[이전 포스트] 기능 구현 모음집 2
[나만의 명언집 프로젝트] 기능 구현 정리본②
오늘의 명언 [이전글] 기능구현 정리본 ① [나만의 명언집 만들기 프로젝트] 기능 구현 정리본 ① 오늘의 명언 [기능구현] 좋아요 기능 좋아요 로직 - 사용자가 [좋아요] 아이콘 혹은 버튼을 클릭
duklook.tistory.com
오늘의 명언

포스트 목적
NextJS 14.1 버전을 사용하여 나만의 명언집을 만들어 보는 프로젝트 중에 구현한 기능 중 일부를 정리하는 포스트 입니다.
해당 정리본은 총 3개가 존재하며, 해당 포스트는 그중 세 번째 정리본입니다.
이제 포스트 작성 시 ~ 합니다. 체로 작성하려고 하지만, 현재 포스트는 이전까지 작성한 포스트와의 통일성을 맞추기 위해 ~한다, ~다 와 같은 형식으로 작성합니다.
포스트의 흐름은 개요 -> 구현 -> 마무리 순으로 이어집니다.
[기능구현] 명언 TTS 기능
기능 개요
(기능 목적) 해당 기능은 사용자가 명언을 텍스트로만 보는 경우 불편할 수 있다는 점을 감안하여 편의성을 증진하기 위한 목적으로 구현하고자 하였다.
(도구) 참고로, 해당 기능은 HTML5 에서 소개된 Web Speech API 를 기반으로 구현되었다.
(호환성 검토) 아래 브라우저 호환성을 살펴보면, 파이어폭스만 지원을 안해주는 것으로 나오는데, 실제 파이어폭스 브라우저에 접속하여 테스트 해보니 정상적으로 동작되는 것을 확인하였기에 선택하게 되었다(안드로이드용 파이어폭스는 모르겠는데, 다시 확인해 봐야 겠다).

로직 흐름
(일반적 흐름) 로직 전체의 흐름은 크게 특별할 건 없다. 사용자가 듣기 버튼을 클릭하면, 내부적으로 현재 카드의 텍스트의 TTS 를 생성하는 API 에 넘겨주고, 해당 텍스트를 토대로 합성된 음성이 재생되도록 하면 된다.
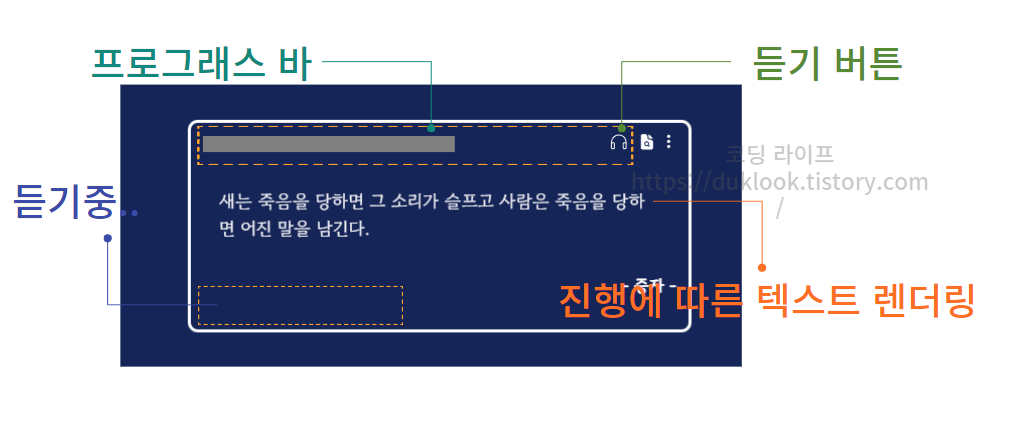
(기타) 현재 구현하는 기능은 사용자가 해당 명언 카드를 쉽게 인지하고, 사용에 불편함이 없도록 프로그래스바와 듣기중이라는 텍스트가 보이도록 하는 편의성 기능을 추가할 것이다. 그리고 기존에 미리 렌더링되어 있던 텍스트가 듣기 버튼을 클릭하는 순간 현재 합성되어 생성된 텍스트가 순차적으로 화면에 보일 수 있도록 기능을 확장하는 부분도 추가된다.
이를 제외한다면, 음성 합성이라는 기능을 구현하는 것 자체는 가져와서 호출만 하면 되는 부분이므로 까다롭지는 않다.
