하는 횟수를 줄여 성능을 향상시킬 수 있습니다.
보안 | 민감한 데이터를 서버에서 처리하므로 클라이언트 노출 방지
Server Components를 사용하면 토큰이나 API 키와 같은 민감한 데이터와 로직을 클라이언트에 노출될 위험 없이 서버에 유지할 수 있습니다.
캐싱 | 서버에서 렌더링된 결과는 CDN 으로 푸시되어 서버와 클라이언트 간 요청과 결과 재사용
서버에서 렌더링함으로써 결과를 캐시하고 이후 요청과 사용자 간에 재사용할 수 있습니다. 이는 각 요청 시 수행되는 렌더링과 데이터 페칭의 양을 줄여 성능을 향상시키고 비용을 절감할 수 있습니다.
성능
Server Components는 성능을 최적화할 수 있는 추가 도구를 제공합니다. 예를 들어, 완전히 Client Components로 구성된 앱에서 비인터랙티브 UI 부분을 Server Components로 이동하면 클라이언트 측 JavaScript의 양을 줄일 수 있습니다. 이는 느린 인터넷 또는 성능이 낮은 장치를 사용하는 사용자에게 유리합니다.
초기 페이지 로드 및 First Contentful Paint (FCP)(opens in a new tab)
서버에서 HTML을 생성하여 사용자가 페이지를 즉시 볼 수 있게 하고, 클라이언트가 페이지를 렌더링하는 데 필요한 JavaScript를 다운로드, 파싱 및 실행할 필요가 없습니다.
검색 엔진 최적화 및 소셜 네트워크 공유 가능성
렌더링된 HTML은 검색 엔진 봇이 페이지를 인덱싱하고 소셜 네트워크 봇이 페이지의 소셜 카드 미리보기를 생성하는 데 사용할 수 있습니다.
스트리밍
Server Components를 사용하면 렌더링 작업을 청크로 분할하고 준비되는 대로 클라이언트에 스트리밍할 수 있습니다. 이를 통해 전체 페이지가 서버에서 렌더링될 때까지 기다리지 않고도 사용자가 페이지의 일부를 먼저 볼 수 있습니다.
데이터 페치 시 중복 요청 캐싱하기(현재는 카나리 버전에서만 가능)
React Cache 를 이용하면, 중복된 페치 요청을 캐싱처리하여 Layout.tsx 와 page.tsx 에서 두 차례 동일한 GET 요청이 발생하더라도 실제 요청은 한 번만 수행되도록 할 수 있습니다. 예를 들어, getItemFromDb 라는 함수가 존재하고, Fetch 요청을 통해 데이터베이스에 접근하는 함수가 있다고 가정해봅시다. 이 때 해당 함수를 호출하는 로직이 같은 뿌리의 상위와 하위 경로에서 호출되더라도, cache 처리되어 함수가 두 번 호출되더라도 내부적으로 중복 요청을 캐싱처리 후 한 번만 요청을 보낼 수 있습니다.https://react.dev/reference/react/cache
cache – React
The library for web and native user interfaces
react.dev
Fetch 캐싱 취소 방법
cache: 'no-store' 옵션 사용
이 옵션을 사용하면 요청이 캐시되지 않고 항상 새로운 데이터를 가져옵니다.
const freshData = await fetch('https://api.example.com/data', { cache: 'no-store' });
revalidate: 0 설정
revalidate 옵션을 0으로 설정하면 매 요청마다 데이터를 재검증합니다. 이는 사실상 캐싱을 비활성화하는 효과가 있습니다.
const alwaysRevalidatedData = await fetch('https://api.example.com/data', { next: { revalidate: 0 } });
동적 함수 사용
Next.js의 동적 함수를 사용하면 해당 라우트가 동적으로 렌더링되며, 기본적으로 캐싱되지 않습니다.
import { cookies, headers } from 'next/headers'
export default function Page() {
// 이 함수들은 요청 시 실행되며, 캐시되지 않습니다.
const cookieStore = cookies()
const headersList = headers()
// ...
}
동적 라우트 세그먼트 사용
동적 라우트 세그먼트를 사용하면 해당 페이지는 기본적으로 동적으로 렌더링되며 캐시되지 않습니다.
// pages/posts/[id].js
export default function Post({ params }) {
return <div>Post: {params.id}</div>
}useSearchParams 훅 사용 (클라이언트 컴포넌트)
클라이언트 컴포넌트에서 useSearchParams 훅을 사용하면 해당 컴포넌트는 동적으로 렌더링되며 캐시되지 않습니다.