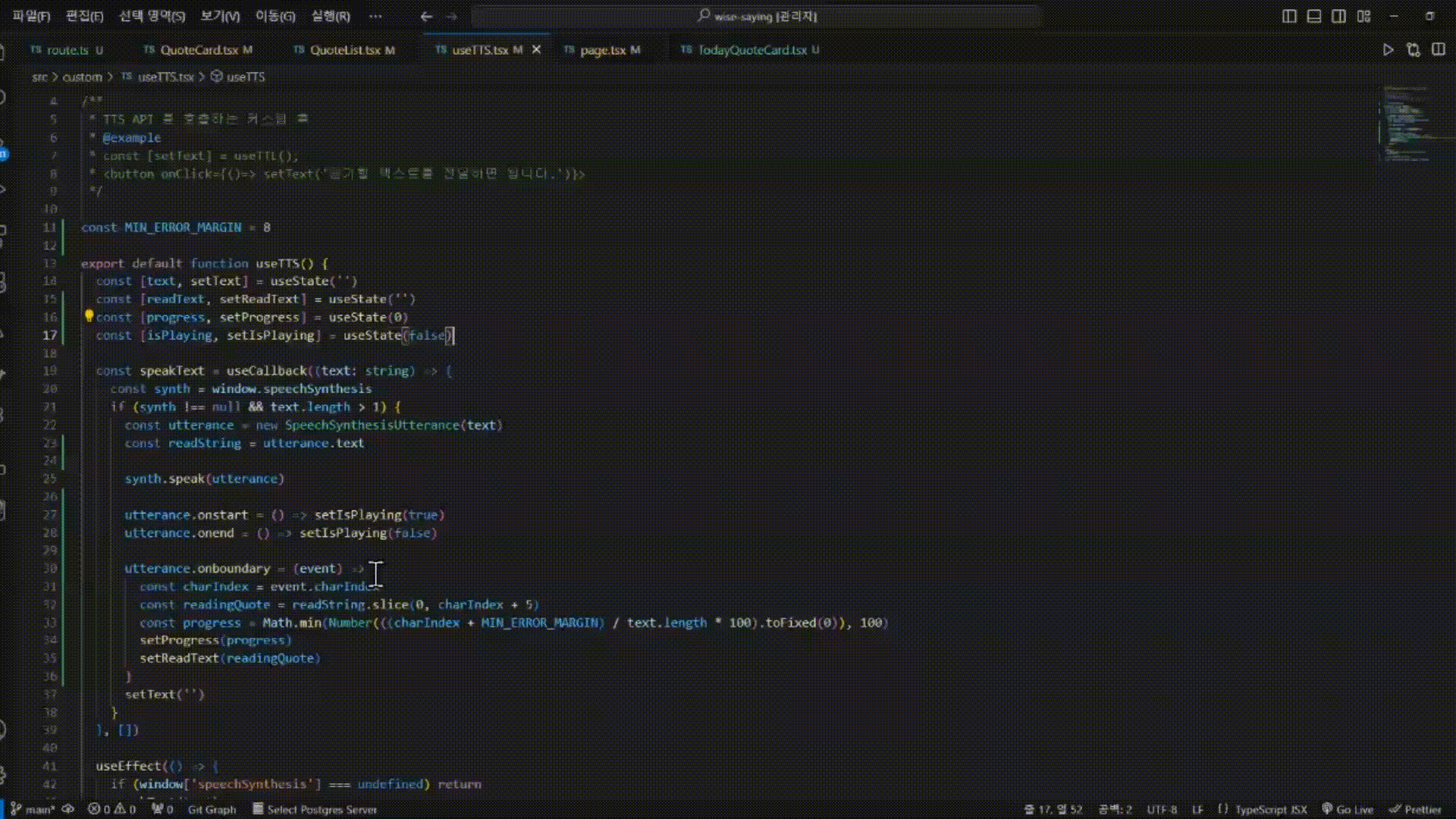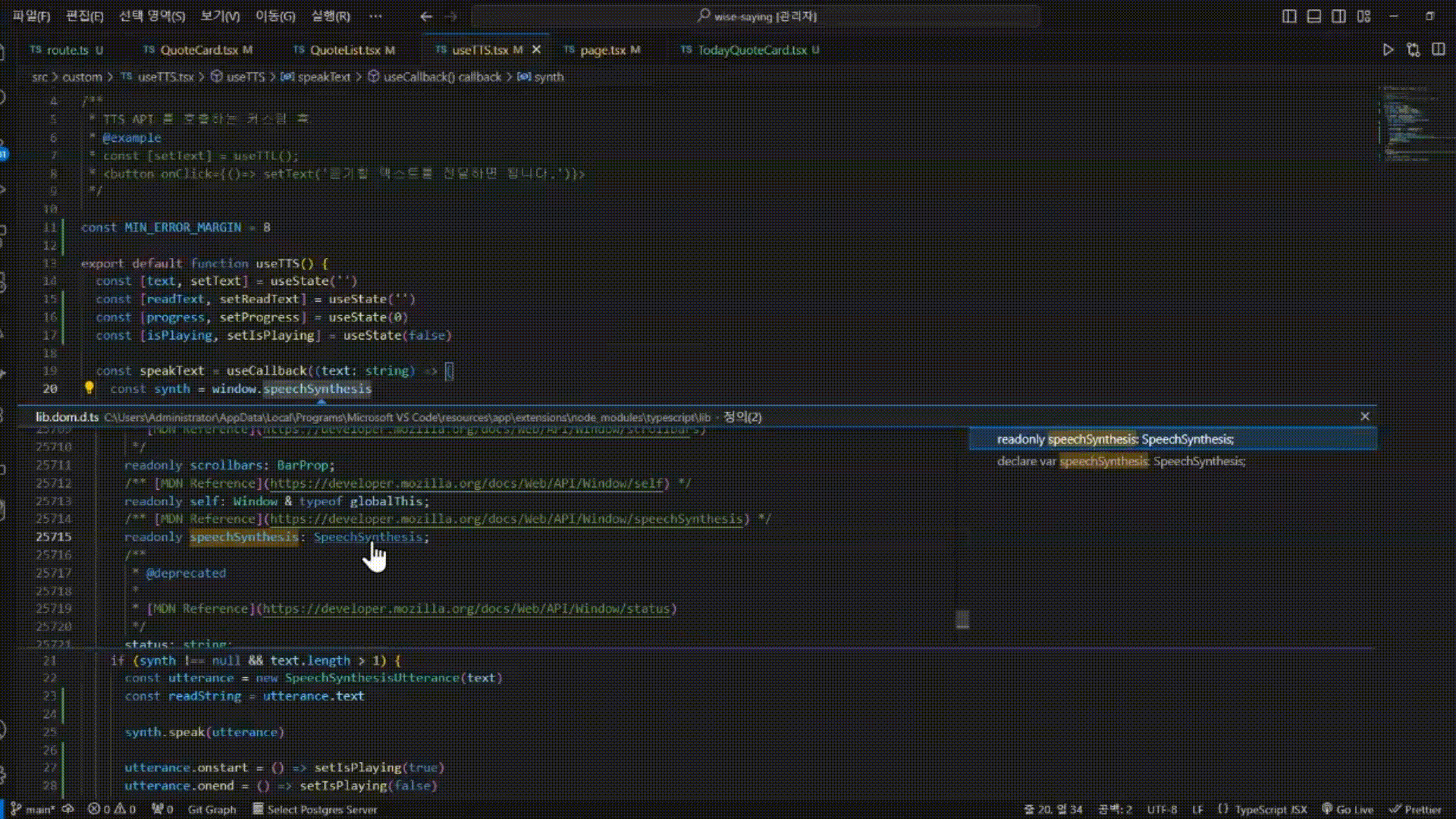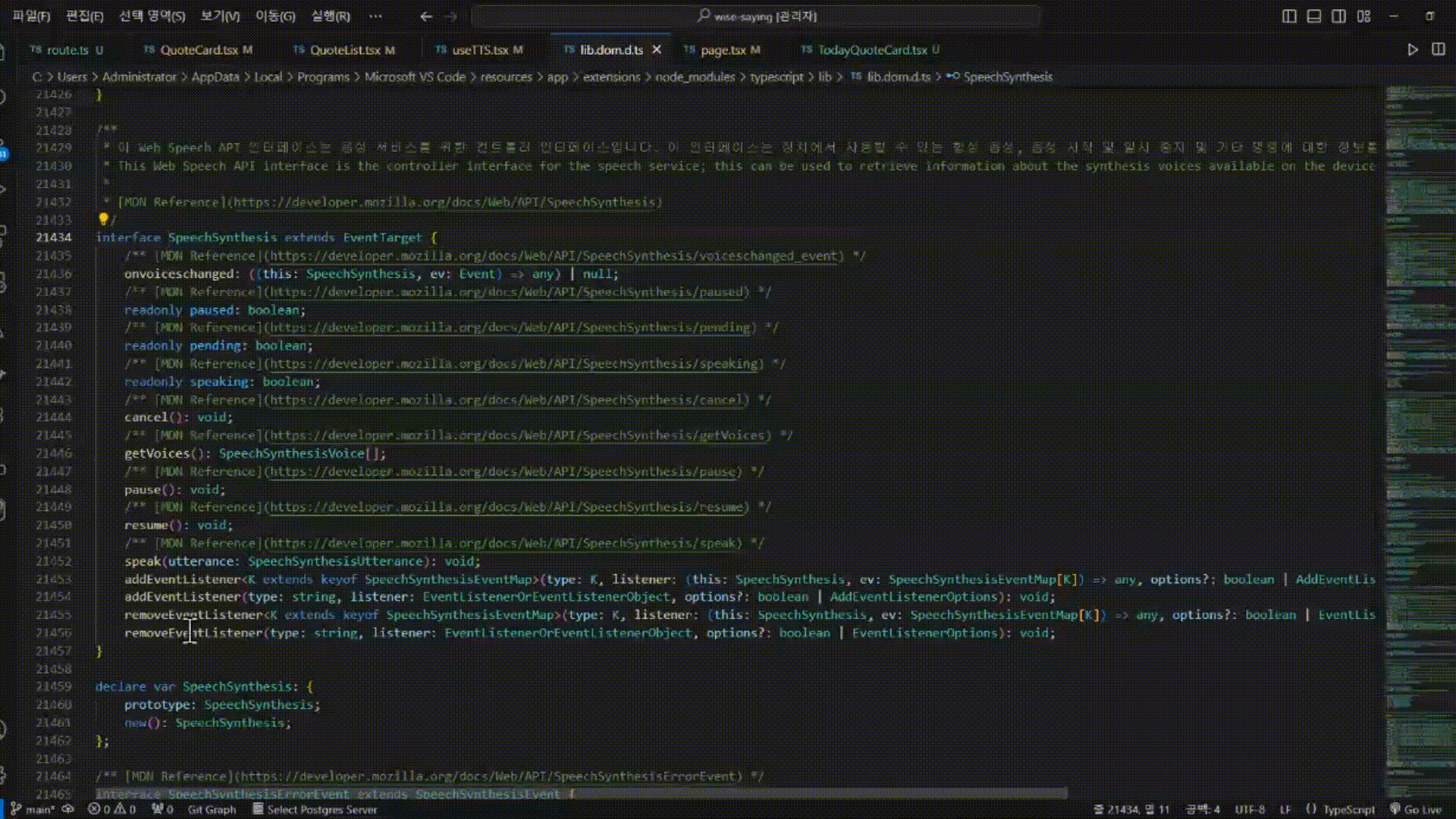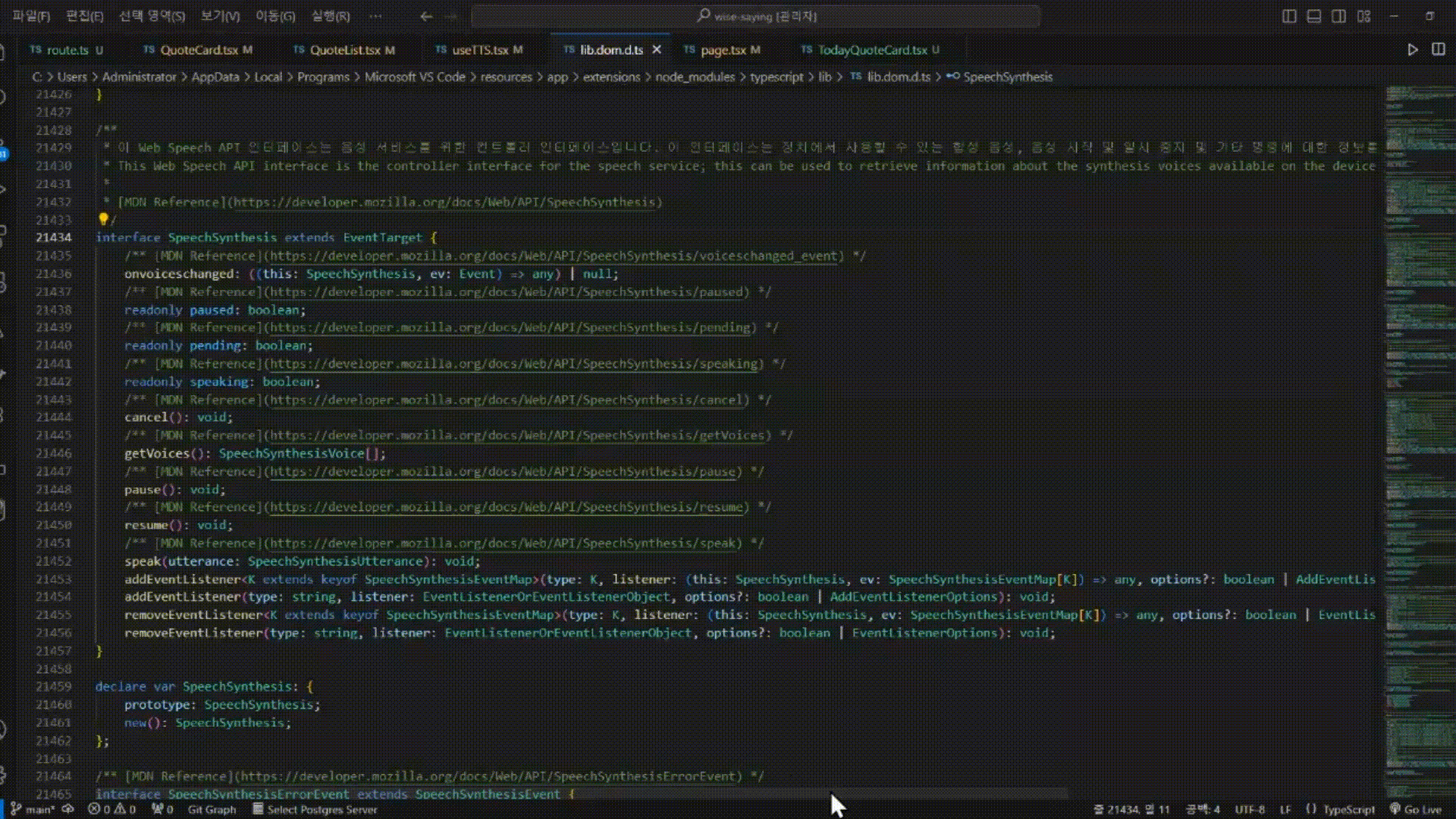
① 구현하기 | window 객체로 부터 speechSynthesis 가져오기
웹 스피치 api 자체는 브라우저에서 제공해주기 때문에 window 객체에서 이를 가져올 수 있다. 따라서 window.speechSynthesis 으로 접근하면 api 의 다양한 도구를 사용할 수 있게 된다.
[참고] window.speechSynthesis 내부로 파고 들기
아래 GIF 가 잘 보일지는 모르겠지만, 아래와 같이 경로를 타고 들어가보면 다양한 기능을 가지고 있음을 확인해볼 수 있다. 심지어 어떤 개발자분은 이를 한글로 정리해서 주석으로 달라 주셔서 해당 타입이 뭘 의미하는지 쉽게 이해할 수 있다.
주의할 점은 NextJS 와 같은 프레임워크에서 이를 사용하려면 컴포넌트가 마운트된 이후에 호출해야 window 객체를 인식하기 때문에, 해당 객체 내에 스피치 객체에 접근하려면 useEffect 훅을 사용해야 한다.
이를 반영하여 기초 토대가 되는 코드를 작성해보면 다음과 같을 것이다.
useEffect(() => {
window.speechSynthesis
}, [])
}
다만, 이렇게 하더라도 window 객체는 존재하지만, 우리가 사용하고자 하는 실제 객체는 undefind가 되는 경우가 있으므로, 이를 방지하기 위해서 이른 반환 로직을 추가로 작성할 필요가 있다.
따라서 이를 다시 반영해서 나타내면 다음과 같아진다.
useEffect(() => {
if (window['speechSynthesis'] === undefined) return
const synth = window.speechSynthesis
}, [])
}
② 구현하기 | SpeechSynthesisUtterance 클래스의 인스턴스 생성하기
그 다음에 불어와야 할 것은 SpeechSynthesisUtterance 이다. 해당 클래스는 입력받은 텍스트를 기반으로 음성합성을 위한 다양한 도구들이 들어있는 거대한 박스와 같은 역할을 한다.
그러므로 해당 클래스를 불러와서 new 키워드를 붙이게 되면 해당 클래스 내부에 접근할 수 있는 인스턴스(객체)를 반환하게 되는데, 그 객체를 참조하는 변수로서 utterance 를 생성하고 할당하는 것 까지가 해당 단계 까지의 로직이다.
const utterance = new SpeechSynthesisUtterance()
[참고] 변수명이 utterance 인 이유
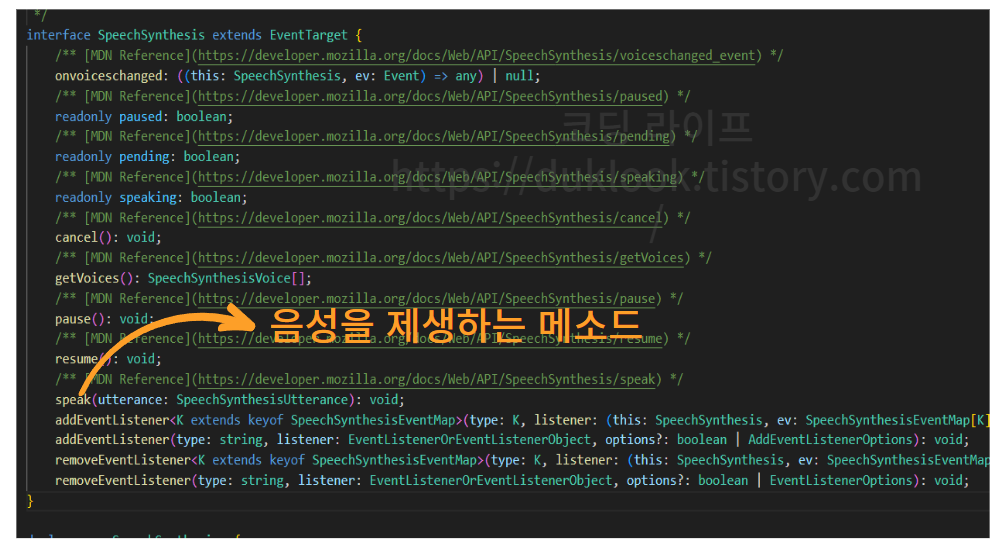
참고로 여기서 변수명이 utterance 인 이유는 단순하다. 앞서 window 객체로 접근했던 speechSynthesis 의 내부로 타고 들어가다 보면 해당 객체가 상속받고 있는 타입을 확인할 수 있는데, 여기서 합성된 음성을 재생하는 메소드의 인자로 전달 받는 변수명이 utterance 이기 때문이다.
③ 구현하기 | new SpeechSynthesisUtterance() 의 인자에 텍스트 전달하기(텍스트를 음성으로 변환하는 단계)
앞서 과정 까지 끝내고 이번에 해야하는 일은 new SpeechSynthesisUtterance() 의 인자에 음성합성에 사용할 텍스트를 전달할 수 있도록 해야 한다.
이렇게 까지해야 해당 텍스트를 기반으로 음성합성이 이루어지고, 해당 음성을 조작하는 다양한 도구를 활용할 수 있다.
const utterance = new SpeechSynthesisUtterance(text)
④ 구현하기 | 합성된 음성 재생하기
합성된 음성을 재생하는 일은 더 간단하다.
앞서 const synth = window.speechSynthesis 와 같이 초기화했던 synth 객체는 다음과 같은 메소드들을 가지고 있다.