'use client'
import { useSearchParams } from 'next/navigation'
export default function SearchBar() {
const searchParams = useSearchParams()
// ...
}
이러한 방법들을 사용하면 Next.js에서 캐싱을 방지하고 항상 최신 데이터를 가져올 수 있습니다. 단, 캐싱을 비활성화하면 성능에 영향을 줄 수 있으므로, 실제로 필요한 경우에만 사용하는 것이 좋습니다.
revalidatePath | 특정 서버 컴포넌트 재유효화
NextJS 13 버전 이후에 등장한 revalidatePath 는 서버 컴포넌트에서 주로 사용되는 메서드입니다. 해당 메서드를 사용하면, 특정 경로의 캐시를 무효화하고 다시 검증할 수 있습니다. 서버 컴포넌트에서만 동작하는 이유는, 이 메서드가 서버에서 실행되는 빌드 타임 또는 런타임에 페이지나 데이터의 정적 생성 및 재검증을 관리하기 때문입니다.
보통 NextJS 에서 npm run build 를 통해 기본적으로 서버 구성요소에 해당하는 파일들은 정적으로 빌드 됩니다. 따라서 사전 빌드된 페이지들은 캐싱되어 사용자가 해당 주소로 접속하게 되면 보여지게 되는데, 이 때 정적이기 때문에, 새로운 데이터가 추가되더라도 해당 페이지는 아무런 변화가 보이지 않습니다.
여기서 revalidatePath( ) 의 인자로 '/path' 와 같이 특정 경로의 URI 를 전달하면, 해당 메서드가 실행될 때 /path 경로의 정적 페이지는 재유효화(쉽개 말해, 갱신)되어 앞서 추가된 데이터를 포함한 최신 페이지가 보여지게 됩니다.
사용방법
서버 측에서 클라이언트에서 온 요청 중 body 에 담겨져온 path 프로퍼티를 revalidatePath(path) 와 같이 전달해줍니다.
// app/api/revalidate.js
import { NextResponse } from 'next/server';
import { revalidatePath } from 'next/cache';
export async function POST(request) {
const { path } = await request.json();
// 특정 경로를 다시 검증
revalidatePath(path);
return NextResponse.json({ revalidated: true, now: Date.now() });
}
그리고 클라이언트 측에서는 fetch 요청을 통해 재유효화 할 경로 정보를 body 객체에 담아서 요청을 보내줍니다.
// components/TriggerRevalidateButton.js
import { useState } from 'react';
export default function TriggerRevalidateButton() {
const [isRevalidating, setIsRevalidating] = useState(false);
const handleRevalidate = async () => {
setIsRevalidating(true);
await fetch('/api/revalidate', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ path: '/path-to-revalidate' })
});
setIsRevalidating(false);
};
return (
<button onClick={handleRevalidate} disabled={isRevalidating}>
{isRevalidating ? 'Revalidating...' : 'Revalidate'}
</button>
);
}
이렇게 하면, POST 요청을 받은 서버 측에서 이를 처리하여 해당 경로가 새롭게 갱신되어, 사용자는 변화된 상태가 반영된 화면을 볼 수 있게 됩니다.
여기서 정리
클라이언트 컴포넌트에서는 Next.js의 빌드 타임이나 서버에서 발생하는 정적 생성, 데이터 페칭 등의 작업을 직접적으로 제어할 수 없습니다. 클라이언트 컴포넌트는 브라우저에서 실행되기 때문에 이러한 서버 사이드 기능을 직접 사용할 수 없으며, 대신 서버와의 통신을 통해 간접적으로 제어할 수 있습니다.
NextJS의 컴파일러 | SWC, Turbopack
SWC 는 바벨을 대체하는 트렌스 파일러 역할을 수행합니다. Rust 로 작성이 되었고(2024.07.03), 홈페이지를 확인해보니 자체적인 번들링 기능도 추가할 예정인 것 같네요. 터보팩을 사용하면 될 것 같은데, 서로 다른 팀이라 그런지 방향성이 다른가 봅니다.
Bundling (swcpack) – SWC
Bundling (swcpack) SWC is able to bundle multiple JavaScript or TypeScript files into one. This feature is currently named spack, but will be renamed to swcpack in v2. spack.config.js will be deprecated for swcpack.config.js. View a basic example of bundli
swc.rs
아래는 터보팩 공식 사이트입니다.
Getting started
Start building web applications with Turbopack.
turbo.build
loading.js
내부적으로 Suspense 컴포넌트를 사용하여 즉각적인 로딩 상태를 표시할 떄 사용하는 컴포넌트 입니다.
리액트 쿼리 관련 개념
stale Time | 데이터가 오래된 데이터로 취급될 때 까지 걸리는 시간
쿼리가 신선한 상태에서 신선하지 않은 상태로 변할 때 까지의 소요 시간입니다. 쿼리가 신선한 데이터는 항상 캐시에서 불러와질 것입니다. 네트워크 요청은 일어나지 않습니다! 만약 쿼리가 신선하지 않다면 (기본값이 항상으로 지정되어있는) 데이터는 여전히 캐시에서 불러오겠지만 특정 조건에 의해 백그라운드에서 다시 불러와질 것입니다.
gc Time | 비활성 쿼리가 캐시로 부터 제거되기 까지 소요 시간(ex. 5분이면 5분 뒤에 제거)
비활성화된 쿼리가 캐시로부터 제거되기까지의 소요 시간입니다. 기본값은 5분 입니다. 쿼리는 등록된 옵저버가 더이상 없을때 즉, 해당 쿼리를 사용하는 모든 컴포넌트가 언마운트되면 비활성화 상태로 전환됩니다.
쿼리 키 팩토리
// query-key-factory
const todoKeys = {
all: ['todos'] as const,
lists: () => [...todoKeys.all, 'list'] as const,
list: (filters: string) => [...todoKeys.lists(), { filters }] as const,
details: () => [...todoKeys.all, 'detail'] as const,
detail: (id: number) => [...todoKeys.details(), id] as const,
};
// examples
// 🕺 할 일 기능과 관련된 모든 것을 제거합니다
queryClient.removeQueries({
queryKey: todoKeys.all,
});
// 🚀 모든 목록을 무효화합니다
queryClient.invalidateQueries({
queryKey: todoKeys.lists(),
});
// 🙌 하나의 할 일을 미리 불러옵니다
queryClient.prefetchQueries({
queryKey: todoKeys.detail(id),
queryFn: () => fetchTodo(id),
});
stale-while-revalidate 전략 | HTTP 캐싱 전략의 하나로, 캐시된 콘텐츠를 사용자에게 즉시 제공하면서 백그라운드에서 새로운 데이터를 가져와 캐시를 업데이트하는 방식
stale-while-revalidate는 HTTP 캐싱 전략의 하나로, 캐시된 콘텐츠를 사용자에게 즉시 제공하면서 백그라운드에서 새로운 데이터를 가져와 캐시를 업데이트하는 방식입니다. 이를 통해 빠른 응답과 최신 데이터 제공을 동시에 달성할 수 있습니다.
이 전략은 HTTP 헤더의 Cache-Control에 설정되며, 다음과 같은 두 가지 주요 속성을 포함합니다:
max-age: 콘텐츠가 캐시에서 유효한 상태로 유지되는 기간(초)을 설정합니다.
stale-while-revalidate: max-age가 지난 후, 캐시된 콘텐츠를 "stale(오래된)" 상태로 간주하면서도 이를 사용자에게 제공하고, 동시에 새로운 데이터를 가져와 캐시를 갱신하는 기간(초)을 설정합니다.
Cache-Control: max-age=600, stale-while-revalidate=30
- max-age=600: 캐시된 콘텐츠는 600초(10분) 동안 유효합니다.
- stale-while-revalidate=30: 10분이 지난 후 30초 동안 캐시된 오래된 콘텐츠를 제공하면서 백그라운드에서 새로운 데이터를 가져와 캐시를 업데이트합니다.
동작 방식
ⓐ 캐시가 유효할 때
요청이 들어오면 캐시된 콘텐츠가 max-age 로 지정한 시간 내에 저장되어 있으면, 해당 데이터를 그대로 제공됩니다.
ⓑ 캐시가 만료되었을 때 (max-age 초과)
- 요청이 들어오면 max-age 시간은 초과했으나, 캐시된 콘텐츠가 stale-while-revalidate 기간 내 동안 존재하는 경우에는 우선 캐시된 콘텐츠를 사용자에게 보여주고, 백그라운드에서 새로운 데이터를 가져와 오래된 캐시를 최신 데이터로 갱신합니다.
- 이후에는 요청이 들어오면 업데이트된 캐시 콘텐츠를 제공합니다.
이점
- 빠른 응답 시간: 캐시된 콘텐츠를 즉시 제공하여 사용자에게 빠른 응답을 보장합니다.
- 최신 데이터 제공: 백그라운드에서 최신 데이터를 가져와 캐시를 갱신하여 최신 상태를 유지합니다.
- 네트워크 부하 감소: 캐시를 활용하여 불필요한 네트워크 요청을 줄입니다.