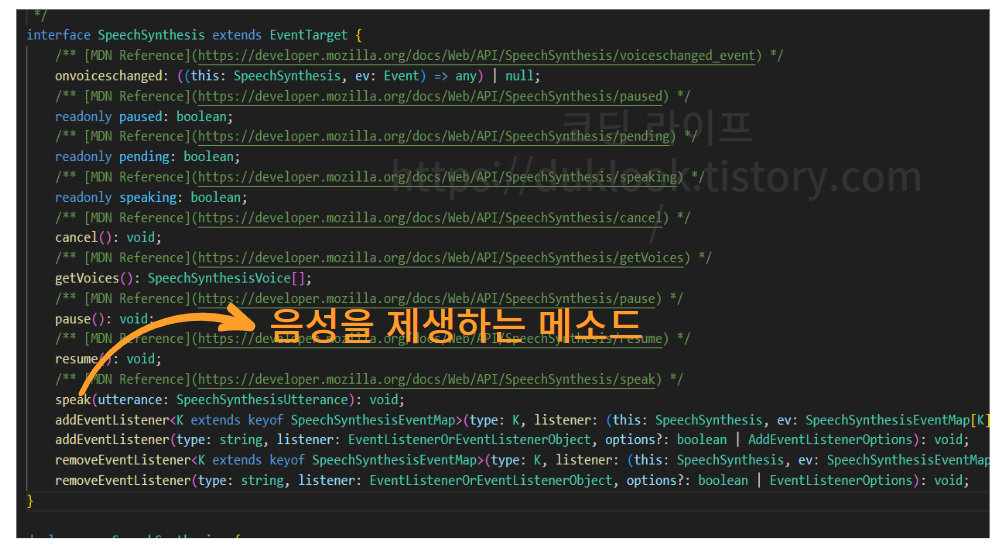
이 중에서 우리가 사용해야 하는 메소드는 speak() 메소드인데, 해당 메소드의 인자로 아까 ③ 번에서 구현했던 const utterance = new SpeechSynthesisUtterance(text) 의 변수를 전달하면, 생성된 음성을 재생해준다.
synth.speak(utterance) // 코드만 보여서 뻘쭘하지만, 음성이 재생된다
여기 까지 하면 텍스트를 음성으로 변환하여 재생하는 기능 구현 자체는 끝났다. 이 다음 부터는 앞서 객체가 가지고 있는 다양한 편의성 메소드와 이벤트를 활용하여 프로그래스바를 구현하고, 추가적으로 현재 재생되고 있는 텍스트의 인덱스를 기반으로 텍스트를 렌더링하는 기능을 구현해볼 것이다.
⑤ 구현하기 | 프로그래스바 구현하기
이번에 구현할 응용 기능은 프로그래스바 구현이다. 여기서 프로그래스바는 사용자가 명언 듣기 아이콘을 클릭하면 재생되는 음성의 시작과 끝을 추적하여 그 진행도를 표시하는 바 UI 를 의마한다.
프로그래스바에 사용한 태그 살펴보기
우선 프로그래스바 구현에 사용할 HTML 태그를 소개해본다.
바로 이 친구이다. 해당 태그는 여러 속성을 가지고 있지만 여기서 사용되는 속성은 max 와 value 이다. max 는 프로그래스 바의 최대 비율로 100을 지정하면 0 ~ 100% 까지로 범위를 제한한다. value 은 프로그래스바의 진행도를 나타내는 값으로 만일 50을 입력하면 max가 100 임을 기준으로 본다면 50% 가 된다.
<progress max={100} value={progress} />
참고로 progress 는 기본적으로 구현되어 있는 스타일을 수정하기 매우 까다롭고, 스크린 리더기가 해당 태그의 진행사항 등을 인지하기가 매우 까다롭기 때문에 추가적인 aria 작업을 필수적으로 요한다.
따라서 그냥 기능만 구현했다고 끝나는 것이 아니라 이를 스크린 리더기를 사용하는 사용자의 입장에서 고려하여 기능을 구현해야 한다
프로그래스 기능 구현에 사용 될 웹 스피치 api 의 메소드 살펴보기
그 다음 살펴볼 친구는 프로그래스 기능에 사용될 메소드에 대한 부분이다. 보통 합성된 음성이 재생되는 동안 호출되는 이벤트가 있는데 이를 활용할 것이므로 이에 대해 소개하고자 한다.
바로 onboundary 이벤트 인데, 해당 이벤트는 합성된 음성이 재생되는 동안 계속 호출되므로 이를 이용하면 프로그래스를 계속해서 추적할 수 있다.
utterance.onboundary = (event) => { }
위 이벤트를 보면 콜백함수도 정의된 것을 볼 수 있는데, 여기서 콜백함수의 첫 번째 매개변수로 event 객체가 들어온다(
| (참고) 사실 첫 번째 인자에는 this 가 들어오는데 해당 this 는 utterance 를 생성한 클래스 그 자체를 가리킨다. 다만 이를 생략하면 첫 번째 인자로 이벤트 객체가 들어온다 |
해당 이벤트에 마우스를 올려보면 SpeechSynthesisEvent 타입이 지정된 것을 볼 수 있다.

해당 이벤트 객체가 어떤 프로터티와 메소드를 가지고 있는지 확인해보자.
| (개인적인 팁) 요즘에는 타입스크립트로 타입 선인이 잘 되어 있기 때문에, 이렇게 타고들어 가다보면 그냥 구글링과 chatGPT 같은 인공지능을 사용하는 것보다 더 이해 깊은 공부가 가능하므로 개인적으로 추천한다. 특히 MDN 같은 공식 문서가 영어로 되어 있을 때, 번역기로 돌리는 것보다는 직접 영어문장을 번역하면서 하나하나 살펴보면 번역을 돌린 것 보다 더 이해가 잘되는 신기한 현상을 경험할 수도 있다 |
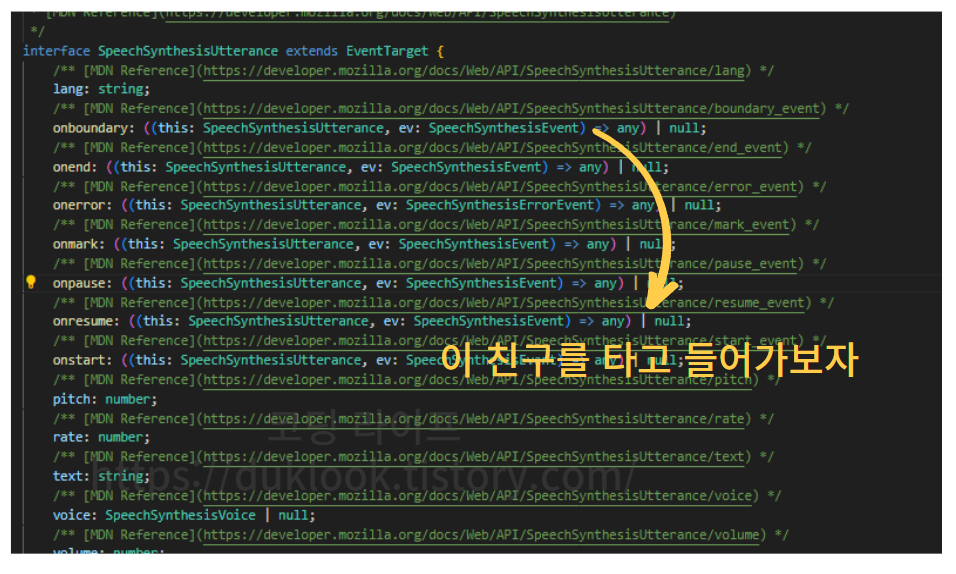
타고 들어가보면, 해당 이벤트 객체가 가지고 있는 프로퍼티들을 확인할 수 있는데, 우리가 프로그래스바를 구현하기 위해 사용할 속성은 charIndex 이다. charIndex 는 재생되는 음성이 텍스트의 어느 위치에 해당하는지 각 음절의 인덱스를 number 타입으로 반환한다.

onboundary 이벤트 호출과 charIndex 가져오기
이제 사용할 도구를 알아봤으니 나머지 기능을 구현해본다. 우선적으로 utterance 객체에 접근하여 onboundary 이벤트를 호출할 수 있도록 로직을 작성한다.
utterance.onboundary = (event) => { }
그 다음 event 객체에 접근하여 charIndex 프로퍼티를 반환받고, 이를 charIndex 변수에 할당한다.
const charIndex = event.charIndex
이렇게 되면 다음과 같은 형태가 될 것이다.
utterance.onboundary = (event) => {
const charIndex = event.charIndex
}
프로그래스 추적 기능 구현
앞서 준비까지 모두 끝냈다면 이들을 이용해서 기능을 구현하기만 하면된다.
프로그래스는 일반적으로 0 ~ 100% 사이의 진행률을 표시할 때 쓰인다, 여기서 기능 구현시 100%의 기준이 되는 값은 음성합성을 위해 전달받은 text 의 길이(text.length)가 된다. 그리고 0 ~ 100% 까지 순차적으로 증가하는 비율이 되는 값이 앞서 구한 charIndex 가 된다.
charIndex / text.length
하지만 이들만 사용해서 charIndex/text.length 가 된다면 0.2 와 같이 소숫점으로 나타나기 때문에 이를 백분률로 나타내기 위해 100을 추가적으로 곱해주어야 한다.
charIndex / text.length *100
이 때, 100을 곱하게 되면, 35.2331 와 같이 무한정 소수점 이하의 자리가 길어지기 때문에 이를 일정한 위치에서 컷해주어야 하는데, 이 때 사용하는 메서드가 .toFixed() 메소드이다. 이 메소드는 전달받은 숫자 만큼 소수점을 자르는 기능을 수행한다. 우리는 여기서 0 을 전달하여 소수점 전체를 모두 버릴 것이다.
(charIndex / text.length * 100).toFixed(0)
즉, 결과적으로 위 로직을 반영한 최종적인 값은 0 → 50 → 100 이런 흐름의 값이 될 것이다.
여기 까지 구현한 이후에서 제일 주요한 사항이 있다. charIndex 는 음성합성된 텍스트의 길이와는 완전히 동일하지 않다는 점이다. 따라서 원본 텍스트와 charInde 간에 작으면 3 에서 7 사이의 오차가 존재하므로 이를 자연스럽게 처리할 수 있도록 일정한 상수값을 더해줄 필요가 있다.
따라서 해당 상수는 MIN_ERROR_MARGIN 으로 선언하고, 이에 본인의 경우에는 7을 할당하여 최대한 자연스럽게 음성 진행과 프로그래스바가 끝나는 지점을 맞춰주었다.
const MIN_ERROR_MARGIN = 7
여기서 끝이면 좋겠지만, 더해주는 값만큼 어느 텍스트는 100 %를 벗어나는 문제가 발생할 수 있기 때문에 이를 맞춰 주기 위해서 Math 클래스의 정적 메소드인 min 을 사용하여 최댓값이 100을 넘어가지 못하도록 제한을 두었다.