사용 예시
리액트 애플리케이션에서 stale-while-revalidate 전략을 사용할 때, 서비스 워커와 Workbox를 활용하여 구현할 수 있습니다. 참고로 이 예시는 리액트 쿼리에서 적용된 방식하고는 상관이 없습니다. 해당 전략이 어떻게 구현될 수 있는지 이해를 돕기 위한 별도의 예시 입니다.
Workbox를 사용한 구현 예시
Workbox 설치
npm install workbox-cli --global
서비스 워커 설정 파일 작성 (service-worker.js)
import { registerRoute } from 'workbox-routing';
import { StaleWhileRevalidate } from 'workbox-strategies';
import { CacheFirst } from 'workbox-strategies';
import { ExpirationPlugin } from 'workbox-expiration';
// 정적 리소스 캐싱
registerRoute(
({ request }) => request.destination === 'script' || request.destination === 'style' || request.destination === 'image',
new CacheFirst({
cacheName: 'static-resources',
plugins: [
new ExpirationPlugin({
maxAgeSeconds: 60 * 60 * 24 * 30, // 30일 동안 캐시 유지
}),
],
})
);
// API 응답 캐싱
registerRoute(
({ url }) => url.origin === 'https://api.example.com',
new StaleWhileRevalidate({
cacheName: 'api-responses',
plugins: [
new ExpirationPlugin({
maxAgeSeconds: 60 * 10, // 10분 동안 캐시 유지
maxEntries: 50, // 최대 50개의 응답을 캐시
}),
],
})
);
서비스 워커 등록 (index.js)
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('/service-worker.js')
.then(registration => {
console.log('ServiceWorker registration successful with scope: ', registration.scope);
})
.catch(error => {
console.error('ServiceWorker registration failed: ', error);
});
});
}
요약하자면,
stale-while-revalidate는 캐시된 콘텐츠를 즉시 제공하면서 백그라운드에서 새로운 데이터를 가져와 캐시를 업데이트하는 HTTP 캐싱 전략입니다. 이를 통해 빠른 응답 시간과 최신 데이터 제공을 동시에 달성할 수 있습니다. 리액트 애플리케이션에서는 Workbox와 서비스 워커를 활용하여 쉽게 구현할 수 있습니다.
기타
셔뱅(Shebang) | 해시 기호와 느낌표(#!)로 이루어진 문자 시퀸스
해시 기호와 느낌표(#!)로 이루어진 문자 시퀀스로, 스크립트의 맨 처음에 옵니다.
유닉스 계열 운영 체제에서 셔뱅이 있는 스크립트는 프로그램으로서 실행되며, 프로그램 로더가 스크립트의 첫 줄의 나머지 부분을 인터프리터 지시자(interpreter directive)로 구문 분석합니다. 즉, 지정된 인터프리터 프로그램이 대신 실행되어 스크립트의 실행을 시도할 때 처음 사용되었던 경로를 인수로서 넘겨주게 됩니다.
이를테면 스크립트의 경로가 path/to/script이고 다음의 줄로 시작한다면:
#!/bin/sh
프로그램 로더는 프로그램 /bin/sh 를 대신 실행하되 path/to/script를 첫 번째 인수로 넘겨줍니다.
셔뱅 줄은 일반적으로 인터프리터에 의해 무시되는데 그 까닭은 "#" 문자가 수많은 스크립트 언어에서 주석 표시자이기 때문입니다. 스킴처럼 해시 마크를 주석 시작으로 사용하지 않는 일부 언어 인터프리터들은 목적에 맞게 셔뱅 줄을 무시하기도 합니다.
다른 해결 방안으로는 전처리기에 의존하여 스크립트의 나머지 부분이 컴파일러나 인터프리터에 넘겨지기 전에 셔뱅 줄을 제거하거나 평가하게끔 하는 방법입니다. 이를테면 여러 운영 체제에서 프리 파스칼로 작성된 프로그램을 실행할 수 있도록 하는 InstantFPC의 경우가 그러 합니.
멱등성 | 여러 번 반복해도 결과가 처음과 동일한 성질
멱등성(Idempotence)은 주로 수학, 컴퓨터 과학, 논리학 등에서 사용되는 개념으로, 어떤 연산을 여러 번 반복해도 결과가 처음의 결과와 동일한 성질을 말합니다.
수학에서의 멱등성
- 함수: 어떤 함수 ff에 대해, f(f(x))=f(x)f(f(x)) = f(x)가 성립하면 이 함수는 멱등함수입니다. 예를 들어, f(x)=xf(x) = x는 모든 xx에 대해 멱등함수입니다.