이 모든 로직 설명을 반영하여 구성한 로직은 다음과 같다.
const progress = Math.min(Number(((charIndex + MIN_ERROR_MARGIN) / text.length * 100).toFixed(0)), 100)
⑥ 구현하기 | 실시간 렌더링 텍스트 구현하기
이번에는 음성이 재생되는 구간에 따라 텍스트가 렌더링되는 기능을 구현해볼 것이다. 이 기능은 말그대로 합성된 음성이 재생될 때, 재생되는 구간에 맞춰 텍스트가 화면에 렌더링되도록 한다.
이 부분은 앞서 구현한 부분에서 하나의 로직만 추가하면 간단하게 구현할 수 있다.
다만 그전에 사용할 값을 담은 변수를 만들어야 하는데, 다음과 같이 readString 변수를 선언하고 utterance.text 의 값을 할당하면 된다. 여기서 .text 는 우리가 음성합성을 위해 전달한 그 text 가 맞다. 다만 이렇게 다시 변수를 선언한 이유는 개인적으로 코드 가독성 문제 때문이다.
const utterance = new SpeechSynthesisUtterance(text)
const readString = utterance.text
그 다음에는 앞서 onboundary 내부 에서 아래 와 같이 readString 을 slice 로 분절하기만 하면되는데, 이 때 end 가 되는 지점에 charIndex 를 넣어주어야 한다.
charIndex 는 앞서 언급했듯이 합성된 음성을 재생 시 어느 위치의 텍스트를 읽고 있는지 추적하기 위해 인덱스를 반환해주므로 이를 end 지점에 넣어 주기만 하면 알아서 텍스트의 0 인덱스 부터 끝 인덱스 까지 텍스트를 렌더링 해준다.
const readingQuote = readString.slice(0, charIndex + 5)
위 로직에서 5을 더해 준 이유는 앞서 상수로 초기화 했던 MIN_ERROR_MARGIN 과 같은 이유이며 해당 값을 이 상수로 바꿔주어도 무방하다.
이렇게 하면 모든 기능 구현이 끝났다. 위에서 생성한 값들을 이제 자신의 상황에 맞게 커스텀 훅으로 만들어서 재사용하든, 하면 되는 부분이다.
구현 결과(시연)
모든 기능을 구현하고 프로젝트에 반영해보면 다음과 같이 실행된다. 응용하기에 따라서는 기존 텍스트를 새로운 텍스트를 대체하지 않고, 기존 텍스트를 분절하고, 각 분절된 텍스트가 렌더링 될 때 마다 연한 색상에서 진한 색상으로 바뀌게 하던지
아니면 흔히 PDF 도서에서 볼 수 있는 TTS 서비스와 같이 읽는 지점을 마커로 표시하며 지나가게 하는 등의 응용이 가능할 것 같다.
[마무리] 기능 구현을 마무리하면서..
고려하지도 않은 프롭 드릴링이 장애물이 될 줄은 끝에 가서야 알았다
해당 기능을 구현하면서 어려웠던 점 이라기 보다는 혼란스러웠던 점은 존재했다. 사실 위 기능을 처음 구현했을 초창기 버전은 저렇게 프로그래스로 추적하거나 진행률이 텍스트로 표시되는 것이 없었고, 그저 전달 받은 음성을 재생하는 기능만 있었다.
그 이유는 해당 기능 구현 초기에는 TTS 를 호출하는 기능이 텍스트를 렌더링하는 컴포넌트와는 거리가 멀었기에 이를 이어주려면 전역 상태를 관리했어야 했다.
이에 전역상태를 고려하여 수정한 결과 계획했던 것과는 다르게 동작(리렌더링이 무수히 일어나면서 텍스트가 이상하게 렌더링되는 문제 등) 하는 문제가 생겨서 결국에는 잠시 보류 했었다.
하지만, 이 기능을 꼭 완성해보고 싶었기 때문에, 컴포넌트 간의 드롭 드릴링 문제를 해결하고자 틈틈이 컴포넌트 구조를 변경하는 리팩터링을 꾸준히 진행했었고, 오늘 해당 기능을 마무리할 수 있었다
[기능 구현] AWS SES 와 Redis 를 이용한 본인인증 기능 구현
[나만의 명언집] 이메일 본인인증 기능 구현(With Redis 클라우드 & NextJS 서버리스) -> 핵심만
이번에 구현해볼 기능은 이메일 본인인증 기능이다. 참고로 언어는 NextJS(^14.04) 를 사용하므로 별도의 백엔드 언어를 따로 두지 않는다. 즉, 서버리스이다. 해당 기능은 사실 한참 이전에 구현했
duklook.tistory.com
'프로젝트 > 나만의명언집' 카테고리의 다른 글
| aws ec2에서 npm install 이 실패하였습니다.. 알고 보니 권한 문제였다는데,, 혹시 여러분도?? (0) | 2024.03.17 |
|---|---|
| [나만의명언집] NextJS, Posgres 기반 앱을 EC2에 천천히 배포해보자(with WIndow 10 , PUTTY, PSCP, 아마존 리눅스) (2) | 2024.03.16 |
| [나만의 명언집 배포] NextJS(^14.1) - ② Amplify 배포 | 도메인 설정 (0) | 2024.03.06 |
| [나만의 명언집 배포] NextJS(^14.1) - ① AWS Amplify 배포 (0) | 2024.03.06 |
| [나만의 명언집 프로젝트] 테스트 코드 적용 정리본(일부) (4) | 2024.03.05 |