- 연산: 어떤 이항 연산 ∗*가 있을 때, a∗a=aa * a = a가 모든 aa에 대해 성립하면 이 연산은 멱등연산입니다. 예를 들어, 집합의 교집합 연산은 멱등성(즉, A∩A=AA \cap A = A)을 가집니다.
컴퓨터 과학에서의 멱등성
- 데이터베이스: 데이터베이스의 트랜잭션에서, 같은 연산을 여러 번 적용해도 데이터베이스의 상태가 변하지 않는 성질을 말합니다. 예를 들어, "사용자의 상태를 활성화"와 같은 연산은 한 번 실행하든 여러 번 실행하든 결과가 동일해야 합니다.
- HTTP 메서드: HTTP 메서드에서 멱등성은 클라이언트가 동일한 요청을 여러 번 보내더라도 서버의 상태가 달라지지 않는 성질을 의미합니다. 예를 들어, GET, PUT, DELETE 메서드는 멱등성을 가지며, POST는 멱등성을 가지지 않습니다.
멱등성은 시스템의 안정성, 신뢰성, 예측 가능성을 높이는 중요한 특성 중 하나입니다.
AWS 클라우드
SES
SES 를 사용하면 Simple Mail Transfer Protocol(SMTP) 이메일 서버를 온프레미스(->개인이 직접 구축한 인프라)에 유지하지 않고도 Amazon SES API 또는 SMTP 인터페이스를 사용하여 고객과 안전하게 소통할 수 있습니다.
아래는 SES의주요 기능에 대한 설명입니다. 참고 해보시길 바랍니다.
| 가상 배달 가능성 관리자 (VDM) |
| - 인사이트 | 이메일 성능에 대한 인사이트를 제공하여, SES 콘솔에서 반송률, 열어본 건수, 클릭 횟수 등 전송 및 참여 데이터를 한 눈에 확인할 수 있습니다. |
| - 권장 사항 | 발신자에게 이메일 배달 가능성 문제를 알리고 SPF, DKIM, DMARC 등의 이메일 인증 구성 검토와 같은 유용한 권장 사항을 제공합니다. |
| - 자동 개선 | SES를 통해 배달 가능성 권장 사항을 자동으로 구현하여 이메일 배달 패턴을 최적화하고 수동 조정 없이 변경 사항을 자동으로 적용할 수 있습니다. |
| 메일 관리자 |
| - 이메일 수신 및 관리 | 외부 이메일 수신을 조직의 이메일 시스템으로 통합하여 제어된 처리 및 라우팅을 가능하게 하여 이메일 수신 관리를 간소화합니다. |
| - 중앙 집중식 이메일 전달 | 가상 이메일 인프라를 통해 모든 이메일 트래픽을 중앙 집중화하여 효율적인 이메일 처리 및 라우팅을 보장합니다. 회사 프로토콜에 맞춰 내부 이메일 통신을 제어하고 관리할 수 있습니다. |
| - 이메일 아카이빙 | 조직의 이메일 통신을 체계적으로 저장, 보호 및 관리하여 법률 및 규정 요구 사항을 준수할 수 있도록 도와줍니다. 이메일을 쉽게 액세스할 수 있는 형식으로 보존하고 인덱싱합니다. |
| - 유연한 이메일 애드온 | 사용자 지정 가능한 솔루션을 통해 이메일 보안 및 규정 준수를 강화하며, 서드 파티 공급업체를 통해 민감한 정보 검색, 아카이빙, 데이터 손실 방지와 같은 도구를 제공합니다. |
참고자료
- 위키백과 | 셔뱅 : https://ko.wikipedia.org/wiki/%EC%85%94%EB%B1%85
- 리액트 공식문서(컴포넌트와 훅은 순수해야 된다): https://react-ko.dev/reference/rules/components-and-hooks-must-be-pure
- OWASP XSS: https://owasp.org/www-community/attacks/xss/
- MDN XSS : https://developer.mozilla.org/ko/docs/Glossary/Cross-site_scripting
'나만의 모음집' 카테고리의 다른 글
| 🔧 링크 저장소 (0) | 2024.10.05 |
|---|---|
| certbot 인증서 관련 명령어 모음집 (0) | 2024.06.09 |
| 리액트의 다양한 활용 팁을 정리하였습니다. 모르셨다면 하나 알아가세요. (0) | 2024.05.20 |
| 자바스크립트 활용 모음집 (0) | 2024.05.18 |
| [모음집] NestJS(with TypeORM + PostgreSQL) 예제 모음집 (1) | 2024.05.17 |